Bases de données
Bases de données jppCe chapitre regroupe différents articles sur les bases de données (très connues ou moins connues) :
- Installation
- Usage
- Petits ennuis
- ....
Table de test : description
Table de test : description jppNote 2022 : il faudra que je crée une table plus volumineuse pour faire ce type de tests avec au moins 2 ou 3 millions de rangs, mais en 2010 les disques étaient plus petits, plus chers et nettement moins rapides qu'un SSD moderne.
Pour de très gros tests (par exemple ClickHouse) je dispose d'une bonne grosse table de plus de 600 millions de rangs (#200Go sur disque).
Afin de "tester" un peu le fonctionnement des bases de données avec une table un peu "lourde" qui oblige le moteur à "sortir de ses caches". Le cache des données doit être positionné à une valeur de l'ordre de 256 Mo. J'utilise une table statistique de l'activité des machines virtuelles. Cette table comporte environ 300 000 lignes et est donc très insuffisante en volume.
| create table xen_stat_v2 ( DATEC varchar(10), HEUREC varchar(5), SERVEUR varchar(16), DOMNOM varchar(16), DELTACPU decimal, DELTARX decimal, DELTATX decimal, CPUPCT decimal, NBSECR decimal, NBSECW decimal ) |
La syntaxe du "CREATE TABLE" est à adapter légèrement selon la BDD cible.
Cette table comporte, outre l'heure (HEUREC au format HH:MM), une colonne "DATEC" au format AAAAMMJJLa procédure de "gonflage" consiste donc à :
- Calculer la différence entre les dates (AAAAMMJJ) mini et maxi sur la table permanente
- Créer une nouvelle table de travail avec une date = (date originale) - différence calculée en (1) par un select sur la table originale.
- Insérer cette nouvelle table dans la table originale
- Et on recommence autant de fois qu'il faut pour dépasser les 13 millions de lignes. Là aussi la syntaxe est à adapter selon la base cible ...
Les opérations mesurées ensuite sont :
La création de deux index :
create index xen_stat_v2_i1 on xen_stat_v2 (DOMNOM, DATEC, HEUREC)
create index xen_stat_v2_i2 on xen_stat_v2 (DATEC, DOMNOM, HEUREC)
Le calcul des statistiques sur cette table :
Lancement de quelques "select" donnant des totaux avec un group by / order by :
|
select count(*) select DOMNOM,count(*) select DOMNOM,SERVEUR,count(*) |
Ces quelques opérations donnent simplement un petit avant-goût de la performance globale.
Petits ennuis
Petits ennuis jppUn petit chapitre sur quelques "ennuis".
MariaDB binlog non supprimés !
MariaDB binlog non supprimés ! jppUn petit ennui : les fichiers "binlog" ne sont plus supprimés malgré la présence du paramètre adéquat : expire_logs_days = 3
Ce phénomène m'a été montré par l'augmentation anormale de la taille de la partition qui supporte ces fichiers et son approche des 100% fatidiques.
Après quelques recherches sur Internet je ne trouve rien à ce sujet.
J'essaye de purger ces fichus binlog avec la commande "purge binlog until '2022-06-14' " ou "purge binlog to '0000xxxxxxxxxx' ".
Ces commandes me répondent invariablement "fichier log non trouvé dans l'index" .... ???? ....
J'allais me résoudre à une manip hasardeuse de destruction "manuelle avec rm ..." et mise à jour du fichier d'index, lorsque j'ai remarqué que le fichier index, "mysql-binlog.index" chez moi, comportait une ligne blanche en tête.
Je stoppe MariaDB et supprime cette fichue ligne "blanche" et, miracle, lors du redémarrage de MariaDB tous les vieux binlog disparaissent en respectant bien la limite à trois jours et la partition revient à un pourcentage et un nombre de fichiers bien plus sympathique.
Depuis 2 jours tout est normal et aucun fichier ne date de plus de 3 jours .... le problème semble donc réglé.
Mysql se plante inopinément
Mysql se plante inopinément jppJ'ai eu récemment un plantage violent de Mysql suite à une mise à jour d'une Debian 9. Le process Mysql avait une fâcheuse tendance à consommer tout le CPU et manifestait son mécontentement par de nombreux messages, le total fait plus de 4000 lignes, j'en ai extrait les parties les plus typiques :
|
InnoDB: Warning: a long semaphore wait: key_buffer_size=524288 Thread pointer: 0x0 |
J'ai commencé par copier l'intégralité des fichiers de la base sur un autre disque afin de préserver leur état.
Après recherche sur Internet et plusieurs essais de redémarrage infructueux, y compris par l'utilisation de "innodb_force_recovery = 1".
J'ai alors songé à examiner le syslog et j'y ai trouvé de nombreux messages tels que :
| ....apparmor="DENIED" operation="open" profile="/usr/sbin/mysqld" name="/MYSQL_DATA/mysql/" pid=4690 comm="mysqld" requested_mask="r" denied_mask="r" |
Note : chez moi les données de Mysql sont stockées dans une partition spécifique (sur SSD) montée sur /MYSQL_DATA/mysql.
J'ai alors cherché un fichier "usr.sbin.mysqld", vainement, dans /etc/apparmor.d, aucune trace d'un tel fichier !
Je n'ai pas pu trouver l'origine de cette disparition, probablement la dernière mise à jour et j'ai du récupérer ce fichier "usr.sbin.mysqld" et son copain dans "/etc/apparmor.d/local" sur une autre machine et le personnaliser à nouveau car cette base utilise une partition séparée ...
J'ai aussi voulu mettre apparmor en mode "complain" pour mysqld mais je me suis aperçu que le paquet "apparmor-utils" qui contient, entre autres, la fonction "aa-complain" qui permet de gérer cela brillait par son absence, j'ai donc du installer ce paquet pour placer /usr/sbin/mysqld en mode "complain" en attendant d'analyser les données fournies par les logs.
Ensuite Mysql a démarré sans encombres et fonctionne normalement depuis.
En fait les messages de Mysql sont le reflet des erreurs induites par les blocages effectués par Apparmor suite à l'absence (inexpliquée à ce jour d'un fichier de paramétrage de Apparmor) et non dus à un dysfonctionnement de Mysql ou d'un problème système quelconque (librairies, disque ....).
Enfin ce type d'erreur est de plus en plus rare, les "paquets" sont, en général, bien configurés coté "apparmor".
Mysql : refus demarrage
Mysql : refus demarrage jppJuste avant de partir une semaine en congés, j'ai effectué une mise à jour du système qui "supporte", entre autres choses, la machine virtuelle (KVM) de ce site, j'ai eu le malheur de ré-démarrer le machine, petit nettoyage de la mémoire avant de partir ...
Je n'ai pas vérifié que tout se passait bien au redémarrage et, quelques heures après en consultant mes mails j'ai constaté que la base de données de ce système était inaccessible et que certains logiciels ne fonctionnaient plus car ils utilisent cette base Mysql ...
Dans le coin où j'étais en congés les liaisons téléphoniques étaient tellement mauvaises que je n'ai pas pu prendre la main à distance pour étudier ce phénomène. J'ai du attendre le retour pour me pencher sur cet ennui.
Mysql ne se lançait plus et, comme d'habitude, les renseignements fournis par systemd étaient insuffisants pour toute analyse sérieuse : le service a retourné une erreur ... ce n'est pas très informatif sur la nature de l'erreur et donc franchement inutile !
Une erreur c'est bien de le savoir, mais il serait mieux de savoir laquelle en ayant un message sensé aidant à comprendre le pourquoi !
En lançant Mysql "à la main" en tant qu'utilisateur "mysql" (il faut modifier le shell de démarrage dans /etc/password de /bin/false à /bin/bash) j'ai tout de suite eu un message "fichier my.cnf inexistant", ce qui était beaucoup plus clair que "le service a retourné une erreur'. Ne pas oublier de repasser cet utilisateur à "/bin/false" après la manip !
Je me précipite dans /etc/mysql et ... le fichier "my.cnf" est présent sous la forme d'un lien vers /etc/alternatives/my.cnf", or en tentant de le lister j'obtiens un message de fichier inexistant ... et dans /etc/alternatives il existe bien un fichier "my.cnf" mais sous la forme d'un lien vers /etc/mysql/my.cnf !!!
Je crée donc un "vrai" fichier "my.cnf" contenant :
[mysqld]
!includedir /etc/mysql/mysql.conf.d/
Et systemd lance la base de données sans aucun message alarmant, mais je ne saurais jamais comment et par qui ce lien "en boucle" a été mis en place.
Bases à découvrir
Bases à découvrir jppCe groupe d'articles est destiné à présenter des bases de données moins connues que Oracle ou Mysql mais qui possèdent une implantation industrielle assez importante et qui pour certaines existent depuis très longtemps. Nous allons commencer cette petite série par deux bases à l'historique important.
-
Sybase

Base de données fort ancienne qui en est à la version 15. Sybase a donné naissance à un "fork" fort connu : SqlServer auquel Microsoft a assuré une forte visibilité. SqlServer présente de nombreuses analogies avec Sybase et jusque il n'y a pas bien longtemps (je n'ai pas vérifié depuis) il existait une certaine compatibilité.
Le langage procédural utilisé "Tsql" reste compatible pour tous les ordres "simples", et les langages SQL sont très semblables. -
Ingres

C'est aussi une base de données ancienne qui a connu de fortes vicissitudes au cours de son existence, la société avait été rachetée par un des grands du logiciel professionnel : CA qui l'a conservée pendant de nombreuses années sans lui assurer une forte diffusion et a fini par mettre le logiciel plus ou moins en Open Source. Aujourd'hui le développement continue au sein de la société Actian dans les versions "Community" aussi bien que dans les versions "Entreprise" avec support. - Clickhouse
 Cette base semble très rapide et donc intéressante à tester.
Cette base semble très rapide et donc intéressante à tester.
Ingres
Ingres jppDans ce chapitre je vais essayer de présenter la base de données Ingres (prononcer INGRESS ! pour faire américain) avec son inévitable installation dans la version 10 OpenSource.
L'installation sera réalisée sur une machine virtuelle (Centos-5.4 64bits sous KVM) dont l'installation est détaillée dans un autre article.
Afin de rester dans des "normes" raisonnable une configuration analogue à celle utilisée pour Oracle 10g et Sybase 15 est utilisée, pour mémoire elle est constituée de :
- 1 CPU
- 1536 Mo de RAM
- 3 disques de 16 Go
- un pour le système
- un pour les données
- un pour les log et les espaces temporaires
Les disques sont de "simples" partitions LVM sur un ensemble de disques montés en miroir (deux miroirs différents pour données et log).
Cette configuration permettra de faire quelques comparaisons avec le mini-test défini dans cet article.
La machine physique est différente mais sur un seul processeur c'est en gros équivalent (2,4Ghz contre 2,6).
Ingres : installer (1)
Ingres : installer (1) jppPré-requis : Après l'installation du système il est nécessaire (sauf si vous avez chosi KDE) d'installer KDEbase afin de disposer de "konsole", l'explication est toute simple : seul le terminal "konsole" de KDE permet, à ma connaissance, d'avoir le rendu "semi-graphique" utilisé par les outils Ingres, et surtout d'avoir accès aux "bonnes" touches de fonction exploitées par tous les outils de configuration de Ingres.
J'installe aussi mon éditeur préféré "yum install vim-X11".
Le logiciel a été téléchargé et installé dans /var/tmp/INSTALL :
- ingres-10.0.0-122-NTPL-gpl-linux-ingbuild-x86_64.tgz (#60 Mo)
Le "détarage" du fichier crée un répertoire du même nom comprenant :
-rwxr-xr-x 1 ingres 50000 17847 avr 21 19:10 ingres_express_install.sh
-rw-rw-r-- 1 ingres 50000 78571520 avr 21 19:50 ingres.tar
-rwxr-xr-x 1 ingres 50000 13299 avr 21 19:10 install.sh
-rw-r--r-- 1 ingres 50000 15238 avr 21 19:02 LICENSE
-rw-r--r-- 1 ingres 50000 10636 avr 21 19:29 readme_a64_lnx_nptl.html
-rw-rw-r-- 1 ingres 50000 28075 avr 21 19:29 readme.html
L'installation étant parfois en mode texte, parfois en mode semi-graphique je vais essayer de "rendre" au mieux l'aspect des écrans, donc ici pas de belles images, que du texte !
Je me connecte dans une session X avec le user "root" (c'est comme cela depuis la version 2006r3) pour lancer l'installation dans une "konsole".
Ne pas lancer le tentant "ingres_express_install.sh" car il ne réalise qu'une installation minimale avec les données dans le répertoire /opt/Ingres ce qui n'est pas le but visé.
Il suffit de lancer "./install.sh".
- Première question : "Please choose a location to install Ingres ", il faut indiquer le nom du répertoire d'installation du logiciel, ici "/opt/Ingres", ce répertoire sera ensuite "pointé" par la variable "II_SYSTEM".
- Deuxième question "Please choose a user to install Ingres ", indiquer "ingres" puisque nous avons créé cet utilisateur.
- On défile ensuite la licence GPL ... que l'on accepte ...
| Please identify the type of terminal (or terminal emulation software) you are using by entering its Ingres termcap name (e.g. 'vt100f' for a VT100 with a function key pad). If you do not know the termcap name for your terminal, press return to see a list of the available termcap names. Enter termcap name, or press return for a list: |
Répondre ici "konsole", un menu semi-graphique s'affiche alors :
| INGBUILD - Ingres Installation Utility ┌────────────────────────────────────────────────────────────────────────┐ │ II_SYSTEM: /opt/Ingres │ │ Distribution: /var/tmp/INSTALL/ingres-10.0.0-122-NPTL-gpl-linux-in │ └────────────────────────────────────────────────────────────────────────┘ Custom - Select this option in order to view the contents of the distribution medium and/or select components for installation on your system. This option will also allow you to upgrade an existing installation of INGRES products. Package - Select predefined packages for installation on your system. Help - See more instructions on using this program. To select a menu item, press ESC and type the name of the menu item. CustomInstall PackageInstall Help Quit : |
Choisir CustomInstall (Cu) l'écran suivant s'affiche :
| INGBUILD - Custom Install from Distribution Medium Distribution: /var/tmp/INSTALL/ingres-10.0.0-122-NPTL-gpl-linux-ingbuild-x ┌──────────────────────────────────────────────────────┬─────┬──────────┐ │ Custom Component Options │ Size│ Install? │ ├──────────────────────────────────────────────────────┼─────┼──────────┤ │Embedded SQL Precompilers │ 23M│Yes │ │Ingres 32bit support │ 42M│Yes │ │INGRES 6.x Compatible Message Files │ 4M│Yes │ │Ingres Intelligent DBMS │ 104M│Yes │ │Ingres DTP for Tuxedo │ 56M│Yes │ │Ingres Networking │ 66M│Yes │ │Ingres Object Management │ 879K│Yes │ │Ingres ODBC Driver │ 65M│Yes │ │Ingres Protocol Bridge │ 947K│Yes │ │Ingres C2 Security Auditing │ 25K│Yes │ │Ingres Replicator │ 2M│Yes │ └──────────────────────────────────────────────────────┴─────┴──────────┘ II_SYSTEM : /opt/Ingres To add or remove products from the list of products to be installed, enter 'y' or 'n' in the 'Install?' column. Install ExpressInstall GetInfo Help End |
Ici il faut vérifier que tout est à "Yes", puis choisir "Install" (F5), une "boite" affiche un petit récapitulatif :
| INGBUILD - Custom Install from Distribution Medium Distribution: /var/tmp/INSTALL/ingres-10.0.0-122-NPTL-gpl-linux-ingbuild-x +------------------------------------------------------+-----+----------+ | Custom+-----------------------------------------------------+ |=====================|Products selected: 16 Disk space required: 89M | |Ingres ODBC Driver | Support modules : 19 100M | |Ingres Protocol Bridg| -- Temporary storage : 10M | |Ingres C2 Security Au| ---- | |Ingres Replicator | Total: 35 199M | |Ingres Spatial Object| | |Ingres Data Access Se|Do you want to proceed with the installation? | |Ingres Star Distribut+-------------+---------------------------------------+ |Query and Reporting R|Yes |Install all selected products | |Query and Reporting T|No |Cancel requested installation | |Terminal Monitors +-------------+---------------------------------------+ |VisionPro | 66M|Yes | +------------------------------------------------------+-----+----------+ II_SYSTEM : /opt/Ingres To add or remove products from the list of products to be installed, enter 'y' or 'n' in the 'Install?' column. |
Il suffit de frapper "Entrée" sur le "Yes" présélectionné.
L'écran s'anime pendant la vérification puis propose dans une nouvelle "boîte" : "Do you want to set up these products now", frapper "Entrée" sur le "Yes" présélectionné.
Premier setup : "Setting up Application-By-Forms..."
Se contenter d'appuyer sur entrée, un petit message de confirmation s'affiche :
ING_ABFDIR configured as /opt/Ingres/ingres/abf
Application-By-Forms setup complete.
Press RETURN to continue:
Il faut encore faire "Entrée" puis un écran "Setting up the Ingres Intelligent DBMS..." récapitule les paramètres de Ingres DBMS, frapper "y" et "Entrée" puis le message suivant s'affiche :
| Ingres has the capability to guarantee integrity of all committed database transactions in the event of a system software failure or single storage device failure. IMPORTANT NOTE: if a second storage device fails before recovery from an initial failure has taken place, committed transactions may be lost. If you intend to take advantage of this capability, you need to have at least two independent storage devices available (one in addition to the one Ingres is being installed on). If you do not have two independent storage devices available, but would like to take advantage of this capability, you should not complete this setup procedure at this time. Do you want to continue this setup procedure? (y/n) [y] |
Il s'agit d'un écran d'information au sujet du système de logging, ce type d'écran appairatra par la suite pour les phases importants. Ingres permet d'utiliser un "dual log" sur un disque différent pour augmenter la sécurité des données en cas d'incident sur un disque. Nous ne nous servirons pas de cette fonctionnalité.
On frappe donc "y" et "Entrée" sans autre forme de procès et l'installeur génère la configuration par défaut. Celle-ci nous conviendra souvent.
Please enter a valid installation code [II]
Frapper "Entrée"
Do you want instructions on configuring your storage locations? (y/n) [y]
Les "locations" sont les répertoires où Ingres place les différentes catégories d'éléments (log, journal,bases de données, espace de travail ....) , la plupart de ces "locations" sont ensuite pointées par des variables de la forme "II_nom_variable",je préciserais ces éléments au passage, vous pouvez répondre "Y" et voir l'ensemble des conseils, ici je réponds "N".
II_DATABASE
Ici je désire que les données des bases soient placées dans le répertoire "/DATA/ingres", je réponds donc /DATA/ingres.
Please enter the default location for the Ingres Checkpoint Files:
[/opt/Ingres]
Les fichiers de "checkpoint" ne sont pas volumineux, ils peuvent très bien être stockés à l'endroit proposé, un jeu de sous-répertoires sera créé, il convient donc de faire "Entrée".
| ---------------------------------------------------------------------- | *** WARNING *** | | Do not store checkpoint, journal or dump files for a database on | | the same physical device as its data, or you will not be able to | | recover the data stored on that device if it fails. Please verify | | that the default location you have entered for your | | Ingres Checkpoint Files: | | /opt/Ingres | | is on a different physical device from the default location you | | have entered for your database files: | | /DATA/ingres | ---------------------------------------------------------------------- Is the value you have entered for II_CHECKPOINT correct? (y/n) |
Ce type de "warning" est affiché régulièrement afin de nous inciter à réfléchir à la sécurité de notre installation. Si nous sommes "bons" répondre "y" sans crainte.
Please enter the default location for the Ingres Journal Files:
[/opt/Ingres]
Ici aussi nous pouvons prendre cette valeur par défaut.
Please enter the default location for the Ingres Dump Files:
[/opt/Ingres]
Ici aussi nous pouvons prendre cette valeur par défaut.
Please enter the default location for the Ingres Work Files:
[/opt/Ingres]
Ici nous voulons utiliser le même disque que le log, nous mettons donc le nom de notre répertoire réservé : "/LOG/ingtemp".
Do you want to disable the backup transaction log? (y/n) [n]
Il s'agit ici du fameux "Dual_log" dont nous n'avons pas besoin pour une machine de test, il n'en serait pas de même en production où il faudrait le positionner sur un autre disque physique que le log standard, nous répondons donc "Y".
The default size for the Ingres transaction log is:
262144K bytes ( 256M bytes)
Do you want to change the default transaction log size? (y/n) [n]
Ici la taille proposée est de 256Mo, le log étant un buffer circulaire il est nécessaire de la positionner à une taille suffisante pour supporter la charge transactionnelle. Ici pour certains tests "lourds" il sera positionné à 4Go, répondons "n" pour pouvoir proposer une valeur différente.
Please enter the desired transaction log size (in Megabytes): 4096
Suivi de "Entrée"
Please enter a location for the Ingres transaction log:
[/opt/Ingres]
Mettre ici le répertoire que nous avons prévu pour ceci : "/LOG/ingres".
| You must now specify the number of CPUs (processors) in this machine so that Ingres may be set up for this server. If you do not know the exact number of CPUs, but know that this is a multi-cpu machine, enter a value of 2. The value you specify will be used to set the Ingres variable II_NUM_OF_PROCESSORS and possibly other configuration variables. Please enter the number of CPUs in this machine [1] Y |
Ici, un seul CPU est prévu, il faut ensuite choisir le fuseau horaire (en deux étapes), première liste :
AFRICA
ASIA
AUSTRALIA
MIDDLE-EAST
NORTH-AMERICA
NORTH-ATLANTIC
SOUTH-AMERICA
SOUTH-PACIFIC
SOUTHEAST-ASIA
GMT-OFFSET
Please enter one of the named regions:
Saisir "NORTH-ATLANTIC" qui envoie sur l'écran suivant où nous choisirons "EUROPE-WESTERN", il faut ensuite valider cette configuration.
The time zone you have selected is:
EUROPE-WESTERN (Western European Time Zone)
If this is not the correct time zone, you will be given the opportunity to
select another region.
Is this time zone correct? (y/n) [y]
La réponse est "y", sauf si l'on a fait n'importe quoi. Il faut ensuite choisir le jeu de caractères à utiliser pour les données :
This setting must be assigned one of the following values:
UTF8 ALT KOI8
PC857 ARABIC CW
DOSASMO ELOT437 GREEK
HEBREW HPROMAN8 IBMPC437
IBMPC850 IBMPC866 IS885915
ISO88591 ISO88592 ISO88595
ISO88597 ISO88599 CSGB2312
CSGBK CHINESET CHINESES
CHTHP CHTBIG5 CHTEUC
KANJIEUC KOREAN SHIFTJIS
PCHEBREW SLAV852 THAI
WARABIC WHEBREW WIN1250
WIN1252 WIN1253 WTHAI
Please enter a valid character set [ISO88591]
J'aime bien le "ISO885915" que je spécifie.
The character set you have selected is:
IS885915 (ISO-8859-15 (Latin 9))
Is this the character set you want to use? (y/n) [y]
Répondre "y" évidemment.
Cette "page" étant déjà très longue l'installation se poursuit sur une autre page.
Ingres : installer (2)
Ingres : installer (2) jppInstallation Ingres suite.
How many concurrent users do you want to support? [32]
Répondre "Entrée", 32 pour des tests c'est déjà pas mal. L'initialisation proprement dite de la BDD commence alors par le LOG
| The primary transaction log will now be created as an ordinary (buffered) system file. For information on how to create a "raw", or unbuffered, transaction log, please refer to the Ingres Installation Guide, after completing this setup procedure. Creating a 1048576K byte transaction log file... 0% 25% 50% 75% 100% |||||||||||||||||||||||||||||||||||| |
Cela dure quelques instants, le temps de formater 1Go sur le disque.
Do you wish to associate date data type to refer to ingresdate ? (y/n) [y]
Valider le "y".
Do you need strict compliance to the ANSI/ISO standard? (y/n) [n]
Valider le "n" cela déclenche l'installation proprement dite, les informations présentées ont été "raccourcies" :
| Ingres/ingstart Checking host "com-ingres" for system resources required to run Ingres... Your system has sufficient resources to run Ingres. Starting your Ingres installation... Starting the Name Server... Allocating shared memory for Logging and Locking Systems... Starting the Recovery Server... ..... Creating DBMS System Catalogs . . . Modifying DBMS System Catalogs . . . Creating Database Database System Catalogs . . . Modifying Database Database System Catalogs . . . Creating Standard Catalog Interface . . . Creating Front-end System Catalogs . . . ...... This setup process can create and populate a demonstration database (demodb) which will be used by the Ingres demonstration applications. Do you want demodb to be created? (y/n) [y] |
Répondre "y" et valider, nous disposerons ainsi d'une petite base de départ.
.....
la base "demo" s'installe
...
| ... executing checkpoint to disk ending checkpoint to disk /opt/Ingres/ingres/ckp/default/demodb of 1 locations Shutting down the Ingres server... Ingres Intelligent DBMS setup complete. Refer to the Ingres Installation Guide for information about starting and using Ingres. Press RETURN to continue: |
L'initialisation de la base est terminée on passe à la suite :
| Setting up Ingres Networking... ..... If you do not need access to this Ingres server from other hosts, then you do not need to set up Ingres Networking. Do you want to continue this setup procedure? (y/n) [y] |
Répondre "y" et valider
| Installation passwords offer the following advantages over user passwords: + Remote users do not need login accounts on the server host. + Installation passwords are independent of host login passwords. + Installation passwords are not transmitted over the network in any form, thus providing greater security than user passwords. + User identity is always preserved. If you need more information about Ingres Networking authorization, please refer to the Ingres Connectivity Guide. Press RETURN to continue: |
Comme d'habitude les conseils pour la suite, nous utiliserons un "Installation password".
Do you want to create an installation password for this server? (y/n)
Répondre "y" et valider.
.....
Enter installation password:
On entre un beau mot de passe ... et on confirme, on le note pour ne pas l'oublier ! .
| Installation password created. The name server has been shut down. Ingres Networking has been successfully set up in this installation. You can now use the "ingstart" command to start your Ingres server. Refer to the Ingres Installation Guide for more information about starting and using Ingres. Press RETURN to continue: |
En pressant "Return" on arrive sur la configuration "ODBC" :
Enter the default ODBC configuration path [ /usr/local/etc ]:
Valider sans remords
The default ODBC configuration path is /usr/local/etc
Is the path information correct? (y/n) [y]
Répondre "y" et confirmer la réponse.
The default ODBC configuration path is /usr/local/etc
Is the path information correct? (y/n) [y] y
Répondre "y" sans hésiter
Is this always a read-only driver? (y/n) [n]
Sur une machine de production répondre "y" sans hésiter, ici on laisse "n" et on confirme ce manquement à la sécurité, la réponse ne se fait pas attendre :
Could not open from path /usr/local/etc.
E_CL1904_SI_CANT_OPEN SIfopen: Can't open file
Cannot write to specified ODBC configuration path /usr/local/etc
Writing instead to /opt/Ingres/ingres/files/odbcinst.ini.
Successfully wrote ODBC configuration files
An odbcinst.ini file has been created in the directory "/opt/Ingres/ingres/files".
You may use the utility iiodbcadmn to create and manage
ODBC data sources.
See the Ingres Installation Guide for more information.
Press RETURN to continue:
C'était bien la peine ! On copiera ce fichier plus tard.
Le setup de "Ingres Protocol Bridge..." se passe sans question --> Return.
Le setup de "C2 Security Auditing" se passe sans encombres, il faut valider puis "Setting up Replicator" s'affiche, il faut là aussi valider et on enchaine sur :
| Setting up the Ingres Data Access Server... This procedure will set up the following version of Ingres Data Access Server: II 10.0.0 (a64.lnx/122)NPTL to run on local host: com-ingres Do you want to continue this setup procedure? (y/n) [y] |
Répondre "y" et valider et on arrive sur la configuration data access server et de JDBC qui se passe sans autre question.
| Executing Ingres JDBC driver properties generator utility... The JDBC driver properties file 'iijdbc.properties' was created in $II_SYSTEM/ingres/files directory Ingres Data Access Server has been successfully set up in this installation. Please adjust the startup count and check the listen address with the cbf utility. Press RETURN to continue: |
On presse, encore, "Entrée" pour passer à la configuration (automatique) de "Ingres Star" à suivre de l'appui sur "Entrée".
| INGBUILD - Custom Install from Distribution Medium Distribution: /var/tmp/INSTALL/ingres-10.0.0-122-NPTL-gpl-linux-ingbuild-x +------------------------------------------------------+-----+----------+ | Custom Component Options | Size| Install? | |======================================================+=====+==========| |Embedded SQL Precompilers | 23M|Ready | |Ingres 32bit support | 42M|Ready | |INGRES 6.x Compatible Message Files | 4M|Ready | |Ingres Intelligent DBMS | 104M|Ready | |Ingres DTP for Tuxedo | 56M|Ready | |Ingres Networking | 66M|Ready | |Ingres Object Management | 879K|Ready | |Ingres ODBC Driver | 65M|Ready | |Ingres Protocol Bridge | 947K|Ready | |Ingres C2 Security Auditing | 25K|Ready | |Ingres Replicator | 2M|Ready | +------------------------------------------------------+-----+----------+ II_SYSTEM : /opt/Ingres +----------------------------------------------------------------------------+ | All installed products are now available for use. | | [PRESS RETURN] | +----------------------------------------------------------------------------+ |
Le dernier appui sur "Entrée" avant l'appui sur "F3" pour sortir de l'installeur.
Ensuite le démarrage normal du serveur Ingres est déclenché et se termine par :
Starting the Visual DBA Remote Command Server...
Ingres installation successfully started.
Building the password validation program 'ingvalidpw'.
Executable successfully installed.
L'installation est terminée le répertoire /opt/Ingres/ingres contient :
drwxrwxrwx 2 ingres ingres 4096 mai 3 16:57 abf
drwxr-xr-x 2 ingres ingres 4096 mai 3 17:12 bin
drwx------ 3 ingres ingres 4096 mai 3 16:58 ckp
drwxr-xr-x 5 ingres ingres 4096 avr 21 19:49 demo
drwx------ 3 ingres ingres 4096 mai 3 16:59 dmp
drwxr-xr-x 16 ingres ingres 4096 mai 3 17:12 files
drwxrwxrwx 3 ingres ingres 4096 avr 21 19:49 install
drwx------ 3 ingres ingres 4096 mai 3 16:59 jnl
drwxr-xr-x 3 ingres ingres 4096 mai 3 16:57 lib
drwxrwxrwx 3 ingres ingres 4096 mai 3 17:10 rep
drwxr-xr-x 10 ingres ingres 4096 avr 21 19:49 sig
drwxrwxr-x 3 ingres ingres 4096 avr 21 19:48 utility
drwxr-xr-x 2 ingres ingres 4096 mai 3 17:04 vdba
-rw-r--r-- 1 ingres ingres 28 avr 21 19:28 version.rel
Après cette installation épuisante un peu de repos avant de passer aux ajustements nécessaires à une utilisation "normale" de Ingres.
Ingres : ajustements
Ingres : ajustements jppAvant les quelques ajustements nécessaires à une utilisation agréable une petite explication sur les "locations".
Les "locations" sont pour Ingres des espaces disques où peuvent être installées des bases de données ou des parties de bases de données, pour Oracle on utilise le mot "tablespace". Dans ces locations, pour chaque base, Ingres crée un répertoire portant le nom de la base. Un fichier (au sens OS) est ensuite créé pour la plupart des objets de base de données (tables, index ...).
Toute base a, au moins, une location ou créer les bases "iidbdb" et "imadb".
- iidbdb = "base des bases", c'est le catalogue général de Ingres.
- imadb = base contenant essentiellement des éléments liés à la performance.
Variables "système" à mettre en place impérativement :
II_SYSTEM mettre à '/opt/Ingres'
II_INSTALLATION mettre à II
PATH y ajouter $II_SYSTEM'/ingres/bin' et $II_SYSTEM'/ingres/lib'
LD_LIBRARY_PATH y ajouter $II_SYSTEM'/ingres/lib'
INGRES_TERM à mettre à "vt220"
TERM à mettre à "vt220", on dispose alors d'un aspect et de fonctionnalités correctes dans une "konsole" pour les utilitaires "semi-graphiques" qui font le délice des amateurs.
Un petit script à placer par exemple dans le fichier /etc/default/ingres et lancé par "source /etc/default/ingres" dans son ".bashrc" favori, un tel script est fourni en fichier attaché.
Ne pas oublier d'utiliser le "bon" type de terminal (pour moi "konsole") et forcer "TERM" et "INGRES_TERM" à "vt220". Mettre cela dans votre profil.
Les utilitaires :
- ingstart sert a démarrer la base
- ingstop sert à stopper la base, possède quelque switchs d'usage courant "-force, -immediate, -kill" et d'autres à découvrir en tapant "ingstop -h".
- ingstatus permet de voir les process "Ingres" et leur état
- cbf très important, sert à gérer les paramètres de la base.
- accessdb qui permet de gérer bases, locations et utilisateurs
Ceci dit penchons nous sur quelques scripts qui facilitent la vie :
- Script de connexion
Le script proposé "ingres" est en à installer dans /etc/default et est "sourcé" dans les scripts de connexion des utilisateurs (ou exécuté par . /etc/default/ingres )
Ce script est par ailleurs utilisé dans les scripts de démarrage proposés.
Afficher ce script. - Script de démarrage (automatique)
Le script proposé est en deux parties :
Un script coté "ingres" : start_stop à installer dans $II_SYSTEM/ingres
Afficher ce script.
Un script coté "système" : ingres_cmd à installer dans /etc/init.d avec les bons liens qui se contente d'appeler le script "ingres"
Afficher ce script. - NB : les fichiers attachés doivent être renommés en supprimant de suffixe ".txt"
Compléments de configuration :
La partie essentielle est la configuration des caches. Ingres permet de créer des bases avec différentes tailles de page (une taille est à choisir pour la valeur par défaut), on peut même avoir des tables avec des tailles différentes dans la même base.
Ici nous prendrons des pages de 8K pour se comparer aux autres bases déjà testées "à armes égales".
Petit tour dans "cbf" qui a la "gueule" habituelle.
| CBF - Configuration-By-Forms Host: com-ingres II_SYSTEM: /opt/Ingres II_INSTALLATION: II ┌────────────────────────┬────────────────────────┬───────────────┐ │System Component │Configuration Name │Startup Count │ ├────────────────────────┼────────────────────────┼───────────────┤ │Name Server │(default) │1 │ │DBMS Server │(default) │1 │ │Star Server │(default) │0 │ │Locking System │(default) │1 │ │Logging System │(default) │1 │ │Transaction Log │II_LOG_FILE │1 │ │Transaction Log │II_DUAL_LOG │0 │ │Recovery Server │(default) │1 │ │Archiver Process │(not configurable) │1 │ │Remote Command │(not configurable) │1 │ │Security │(default) │1 │ └────────────────────────┴────────────────────────┴───────────────┘ Configure(1) EditCount(2) Duplicate(3) ChangeLog(8) > |
On commence par mettre à zero de "Startup count" de "Star Server" en :
- se positionnant sur la bonne ligne
- appuyant sur "F1" pour aller dans la zone de commandes
- Frappant "Ed" pour EditCount
On obtient alors une zone de saisie pour la variable concernée : ┌────────────────────────────────────────────────────────────────────────────┐
│ Please enter the number of copies of the selected component you want to │
│ execute at startup: │
│ └────────────────────────────────────────────────────────────────────────────┘
On peut alors entrer la valeur souhaitée (ici 0) suivie de "Entrée".
Toutes les actions s'exécutent, après affichage de la liste, selon le même principe :
- se positionnr sur l'élément à modifier
- appuyer sur "F1"
- frapper le début de la fonction à exécuter
- réaliser son rêve, frapper "Entrée".
Pour configurer le "DBMS Server" :
- se positionner sur la ligne "DBMS Server"
- Frapper sur "F1"
- Frapper "co" pour "configure"
- accéder à la liste des valeurs de configuration
La liste peut être parcourue, un appui sur "F2" donne accès à une aide dont on sort par "F3".
Dans cette liste on remarque la variable "connect_limit" positionnée à 32 si vous avez bien suivi la configuration
de départ. Ce qui nous intéresse dans un premirr temps est le "default_pagesize" magnifiquement déjà positionné
à 8K.
On va vérifier la taille des caches, "F1" puis saisir "cache" on voit alors que les caches de 2k et 8K sont "on", on
se positionne sur le cache "8K", un petit coup de "F1" puis configure nous amène :
| ┌──────────────────────────────────────────────────────────────┐ │ DBMS Cache Parameters for 8k Buffers │ ├────────────────────┬────────────────────┬────────────────────┤ │Name │Value │Units │ ├────────────────────┼────────────────────┼────────────────────┤ │cache_guideline │medium │ │ │dmf_group_size │8 │data pages │ │dmf_separate │OFF │boolean │ │dmf_write_behind │ON │boolean │ │ │ │ │ └────────────────────┴────────────────────┴────────────────────┘ Edit(2) Derived(5) Restore(6) ChangeLog(8) Help(PF2) > |
Un petit coup de "Derived" sur "cache_guideline" nous affiche le détail de la mémoire affectée :
| ┌────────────────────────────────────────────────────────────────────────┐ │ Derived DBMS Cache Parameters for 8k │ ├────────────────────┬────────────────────┬────────────────────┬─────────┤ │Name │Value │Units │Protected│ ├────────────────────┼────────────────────┼────────────────────┼─────────┤ │dmf_cache_size │24000 │data pages │no │ │dmf_free_limit │750 │data pages │no │ │dmf_group_count │750 │group buffers │no │ │dmf_memory │245760000 │bytes │no │ │dmf_modify_limit │18000 │data pages │no │ │dmf_wb_end │7200 │data pages │no │ └────────────────────┴────────────────────┴────────────────────┴─────────┘ |
J'ai "forcé" le "dmf_cache_size à 24000 et je force dmf_free_limit et dmf_group_count à 2400 pour affecter un peu plus de mémoire aux buffers. Je ne touche pas aux autres valeurs.
Les autres valeurs fixées par défaut ne doivent pas être modifiées sans un besoin précis (machines de production) et des avis "autorisés" sous peine de manque de performance, l'utilisation de la touche "F2" permet de se documenter sur les variables.
Après notre petit "bricolage" on sort de ces modifications par "F3" et cbf nous propose de sauvegarder nos mises à jour, nous restons positionnés sur "Yes" et l'appui sur "Entrée" sauvegarde le tout. Un appui sur "F4" nous permet de sortir définitevement de cbf. Il ne nous reste plus qu'à appliquer nos modifications :
"ingstop -immediate" cela rappelle le "shutdown immediate;" de Oracle ?
Puis :
"ingstart"
Et c'est Parti ...
Ingres : minitest
Ingres : minitest jppLa table "habituelle" a été reconstituée à grans coups de "insert/select". Toutefois la syntaxe permettant de "décaler" vers le passé les dates "historiques" conservées en format "texte" AAAAMMJJ n'est pas évidente et forte consommatrice de CPU.
Calcul des statistiques (optimizedb) (doc disponible) :
optimizedb -utest -zu4096 -zv test -rxen_stat_v2
ven mai 7 11:41:25 CEST 2010
*** statistics for database test version: 01000
*** table imp_xen rows:793466 pages:15561 overflow pages:15558
*** column nbsecw of type decimal (length:10, scale:2, nullable)
date:07-may-2010 10:41:28 unique values:801.000
repetition factor:990.5942383 unique flag:N complete flag:0
domain:0 histogram cells:1602 null count:0.0000000 value length:8
*** statistics for database test version: 01000
*** table imp_xen rows:793466 pages:15561 overflow pages:15558
*** column nbsecr of type decimal (length:10, scale:2, nullable)
........
*** statistics for database test version: 01000
*** table xen_stat_v2 rows:13195433 pages:206183 overflow pages:206177
*** column deltacpu of type decimal (length:10, scale:2, nullable)
date:07-may-2010 10:43:00 unique values:61.000
repetition factor:216318.5781250 unique flag:N complete flag:0
domain:0 histogram cells:122 null count:0.0000000 value length:8
ven mai 7 11:43:00 CEST 2010
Soit un temps de 1 minute et 25 secondes.
Création du premier index :
sql -utest test <statv2_cre_idx.sql
INGRES TERMINAL MONITOR Copyright 2010 Ingres Corporation
Ingres Linux Version II 10.0.0 (a64.lnx/122)NPTL login
Wed May 5 14:42:31 2010
continue
* * * * * * * * * /* SQL Startup File */
create index xen_stat_v2_i1 on xen_stat_v2 (DOMNOM, DATEC, HEUREC) ;
Executing . . .
(13147446 rows)
continue
Your SQL statement(s) have been committed.
Ingres Version II 10.0.0 (a64.lnx/122)NPTL logout
Wed May 5 14:44:30 2010
Soit environ 1 minute 59 secondes.
Création du second index :
sql -utest test <statv2_cre_idx.sql
INGRES TERMINAL MONITOR Copyright 2010 Ingres Corporation
Ingres Linux Version II 10.0.0 (a64.lnx/122)NPTL login
Wed May 5 14:47:34 2010
continue
* * * * * * * * * /* SQL Startup File */
create index xen_stat_v2_i2 on xen_stat_v2 (DATEC, DOMNOM, HEUREC) ;
Executing . . .
(13147446 rows)
continue
*
Your SQL statement(s) have been committed.
Ingres Version II 10.0.0 (a64.lnx/122)NPTL logout
Wed May 5 14:49:50 2010
Soit environ 2 minutes et 16 secondes.
Comptages :
1) comptage "brut"
sql -utest test <CNT_1.sql
INGRES TERMINAL MONITOR Copyright 2010 Ingres Corporation
Ingres Linux Version II 10.0.0 (a64.lnx/122)NPTL login
Wed May 5 14:53:09 2010
* * * * * * /* SQL Startup File */
select count(*) from xen_stat_v2
Executing . . .
┌─────────────┐
│col1 │
├─────────────┤
│ 13147446│
└─────────────┘
(1 row)
continue
*
Your SQL statement(s) have been committed.
Ingres Version II 10.0.0 (a64.lnx/122)NPTL logout
Wed May 5 14:53:25 2010
Soit environ 16 secondes.
2) Comptage group by
sql -utest test <CNT_GRP_1.sql
INGRES TERMINAL MONITOR Copyright 2010 Ingres Corporation
Ingres Linux Version II 10.0.0 (a64.lnx/122)NPTL login
Wed May 5 14:55:09 2010
* * * * * * * * /* SQL Startup File */
select domnom,count(*)
from xen_stat_v2
group by domnom
order by domnom
Executing . . .
┌────────────────┬─────────────┐
│domnom │col2 │
├────────────────┼─────────────┤
│Domain-0 │ 2512057│
│amdx2-2000 │ 254925│
│amdx2-bi2003 │ 255541│
......
│k2000-ora64 │ 2333479│
│k2000-ora65 │ 898205│
│k2000-ora66 │ 862580│
└────────────────┴─────────────┘
(19 rows)
continue
*
Your SQL statement(s) have been committed.
Ingres Version II 10.0.0 (a64.lnx/122)NPTL logout
Wed May 5 14:55:29 2010
Soit environ 20 secondes.
3) Comptage "group by"
sql -utest test <CNT_GRP_2.sql
INGRES TERMINAL MONITOR Copyright 2010 Ingres Corporation
Ingres Linux Version II 10.0.0 (a64.lnx/122)NPTL login
Wed May 5 14:57:04 2010
continue
* * * * * * * * /* SQL Startup File */
select domnom,serveur,count(*)
from xen_stat_v2
group by domnom,serveur
order by domnom,serveur
Executing . . .
┌────────────────┬────────────────┬─────────────┐
│domnom │serveur │col3 │
├────────────────┼────────────────┼─────────────┤
│Domain-0 │k2000 │ 2305773│
......
│k2000-ora66 │k2000 │ 862580│
└────────────────┴────────────────┴─────────────┘
(24 rows)
continue
*
Your SQL statement(s) have been committed.
Ingres Version II 10.0.0 (a64.lnx/122)NPTL logout
Wed May 5 14:57:38 2010
Soit environ 34 secondes.
En bref la base de données est assez rapide et n'a pas à rougir devant les performances des autres bases existantes. La gestion des bases Ingres est très simple, beaucoup de bases utilisées dans l'industrie tournent sans aucun DBA qualifié. Si la base est bien installée (répartition et place disque) et paramétrée correctement (taille mémoire, log, espace temporaire, système de "lock") elle peut fonctionner des années quasiment sans intervention, cela n'empêche pas de sauvegarder les données !
Petit rappel sur l'outil "sql".
L'outil "sql" utilisé pour les tests est l'outil "batch" de Ingres (il peut aussi être utilisé "à la main" bien sûr).
La syntaxe SQL est assez standard, seuls quelques "trucs" peuvent gêner :
- exécuter l'ordre SQL courant : il faut frapper "\g" pour lancer l'exécution ou "\p\g" pour lister l'ordre et l'exécuter.
- quitter : il faut frapper "\q"
Le prompt est marqué par un "*" exemple :
* help\g
Executing . . .
Name Owner Type
xen_stat_v2 test table
xen_stat_v2_i1 test index
xen_stat_v2_i2 test index
(3 rows)
continue
*\q
Il faut le savoir ... pour la doc c'est ici.
Rappel sur les "switchs" :
Attention dans Ingres, les switchs de commande comme le "-u" dans "sql -utest" ne doivent pas être suivis d'un espace contrairement à beaucoup d'autres logiciels.
Sybase
Sybase jppUn chapitre sur Sybase comprenant plusieurs articles dont le premier concerne l'inévitable installation. La version présentée ici est la version 15 de Sybase dans la déclinaison "développeur" qui est complètement fonctionnelle et ne souffre que de faibles limitations ( essentiellement limitée à un process serveur).
L'installation a été réalisée sur un support "Centos" en version 5.4 (X86_64 en machine virtuelle XEN) qui convient très bien à la version la plus récente de Sybase.
Une installation de la partie système est détaillée dans un autre article.
La machine virtuelle d'installation dispose de :
- 1 CPU
- 1536 Mo de RAM
- 3 disques de 16 Go
- un pour le système
- un pour les données
- un pour les log et les espaces temporaires
Je dispose par ailleurs d'une machine virtuelle Oracle 10g (sur Oracle Linux 4.8) présentant des caractéristiques analogues, cela permettra d'établir quelques comparaisons.
Sybase : Installation
Sybase : Installation jppRappel : La machine choisie pour cette installation est une machine fraîchement installée avec une Centos 5.4 sous XEN zt munie de :
- RAM : 1,5G
- CPU : 1
- Disques :
- 16G système
- 16G données
- 16G temporaire et logs
Bien que l'on puisse avec profit en performance utiliser des "raw-devices" : partitions non gérées par l'OS, j'ai choisi d'utiliser des fichiers traditionnels du file-système.
Pré-requis :
- créer un utilisateur "sybase"
- Créer un répertoire "/opt/sybase" avec propriétaire "sybase"
- Créer un répertoire "SYBDAT" avec propriétaire "sybase" dans le deuxième disque monté sur /DATA
- créer un répertoire "SYBTMP" avec propriétaire "sybase" dans le troisième disque monté sur /LOG
Détarer l'archive dans un répertoire "propre", au premier niveau deux fichiers :
- un fichier décrivant les limites légales du logiciel
- setup.bin
et un répertoire d'archives contenant le logiciel à installer.
Installation.
Se connecter en X et ouvrir une fenêtre terminal, dans le répertoire d'installation, un simple "./setup.bin" lance l'installeur (Java comme beaucoup) qui ouvre sa fenêtre en attendant l'appui sur la touch "Next". Tiens pas de français ?
Après l'appui sur "Next" écran "Choose Install Folder" 
L'écran propose "/opt/sybase" il est sage de l'accepter et de cliquer sur "Next".
L'écran suivant propose 3 options : "Typical", "Full" et "Custom", étant audacieux je choisis "Full", autant disposer du maximum de possibilités.
L'écran suivant "Software license type selection" : 
N'ayant pas de license, nous choisirons la version "Free developper".
Puis il faut définir son pays pour lire le contrat de license dans sa langue ... non, une seule possibilité "All regions" et c'est en anglais ... J'aime bien les questions à choix simple ! Je clique "I agree" (ça veut dire quoi ?) et "Next".
Un pétit écran de récap : 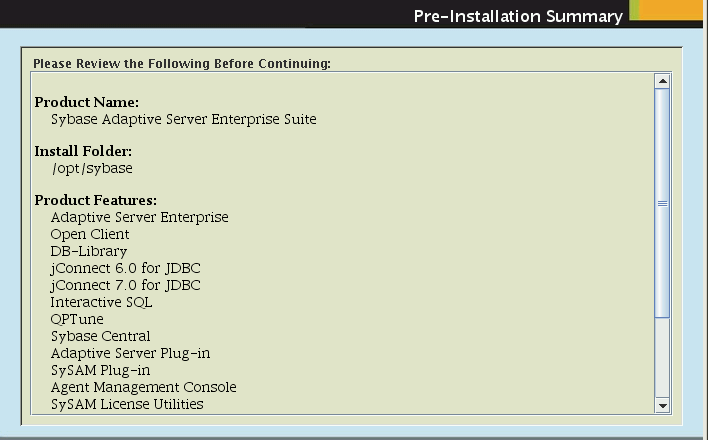
il me semble que tout est là, même "Sybase Central" que l'on avait parfois du mal à trouver et les drivers JDBC et ODBC. L'installation complète consomme un peu plus de 1,1Go.
Il ne reste plus qu'à cliquer sur "Install", ce que je m'empresse de faire, l'installation du logiciel démarre avec le petit baratin publicitaire défilant qui nous occupe pendant l'installation. C'est vachement à la mode.
La fin de l'installation arrive et on nous propose de "retenir" ou non les mots de passe. N'ayant pas besoin de sécurité pour des tests je choisis "Enable" par paresse et clique sur "Next".
On arrive maintenant aux points importants : la configuration des différents serveurs constituant Sybase : 
Il vaut mieux les configurer tous dès le début, cela sera toujours cela de fait, on entre ensuite dans un écran spécifique à chaque process serveur.
Ecran "Configure New Adaptative Server" 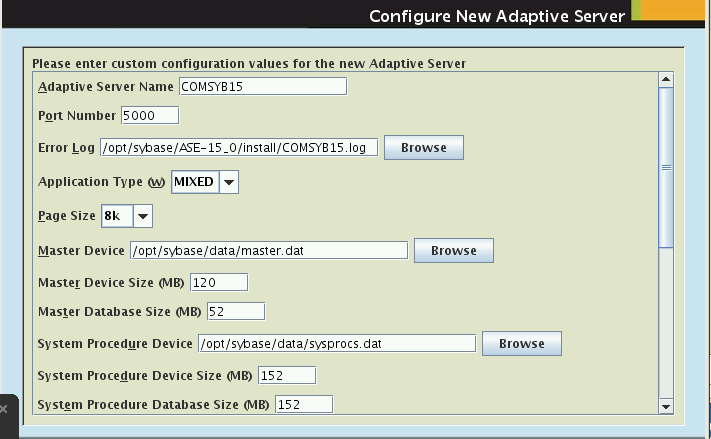
nous propose de nombreux paramètres :
- Nom , celui préparé me va ...
- Port number : 5000 ne me gêne pas
- Application type : je garde "Mixed" car je désire faire plein de choses
- Page size : Les anciennes pages de 2K étaient un peu trop petites, je vais prendre 8K comme la plupart des bases Oracle.
- Fichiers de log, je les mets tous dans /opt/sybase/log
- Devices : c'est comme cela que Sybase nomme les fichiers de données, un certain nombre de "devices" sont obligatoires, il s'agit de leur donner un emplacement physique et une taille. Les tailles proposées par Sybase sont en général un peu "justes" pour des machines d'exploitation, mais ici cela devrait nous suffire. Ces espaces obligatoires sont analogues aux tablespaces "System", "TEMP" ... pour Oracle.
- Master device : /DATA/SYBDAT/master.dat
- Master device size : 128
- Master database size : 64
- System procedure device : /DATA/SYBDAT/sysprocs.dat
- System procedure device size : 160
- System procedure database sise : 160
- System Device : /DATA/SYBDAT/sybsysdb.dat
- Sstem device size : 32
- System database size : 32
- Tempdb device : je le positionne sur un autre disque /LOG/SYBTMP/tempdbdev.dat
- Tempdb device size : 256
- Tempdb database size : 256
- Enable PCI : je le laisse à "no"
- Optimize ASE configuration : "yes"
- available physical memory pour ASE : 1024
- available CPU for ASE : 1 (limité à 1 pour la version developpeur).
Un petit "Next" et juste un Warning car j'ai choisi des pages de 8K ce qui est incompatible avec le rechargement de bases "anciennes" qui avaient, en principe, des pages de 2K et nous voilà sur le paramétrage du "Backup Server" :
- Name : je le laisse
- Port number : pourquoi pas 5001
- error log : je le laisse
"Next" nous emporte vers le "Monitor Server"
- Nom : je le laisse
- Port Number : 5002 n'est pas pire qu'un autre
- Error log : je le laisse
"Next" conduit vers le paramétrage du "Xp Server" avec son port 5003 et son error log, un autre "Next" nous donne accès au paramétrage du "Job scheduler". Tiens un port number à 4900 ? Pour le reste les valeurs par défaut sont convenables. Après le "Next" suivant nous arrivons au "saint des saints" le superuser "sa" sans possibilité de toucher au mot de passe puisque on a choisi "Enable" pour la gestion des mots de passe .
Et maintenant les "Web Services" avec un paquet de ports et de mots de passe ...on laisse les valeurs par défaut (sauf pour les mots de passe !).
Encore un "Next" pour le "Self Discovery Service Adaptor" que je choisis de configurer le "UDP Adaptor" et je refuse le "JNI" comme j'en ai le droit !
Encore "Next" pour arriver sur "Security modules" où je ne coche que les deux premiers. Le "Next" nous permet, enfin, d'arriver à la fin de la configuration et le récap nous permet de revoir un peu tous nos choix avant de cliquer un autre "Next" qui déclenche la création de la base de données et l'affichage des logs des scripts de création et c'est la fin de ce roman passionnant 
Cette partie est assez longue car Sybase crée les fichiers de data et les remplit intégralement : ce qui est pris n'est plus à prendre, la place prise est bien réservée.
Avant de pouvoir s'en servir allons voir un peu le répertoire d'installation qui comporte plein de répertoires ... avec de nombreux sous répertoires "bin" qu'il va falloir ajouter à notre "PATH" avant de pouvoir faire mumuse.
Heureusement on peut trouver dans "/opt/sybase" le merveilleux script "SYBASE.sh" qui fait çà très bien ". /opt/sybase/SYBASE.sh" résout ce problème pour nous.
Dans un prochain épisode le lancement des premières commandes, vous apprendrez à mettre des "go" partout dans "isql".
Pour vous mettre l'eau à la bouche une petite image de l'outil de gestion "Sybase Central" 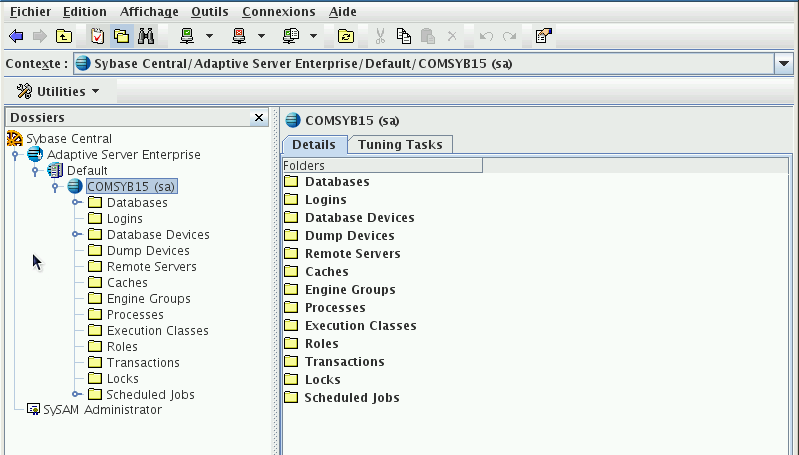
que l'on peut lancer par :
./shared/sybcentral600/scjview.sh
puis se connecter (clic droit sur "Adaptative Server Enterprise" + "Connect", pas de mot de passe (il est stocké, rappelez vous le "Enable". Ici beaucoup de choses se commandent par le "clic droit" et les menus associés.
Vous avez alors accès au module central de gestion de Sybase qui vous permet même de gérer plusieurs serveurs simultanément, ce module est une véritable "tour de contrôle".
Sybase : ajustements
Sybase : ajustements jppAprès l'installation il reste toujours quelques "bricoles" à faire pour avoir un système plus commode et agréable à utiliser.Modifier le .profile (ou le .bashrc) du user de test pour y insérer l'appel à "/opt/sybase/SYBASE.sh" afin de pouvoir travailler sans penser sans arrêt à frapper :
. /opt/sybase/SYBASE.sh
Un certain nombre d'ajustements sont indispensables, par exemple "isql" n'aime pas ma locale "fr_FR@euro" (variable LANG), il faudra "forcer" la valeur de LANG à une valeur compatible avec celles existant dans le fichier "/opt/sybase/locales/locales.dat".
Mettre en place la langue "français".
Il faut passer par l'utilitaire "sqlloc" (/opt/sybase/ASE-15_0/bin/sqlloc) qui permet de réaliser cet exploit dans un mode semi-graphique 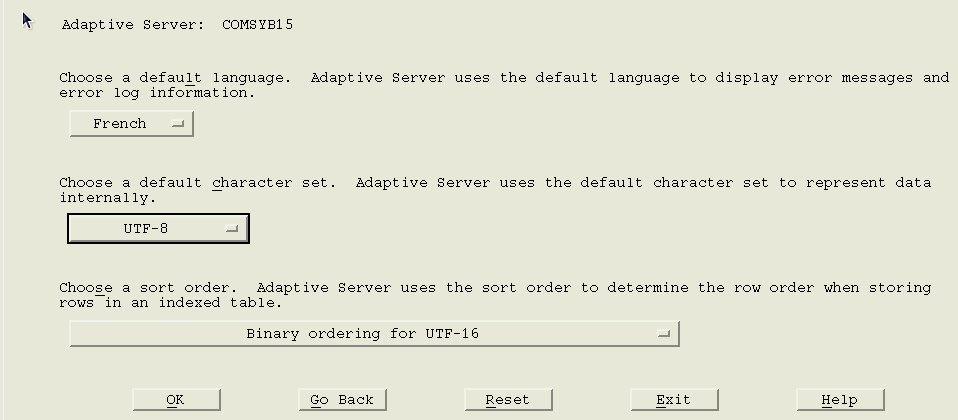
Ne pas oublier de modifier le "default character set".
Ma machine utilise les "locales" fr_FR.UTF-8 il m'a fallu pour terminer ajouter une ligne descriptive dans le fichier "/opt/sybase/locales/locales.dat" :
locale = fr_FR.UTF-8, french, iso_1
est à insérer dans le paragraphe [linux] après "fr_FR.850 ...". Il reste quelques "bricoles" au niveau des caractères accentués dans les messages, mais les caractères stockés dans la base ressortent correctement..
Ces petites mises au point permettent d'ajouter au script "SYBASE.sh" les lignes suivantes :
LANG=fr_FR.UTF-8
SYB=/opt/sybase
export SYB
On peut ensuite oeuvrer tranquilles sans messages, ou refus, intempestifs lors du lancement des utilitaires.
Avant de faire quoi que ce soit d'autre il faut :
- créer un "login" pour pouvoir réaliser des tests
- créer deux "devices" pour pouvoir créer une base de données de test car il est très fortement déconseillé de créer des objets dans les espaces "système".
Device numéro 1 pour les "data'
Device numéro 2 pour le "log"
- créer une base de données pour les tests
Les scripts fournis peuvent être lancés par :
cd le_repertoire_de_stockage_des_scripts
isql -Usa -SCOMSYB15 -D master -i le_nom_du_script
A la demande de password frapper "Entrée" tout simplement.
Les scripts fournis ici doivent être personnalisés.
- Script de création du device "DATA" :
disk init name='MABASE', physname='/DATA/SYBDAT/MABASE.dat', vdevno=5,
size=524288, cntrltype=0, dsync=false, directio=true, skip_alloc= true
go
- Script de création du device "LOG" :
disk init name='MONLOG', physname='/LOG/SYBTMP/MONLOG.dat', vdevno=6, size=262144,
cntrltype=0, dsync=false, directio=true, skip_alloc= true
go
- Script de création de la base de données "MABASE" :
create database MABASE on MABASE = 1024 log on MONLOG = 512 with DURABILITY=FULL - Script de création du user "test" :
use master
go
exec sp_addlogin 'test', 'testpw', @defdb = 'MABASE', @deflanguage = 'french',
@auth_mech = 'ANY', @fullname='User pour tests'
go
- Donner la propriété de la base au user "test"
USE MABASE
go
exec sp_changedbowner 'test', true
go
Quelques "trucs" :
- Démarrer le serveur Sybase :
cd /opt/sybase
nohup ./ASE-15_0/install/RUN_COMSYB15
On peut lancer de la même façon le "Backup server" (RUN_COMSYB15_BS) ou le "Monitor Server" (RUN_COMSYB15_MS).
- Stopper le serveur Sybase
isql -U user_stop -S COMSYB15 -P mot_de_passe <<!FINI
shutdown SYB_BACKUP
go
shutdown
go
exit
!FINI
Les scripts nécessaires sont fournis en pièces attachées (root : "sybase" à installer dans /etc/init.d, sybase "start_stop_sybase" à installer dans /home/sybase/bini en enlevant le suffixe ".txt" des fichiers, sans oublier le "chown +x ..." qui va bien).
- Se connecter avec "isql" :
isql -Usa -P -Snom_serveur -D nom_de_la_base
Installation des outils nécessaires pour accéder à la base par JDBC.
Il est nécessaire d'installer un ensemble de tables dans la base "master" afin que la connexion JDBC soit possible sur la base, il existe deux versions de "JConnect" dans les répertoires de Sybase 15 : JConnect 6 et JConnect 7. Ici j'ai décidé d'installer la version 7.
Ill faut aller dans le répertoire "/opt/sybase/jConnect-7_0/sp" et de lancer le script qui va avec la version de la base, ici le script "sql_server15.0.sql" à lancer par :
isql -U sa -S COMSYB15 -i sql_server15.0.sql -o MONLOG.LOG
(répondre "Entrée" à la demande de mot de passe). Il est ensuite possible de se connecter en JDBC aux différentes bases de données contenues dans cette instance.
Sybase : mini test
Sybase : mini test jppLe mini test a été réalisé selon la procédure décrite ici.
Calcul de la différence de dates :
set statistics time on
go
select min(convert(datetime,DATEC)) as MINI,
max(convert(datetime,DATEC)) as MAXI,
datediff(day,min(convert(datetime,DATEC)),max(convert(datetime,DATEC))) as DIFF,
count(*) as CTR
from xen_stat_v2
go
Génération de la table table temporaire :
set statistics time on
go
select convert( char(10),dateadd(day, DELTA ,convert(datetime,DATEC)),112) as DATEC, HEUREC,SERVEUR,DOMNOM,DELTACPU,DELTARX,DELTATX,CPUPCT,NBSECR,NBSECW
into toto
from xen_stat_v2
go
Insertion des rangs calculés :
insert into xen_statv2 select * from toto
go
Après quelques itérations on arrive au volume voulu :
1> select count(*) from xen_stat_v2
2> go
Temps d'analyse et de compilation 0.
Adaptive Server cpu time: 0 ms.
Temps d'analyse et de compilation 0.
Adaptive Server cpu time: 0 ms.
-----------
13174976
Temps d'execution 18.
Adaptive Server cpu time: 1800 ms. Adaptive Server elapsed time: 22970 ms.
Soit un peu moins de 23 secondes.
La taille atteinte par le "LOG" est assez conséquente, à cause des ordres insert et a nécessité la mise en place d'un log de 1536Mo pour que le dernier ordre "insert" atteigne la fin,. On a quand même inséré plus de 6,5 millions de lignes.
Le volume occupé par la table et ses deux index est d'environ 2200Mo.
Résultats du mini test.
- Test 1 création de deux index :
Adaptive Server cpu time: 287300 ms. Adaptive Server elapsed time: 417160 ms.
Adaptive Server cpu time: 240100 ms. Adaptive Server elapsed time: 400633 ms.
Soit un total de #818 secondes ou 13'38 ".
- Test 2 re-calcul des statistiques :
update statistics MABASE.dbo.xen_stat_v2
go
Adaptive Server cpu time: 0 ms. Adaptive Server elapsed time: 165280 ms.
Le CPU est à >98% durant tout le calcul qui dure 1'45".
- Test 3 quelques "select" :
a) select DOMNOM,count(*) from xen_stat_v2 group by DOMNOM order by DOMNOM
go
- passe 1 : Adaptive Server cpu time: 0 ms. Adaptive Server elapsed time: 35983 ms
- passe 2 : Adaptive Server cpu time: 0 ms. Adaptive Server elapsed time: 34093 ms.
Soit #35 secondes
b) select DOMNOM,count(*) from xen_stat_v2 group by DOMNOM order by DOMNOM
go
- passe 1 : Adaptive Server cpu time: 28900 ms. Adaptive Server elapsed time: 88873 ms.
- passe 2 : Adaptive Server cpu time: 0 ms. Adaptive Server elapsed time: 81843 ms.
Soit #85 secondes
Sur ces deux tests le CPU monte à plus de 98%
Clickhouse : une performance étonnante
Clickhouse : une performance étonnante jppJ'ai découvert, un peu par hasard, l'existence de cette base de données, c'est dans l'interface de Ntopng que j'ai vu que l'enregistrement des données dans Mysql était "deprecated" et ne serait pas poursuivi dans la prochaine version.
C'est un peu dommage car MariaDB/Mysql est un standard incontournable, mais Clickhouse semble néanmoins présenter quelques avantages, notamment au niveau de la performance.
J'ai donc décidé de voir un peu les caractéristiques de cette base Clickhouse.
Ce groupe d'article présente, un peu, les caractéristiques de cette nouvelle base au moins au niveau des performances.
Clickhouse propose deux "consoles" sur deux ports différents :
- Une à la syntaxe Clickhouse parfois un peu particulière.
- Une à la syntaxe MariaDB/Mysql qui permet un abord plus immédiat.
La plupart des tests réalisés dans ce groupe d'articles ont été réalisés avec la console "Mysql".
Clickhouse : installation
Clickhouse : installation drupadminIl existe un dépôt pour Debian 11 géré directement par Clickhouse, l'installation sera donc simple.
Afin de ne pas risquer de "polluer" une machine existante j'ai décidé d'installer une machine virtuelle KVM munie d'un "gros" disque car j'avais dans l'idée d'y charger une grosse table, (justement mes archives de Ntopng) qui fait plus de 600 millions de rangs (6 ans d'archives).
La machine comportait au démarrage :
CPU : 4 VCPU
Disque : #400Go
RAM = 6 Go
Ajouter la clef GPG de clickhouse (en root) :
apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 8919F6BD2B48D754
Ajouter un fichier "clickhouse.list" dans /etc/apt/sources.list.d contenant :
deb https://packages.clickhouse.com/deb stable main
Il suffira alors d'un "apt update" et tout sera prêt pour lancer l'installation :
apt install --force-overwrite clickhouse-client clickhouse clickhouse-common clickhouse-common-static clickhouse-server clickhouse-tools
Note : J'ai été obligé d'utiliser --forcce-overwrite à cause du paquet clickhouse-tools.
L'installation s'est bien passée et tout a fonctionné rapidement, le fichier "service" pour systemd est bien sûr disponible. Le serveur dispose de plusieurs ports dédiés à :
Port natif
Port Mysql like
Port Postgresql like
Il est ainsi possible d'utiliser une syntaxe connue telle de Mysql/MariaDB ou Postgresql.
Je me suis concentré sur la syntaxe Mysql que je connais mieux que celle de Postgres. J'ai donc pu créer rapidement un utilisateur dédié, les bases de données et les tables dont j'avais besoin.
On peut même créer une base "virtuelle" reliée directement à une base Mysql/MariaDB.
Mon seul problème a été la taille de RAM allouée à cette machine, les 6Go se sont vite avérés insuffisants, le chargement des données ne dépassait pas 100 millions de rangs ...
Après quelques tâtonnements j'ai vu qu'il ne fallait pas être avare avec la RAM pour obtenir un fonctionnement sans plantage. Lors des chargements de données des "Segmentation fault" et lors de l'exécution d'ordres SQL des plantages pour "(MEMORY_LIMIT_EXCEEDED)".
j'ai donc, par paliers, augmenté la RAM jusqu'à un fonctionnement impeccable obtenu dès 24Go que j'ai un peu poussé à 28Go pour pouvoir charger sans problèmes ma "grosse" table.
28 Go cela fait déjà une jolie VM heureusement que la machine "support" dispose de 64Go !
Clickhouse : premier contact
Clickhouse : premier contact jppJ'ai lu quelques doc, mais ce qui m'a intéressé c'est la compatibilité avec la syntaxe Mysql.
Pour l'utiliser pleinement il suffit de connecter son client mysql favori (a installer si besoin) sur le port 9004. Je me suis alors retrouvé dans un environnement "connu" qui m'a permis de faire les premières manips.
Créer une nouvelle base de données : "CREATE DATABASE toto;"
Aller voir dans cette base : "use toto;"
Créer un utilisateur avec les droits d'administration :
create user administrateur identified by 'le_mot_de_passe_qui_tue';
grant all on *.* to administrateur;
Par contre pour créer une table il faut se plier à la syntaxe "locale", les types ne sont pas tout à fait les mêmes et il faut un peu "ruser".
Le "CREATE TABLE" n'offre aucun mystère.
Pour le "ENGINE" à utiliser il y en a plusieurs j'ai utilisé le plus "simple" : "MergeTree" avec les majuscules pour lequel il faut préciser un "order by xxx" et éventuellement un partitionnement.
Je n'ai pas testé le partitionnement, pas encore ...
Pour les champs numériques : int16,int32,int64; UInt16, UInt32 ...
Pour les champs date : Datetime fonctionne bien
Pour les champs alphanumériques : String.
Ne pas oublier de préciser "Nullable(type)" pour les champs qui peuvent prendre la valeur NULL.
En ce qui concerne les fonctions (par exemple celles sur les dates) la syntaxe est, malheureusement, différente de celle proposée par Mysql/MariaDB.
Une fonction particulièrement intéressante pour communiquer avec des bases Mysql/MariaDB est la possibilité de création de bases "distantes". Cette possibilité est analogue aux fonctionnalités accessibles à l'aide du module "federated" de MariaDB.
Il devient ainsi possible de récupérer directement dans Clickhouse des données d'une base extérieure. C'est cette fonctionnalité que j'ai utilisée pour importer la grosse table destinée aux essais.
La syntaxe est très simple (connexion sur le port "Mysql" :
CREATE TABLE toto as select * from base_distante.table.
Clickhouse : charger table test
Clickhouse : charger table test jppLe chargement de la table va être possible en utilisant des ordres SQL (syntaxe Mysql) avec :
- Création d'une base distante
- Création d'une table locale
- Insertion dans la table locale des rangs de la table distante.
La création d'une base distante possède une syntaxe proche de celle utilisée par les tables "federated" :
CREATE DATABASE base_distante
ENGINE = MySQL('IP:3306',
'nom_base_distante',
'user distant', 'mot_de_passe_distant')
SETTINGS read_write_timeout=10000, connect_timeout=10;
Il est alors possible de faire un "SELECT" sur la base distante.
La recopie d'une table devient :
insert into base_locale.nom_table
select * from base_distante.nom_table
where idx > 0 ;
Pour une table volumineuse le temps peut être assez important. Dans mon cas le transfert entre la MV et la machine physique atteignait 130Mo/seconde et le temps total de chargement de plus de 500 millions de rangs a duré un peu moins d'une heure.
Dans la base MariaDB cette table utilise environ 300GO, Dans la base Clickhouse le volume est d'un peu plus de 140GO. Visiblement la compression semble bien fonctionner.
Clickhouse : Test 1
Clickhouse : Test 1 jppPour ce premier test sur cette "grosse" table j'ai repris un ordre SQL dont je m'étais servi pour repérer les plus gros scanneurs. Je rappelle que cette table contient des données enregistrées par Ntopng sur ma machine "pont" vers Internet. Et les scans de port sont extrêmement courants, chaque machine connectée à Internet en subit plusieurs centaines par jour.
Cet ordre examine toutes les données d'entrée qui n'ont donné lieu à aucune réponse (port fermé ou IP bloquée par le firewall) la sortie est limitée aux 20 plus "gros scanneurs".
select IP_SRC_ADDR as IP_V4,count(*) as CTR,
count(distinct L4_DST_PORT) as NBPORTS,
min(FIRST_SWITCHED) as DEBUT,max(LAST_SWITCHED) as FIN
from flowsv4
where IP_SRC_ADDR not between '192.158.1.1' and '192.168.3.255'
and OUT_BYTES = 0
group by 1
order by 2 desc
limit 20;
Et voici les résulats :
1) Pour Clickhouse :
| ┌─IP_V4───────────┬────CTR─┬─NBPORTS─┬───────────────DEBUT─┬─────────────────FIN─┐ │ 0.0.0.0 │ 133379 │ 2 │ 2016-08-02 21:20:07 │ 2022-08-27 00:13:06 │ │ 45.143.220.101 │ 80996 │ 64408 │ 2020-03-22 22:19:49 │ 2020-04-17 02:14:24 │ │ 92.63.197.23 │ 65295 │ 65295 │ 2021-09-17 22:38:39 │ 2021-09-24 05:22:53 │ │ 45.143.200.34 │ 46036 │ 25699 │ 2021-04-09 23:14:37 │ 2022-02-10 21:25:53 │ │ 173.231.60.195 │ 44355 │ 2 │ 2021-12-09 06:09:06 │ 2022-03-09 13:07:02 │ │ 92.63.197.108 │ 38179 │ 32243 │ 2021-08-22 13:29:04 │ 2021-11-25 04:31:09 │ │ 146.88.240.4 │ 37229 │ 63 │ 2019-04-11 04:59:05 │ 2022-08-26 06:02:19 │ │ 92.63.197.112 │ 36060 │ 32081 │ 2021-08-22 13:27:51 │ 2021-11-25 10:31:34 │ │ 92.63.197.110 │ 35671 │ 29999 │ 2021-08-22 13:29:24 │ 2022-07-10 12:52:55 │ │ 212.70.149.69 │ 35319 │ 1 │ 2020-10-19 04:34:22 │ 2020-12-18 12:52:19 │ │ 10.128.175.2 │ 33844 │ 1 │ 2018-06-02 05:03:16 │ 2020-07-01 12:23:01 │ │ 176.113.115.246 │ 33618 │ 32906 │ 2020-01-29 09:24:25 │ 2020-05-09 20:52:01 │ │ 212.70.149.68 │ 32400 │ 1 │ 2020-08-21 04:34:36 │ 2020-10-16 20:38:35 │ │ 185.176.27.2 │ 32322 │ 22565 │ 2018-12-06 17:13:49 │ 2020-08-12 23:43:46 │ │ 92.154.95.236 │ 31960 │ 1092 │ 2017-12-07 23:05:08 │ 2021-12-13 13:30:54 │ │ 185.156.73.91 │ 31756 │ 20609 │ 2020-10-04 03:09:37 │ 2022-08-26 23:44:13 │ │ 185.156.73.107 │ 31625 │ 25338 │ 2021-06-19 09:04:14 │ 2022-02-13 12:30:53 │ │ 195.54.166.93 │ 31183 │ 29850 │ 2020-01-15 21:46:51 │ 2020-02-17 05:38:35 │ │ 51.68.126.248 │ 30228 │ 4 │ 2020-02-25 22:40:19 │ 2020-04-06 01:24:36 │ │ 92.63.197.105 │ 29300 │ 16042 │ 2021-05-16 17:24:56 │ 2021-12-07 23:21:30 │ └─────────────────┴────────┴─────────┴─────────────────────┴─────────────────────┘ 20 rows in set. Elapsed: 6.138 sec. Processed 488.52 million rows, 18.98 GB (79.59 million rows/s., 3.09 GB/s.) |
2) Pour MariaDB :
| +-----------------+--------+---------+---------------------+---------------------+ | IP_V4 | CTR | NBPORTS | DEBUT | FIN | +-----------------+--------+---------+---------------------+---------------------+ | 0.0.0.0 | 133379 | 2 | 2016-08-02 21:20:07 | 2022-08-27 00:13:06 | | 45.143.220.101 | 80996 | 64408 | 2020-03-22 22:19:49 | 2020-04-17 02:14:24 | | 92.63.197.23 | 65295 | 65295 | 2021-09-17 22:38:39 | 2021-09-24 05:22:53 | | 45.143.200.34 | 46036 | 25699 | 2021-04-09 23:14:37 | 2022-02-10 21:25:53 | | 173.231.60.195 | 44355 | 2 | 2021-12-09 06:09:06 | 2022-03-09 13:07:02 | | 92.63.197.108 | 38179 | 32243 | 2021-08-22 13:29:04 | 2021-11-25 04:31:09 | | 146.88.240.4 | 37229 | 63 | 2019-04-11 04:59:05 | 2022-08-26 06:02:19 | | 92.63.197.112 | 36060 | 32081 | 2021-08-22 13:27:51 | 2021-11-25 10:31:34 | | 92.63.197.110 | 35671 | 29999 | 2021-08-22 13:29:24 | 2022-07-10 12:52:55 | | 212.70.149.69 | 35319 | 1 | 2020-10-19 04:34:22 | 2020-12-18 12:52:19 | | 10.128.175.2 | 33844 | 1 | 2018-06-02 05:03:16 | 2020-07-01 12:23:01 | | 176.113.115.246 | 33618 | 32906 | 2020-01-29 09:24:25 | 2020-05-09 20:52:01 | | 212.70.149.68 | 32400 | 1 | 2020-08-21 04:34:36 | 2020-10-16 20:38:35 | | 185.176.27.2 | 32322 | 22565 | 2018-12-06 17:13:49 | 2020-08-12 23:43:46 | | 92.154.95.236 | 31960 | 1092 | 2017-12-07 23:05:08 | 2021-12-13 13:30:54 | | 185.156.73.91 | 31756 | 20609 | 2020-10-04 03:09:37 | 2022-08-26 23:44:13 | | 185.156.73.107 | 31625 | 25338 | 2021-06-19 09:04:14 | 2022-02-13 12:30:53 | | 195.54.166.93 | 31183 | 29850 | 2020-01-15 21:46:51 | 2020-02-17 05:38:35 | | 51.68.126.248 | 30228 | 4 | 2020-02-25 22:40:19 | 2020-04-06 01:24:36 | | 92.63.197.105 | 29300 | 16042 | 2021-05-16 17:24:56 | 2021-12-07 23:21:30 | +-----------------+--------+---------+---------------------+---------------------+ 20 rows in set (12 min 56,412 sec) |
3) Comparaison.
Les résultats sont identiques ce qui est très bien !
La comparaison est impressionnante : 6 secondes au lieu de 776 soit quasiment 130 fois plus vite !
On voit aussi que l'adresse IP 45.143.220.101 a scanné quasiment l'intégralité des ports existants en un peu moins d'un mois (scan "lent") ou que l'IP 173.231.60.195 ne scanne que deux ports mais a effectué plus de 40000 connexions en un peu moins d'un an, cela fait quand même plus de 100 par jour.
Clickhouse : Test 2
Clickhouse : Test 2 jppCet ordre SQL devait me permettre de voir s'il y avait des trous de numérotation dans les valeurs du champ "idx".
Il m'a valu de nombreux ennuis avant que la mémoire ne soir "gonflée" avec de méchants messages :
Received exception from server (version 22.8.2):
Code: 241. DB::Exception: Received from localhost:9000. DB::Exception: Memory limit (total) exceeded: would use 3.73 GiB (attempt to allocate chunk of 537537181 bytes), maximum: 3.48 GiB. OvercommitTracker decision: Query was selected to stop by OvercommitTracker.: While executing AggregatingTransform. (MEMORY_LIMIT_EXCEEDED)
L'ordre est très simple :
select min(idx),max(idx), count(distinct idx) from flowsv4;
Dès que la RAM a été "suffisante" (plus de 24Go de RAM) ces messages ont disparu et les résultats sont là et bien là.
1) Résultats Clickhouse.
┌─min(idx)─┬──max(idx)─┬─uniqExact(idx)─┐
│ 1 │ 488553902 │ 488521496 │
└──────────┴───────────┴────────────────┘
1 row in set. Elapsed: 27.822 sec. Processed 488.52 million rows, 3.91 GB (17.56 million rows/s., 140.47 MB/s.)
2) Résultats MariaDB.
+----------+-----------+---------------------+
| min(idx) | max(idx) | count(distinct idx) |
+----------+-----------+---------------------+
| 1 | 488553902 | 488521496 |
+----------+-----------+---------------------+
1 row in set (5 min 42,522 sec)
3) Résultat final.
27 secondes contre 342 soit environ 13 fois plus vite.
Clickhouse : Test 3
Clickhouse : Test 3 jppLe but de cet ordre SQL est de trouver les adresses IP qui ont contacté sans succès la machine, ceci est identifié par une valeur 0 dans le champ OUT_BYTES et qui ont "tenté" des connexions sur au moins 10 ports différents. Ceci peut arriver si la demande a été bloquée par le firewall (drop).
L'ordre SQL est légèrement différent car les fonctions de gestion des dates ont des syntaxes légèrement différentes.
| select IP_SRC_ADDR as SRC,IP_DST_ADDR as DST, count(distinct L4_DST_PORT) as NPORT from flowsv4 -- mariadb where FIRST_SWITCHED > DATE_SUB(now(), interval 20 day) -- clickhouse where FIRST_SWITCHED > DATE_SUB(DAY,20,now()) and IP_SRC_ADDR not between '192.168.1.1' and '192.168.3.255' and L4_DST_PORT < 15000 group by SRC,DST having NPORT > 10 order by SRC; |
La différence n'est pas énorme mais il faut y faire attention ...
Et maintenant passons aux faits.
1) Clickhouse.
| ┌─SRC─────────────┬─DST─────────┬─NPORT─┐ │ 103.138.109.220 │ 192.168.1.2 │ 105 │ │ 103.56.61.144 │ 192.168.1.2 │ 12 │ │ 104.156.155.13 │ 192.168.1.2 │ 1216 │ │ 104.168.53.114 │ 192.168.1.2 │ 23 │ ...... │ 94.232.45.241 │ 192.168.1.2 │ 68 │ │ 95.161.131.235 │ 192.168.1.2 │ 19 │ └─────────────────┴─────────────┴───────┘ 377 rows in set. Elapsed: 0.120 sec. Processed 7.92 million rows, 395.57 MB (66.10 million rows/s., 3.30 GB/s.) |
2) MariaDB.
| +-----------------+-------------+-------+ | SRC | DST | NPORT | +-----------------+-------------+-------+ | 103.138.109.220 | 192.168.1.2 | 105 | | 103.56.61.144 | 192.168.1.2 | 12 | | 104.156.155.13 | 192.168.1.2 | 1216 | | 104.168.53.114 | 192.168.1.2 | 23 | ...... | 94.232.45.241 | 192.168.1.2 | 68 | | 95.161.131.235 | 192.168.1.2 | 19 | +-----------------+-------------+-------+ 377 rows in set (19,137 sec) |
3) Comparaison.
Le rapport entre 19 secondes et 0.12 est frappant, Clickhouse est 158 fois plus rapide.
Clickhouse : Test 4
Clickhouse : Test 4 jppCet ordre SQL est très simple et le résultat est plus que spectaculaire, le passage "Clickhouse" a été réalisé avec l'interface compatible Mysql.
L'ordre est très simple :
select count(*),max(LAST_SWITCHED),max(FIRST_SWITCHED) from flowsv4;1) Résultats Clickhouse.
+-----------+---------------------+---------------------+
| count() | max(LAST_SWITCHED) | max(FIRST_SWITCHED) |
+-----------+---------------------+---------------------+
| 521129534 | 2022-11-17 23:35:18 | 2022-11-17 23:35:18 |
+-----------+---------------------+---------------------+
1 row in set (1.863 sec)
2) Résultats MariaDB.
+-----------+--------------------+---------------------+
| count(*) | max(LAST_SWITCHED) | max(FIRST_SWITCHED) |
+-----------+--------------------+---------------------+
| 521129338 | 1668724485 | 1668724485 |
+-----------+--------------------+---------------------+
1 row in set (13 min 40,620 sec)3) Résultat final.
1,85 secondes pour Clickhouse contre 820 pour MariaDB soit environ 440 fois plus vite !
Clickhouse : Test 5
Clickhouse : Test 5 jppJ'ai voulu faire un dernier test qui représente un gros travail toujours à partir de la même table qui atteint maintenant 542 975 185 rangs ce qui représente un bon test.
J'ai voulu chercher les ports TCP les plus attaqués en sélectionnant les connections TCP qui ont fourni un retour de 0 octets, le SQL est donc :
select L4_DST_PORT,count(*) CTR
from local_ntopng.flowsv4
where OUT_BYTES = 0 -- aucune réponse
and PROTOCOL = 6 -- (TCP)
group by 1
order by CTR DESC
limit 30;Le résultat est, là aussi, stupéfiant :
Pour Clickhouse les 30 rangs sont retournés en moins de deux secondes (1;813 exactement et en 14 minutes et 18 secondes soit 858 secondes, le rapport de vitesse est proprement stupéfiant ... Clickhouse va 473 fois plus vite que MariaDB.
Rappels :
- Les tests sont faits sur la même machine et les données sont sur les deux disques Samsung SSD 860 de 2To montés en miroir.
- Les résultats présentent de très légères différences car la recopie des données depuis la source n'est pas "synchrone", il y a donc un (tout petit) décalage possible.
Voir les résultats ci-dessous.
| CLICKHOUSE 1.813 sec | MariaDB 14 min 18 se | ||
|
443 |
1434014 |
443 |
1434014 |
|
80 |
1059068 |
80 |
1059067 |
|
23 |
749049 |
23 |
749049 |
|
445 |
253752 |
445 |
253752 |
|
22 |
229300 |
22 |
229300 |
|
465 |
184397 |
465 |
184397 |
|
6379 |
163679 |
6379 |
163679 |
|
8080 |
143206 |
8080 |
143205 |
|
1433 |
116601 |
1433 |
116600 |
|
81 |
85489 |
81 |
85489 |
|
3389 |
85076 |
3389 |
85075 |
|
5222 |
77222 |
5222 |
77222 |
|
25 |
74815 |
25 |
74815 |
|
2323 |
65065 |
2323 |
65065 |
|
995 |
62827 |
995 |
62827 |
|
|
|||
Syntaxe Sql
Syntaxe Sql jppIl est possible, avec un client Mysql/MariaDB standard, de se connecter à Clickhouse (port 9004) et d'utiliser des ordres SQL avec la syntaxe propre à Mysql/MariaDB.
Il existe aussi une possibilité d'utiliser un client Postgresl en se connectant à Clickhouse (port 9005), je n'ai pas encore testé cette entrée.
On peut par exemple créer un utilisateur avec :
create user lechef identified by 'le_beau_password';
grant all on *.* to lechef;
Ce que je préfère nettement au "bidouillage" de fichiers XML.
Par exemple pour charger ma "grosse" table depuis une base MariaDB dans Clickhouse (dans une machine virtuelle) j'ai créé dans Clickhouse un "serveur" connecté à la base située sur la machine "physique" à l'aide d'un ordre "simple" (du même style que pour l'option "federatedx" disponible dans MariaDB :
CREATE DATABASE test_maria
ENGINE = MySQL('192.168.2.7:3306',
'local_ntopng',
'test', 'test')
SETTINGS read_write_timeout=10000, connect_timeout=10;
Dans la base "physique" la table est au standard Mysql et on peut donc y accéder à travers cette base "test_maria" par cette sorte de "dblink". L'ordre de chargement des données est très simple :
insert into local_ntopng.flowsv4
select * from test_maria.flowsv4;
select min(idx),max(idx),count(distinct idx) from local_ntopng.flowsv4;
Le temps d'exécution est assez important car il faut passer par :
- Mariadb sur la machine physique
- Le réseau entre les deux machines
- Et enfin Clickhouse à travers le fameux dblink.
Comme déjà remarqué la consommation d'IO disques de Clickhouse est très irrégulière et a oscillé entre 0 et 240Mo/seconde. Le lien réseau est toujours resté au dessus de 100MO/sec avec des pointes à près de 200MO/sec (c'est en local sur la même machine physique).
Les résultats :
Query OK, 505751818 rows affected (36 min 54.958 sec)
+----------+-----------+----------------+
| min(idx) | max(idx) | uniqExact(idx) |
+----------+-----------+----------------+
| 1 | 505785066 | 505751818 |
+----------+-----------+----------------+
1 row in set (31.284 sec)
Ce qui n'est pas mauvais et simple pour ceux qui connaissent un peu le SQL.
Syntaxe SQL : suite
Syntaxe SQL : suite jppJ'ai eu besoin de modifier la notion "Nullable" d'une colonne, or il semble que ce soit impossible.
La table que j'ai utilisée pour les premiers tests comporte toutes les colonnes en Nullable ce qui peut gêner certains types d' opérations.
J'ai donc initialisé une nouvelle table avec les colonnes adéquates en "not null" et j'y ai inséré les lignes de l'ancienne table.
Au passage une remarque sur la syntaxe :
- Une colonne "nullable" se déclare sous la forme "Nullable(String)"
- La même en "not null" se déclare sous la forme plus classique "String not null".
La recopie est une opération simple
insert into table1 select * from table2;J'ai donc lancé cet ordre en direct sur cette table de 540 Millions de rangs et le résultat est :
Elapsed: 817.372 sec. Processed 524.04 million rows, 200.88 GB
(641.13 thousand rows/s., 245.76 MB/s.)Soit quand même plus de 13 minutes ...
CPU > 90 .. 130%
IO 60 .. 370 Mo/seconde la moitié du temps en lecture, l'autre moitié en écriture.Pour se débarrasser de l'ancienne table :
- sudo touch /var/lib/clickhouse/flags/force_drop_table
- sudo chmod 666 /var/lib/clickhouse/flags/force_drop_table
- Puis, enfin dans le shell Clickhouse.
"drop ancienne_table"
Null ou pas Null
Null ou pas Null jppJ'ai eu besoin de modifier la notion "Nullable" d'une colonne car il est impossible d'utiliser "GROUP BY" sur une colonne "Nullable", or il semble que ce soit impossible avec une commande "ALTER" standard.
J'ai donc initialisé une nouvelle table avec les colonnes adéquates en "not null" et j'y ai inséré les lignes de l'ancienne table.
Au passage une remarque sur la syntaxe (pas "standard" ?) :
- - Une colonne "nullable" se déclare sous la forme "Nullable(String)"
- - La même en "not null" se déclare sous la forme plus classique "String not null".
La notion de longueur de chaîne de caractères est ici inconnue.
La recopie est une opération simple :
insert into table1 select * from table2;J'ai donc lancé cet ordre en direct sur cette table de plus de 520 Millions de rangs et le résultat est :
Elapsed: 817.372 sec. Processed 524.04 million rows, 200.88 GB
(641.13 thousand rows/s., 245.76 MB/s.)Soit malgré tout plus de 13 minutes et demi ... mais pour autant de millions de lignes c'est une bonne performance.
Rappel :
la machine dispose de 28Go de RAM et de 4 VCPU ainsi que l'accès à un espace de stockage sur une paire de SSD en Raid 1.
Avec des disques plus rapides, par exemple 4 NVME en Raid 10 on atteindrait des sommets. Avec un tel système disques j'ai vu des vitesses d'écriture à plus de 1,5Go/sec, hélas ce n'est pas à la portée de toutes les bourses et même impossible sur la majorité des cartes mères "amateurs".
Au cours de cette copie j'ai pu constater :
CPU de 90 .. 130%
IO 60 .. 370 Mo/seconde la moitié du temps en lecture, l'autre moitié en écriture.Pour se débarrasser de l'ancienne table :
- sudo touch /var/lib/clickhouse/flags/force_drop_table
- sudo chmod 666 /var/lib/clickhouse/flags/force_drop_table
- Puis, enfin, le "drop ancienne_table" dans le shell Clickhouse.
Il n'est pas si facile que cela de se débarrasser d'une table encombrante...
Quelques particularités
Quelques particularités jppNote spécifique :
La mémoire « huge pages » peut être utilisée mais, au niveau du noyau, le paramètre « transparent_hugepages » ne doit pas être à « always », « madvise » est plus judicieux ici et de toutes façons tout le monde ne met pas en "huge pages" la quantité de mémoire nécessaire.
Clickhouse est un gros mangeur de mémoire et manifeste bruyamment son désaccord s’il ne dispose pas de la mémoire nécessaire à ses opérations.
Au cours de mes essais, commencés avec une mémoire « faible » (6144Mo), je me suis heurté à quelques plantages pour des questions de mémoire.
La plupart de ces problèmes ont eu lieu lors des tests de chargement à l’aide de l’utilitaire « clickhouse-mysql ».
J’ai obtenu plusieurs fois (au fur et à mesure de l’augmentation de la taille mémoire de la machine virtuelle) le message suivant :
Segmentation fault clickhouse-mysql
Dès que la mémoire a été « suffisante » cette erreur a disparu.
Autre type d’erreur rencontrée lors de l’exécution d’un ordre SQL simple (toujours avec une mémoire "insuffisante") permettant de repérer la quantité de « trous » dans la numérotation :
select min(idx),max(idx), count(distinct idx) from flowsv4;
Avant les augmentations de mémoire et sur une table partiellement chargée (de 100 à 260 millions de rangs) on obtient un stop brutal de l’ordre SQL avec quelques messages :
Received exception from server (version 22.8.2):
Code: 241. DB::Exception: Received from localhost:9000. DB::Exception: Memory limit (total) exceeded: would use 3.73 GiB (attempt to allocate chunk of 537537181 bytes), maximum: 3.48 GiB. OvercommitTracker decision: Query was selected to stop by OvercommitTracker.: While executing AggregatingTransform. (MEMORY_LIMIT_EXCEEDED)
Dès que la mémoire est « suffisante » et même avec une table de plus de 488 millions de rangs l’ordre s’exécute sans ennuis et avec une rapidité tout à fait satisfaisante :
┌─min(idx)─┬──max(idx)─┬─uniqExact(idx)─┐
│ 1 │ 488553902 │ 488521496 │
└──────────┴───────────┴────────────────┘
↙ Progress: 488.52 million rows, 3.91 GB (19.19 million rows/s., 153.56 MB/s.)
1 row in set. Elapsed: 25.530 sec. Processed 488.52 million rows, 3.91 GB (19.13 million rows/s., 153.08 MB/s.)
Alors que sur le même volume MariaDB attends à peine moins de 6 minutes avant de donner; heureusement, le même résultat.
Cas spécial du « drop table ».
Une protection existe contre le drop accidentel d’une table, cette protection (par défaut à 50GB) est gérée par le paramètre « max_table_size_to_drop ». Si vous gardez cette protection le drop d’une « grosse table » peut makgré tout être effectué en créant un fichier spécifique qui sera détruit après le drop (Eh oui, il ne peut servir qu'une fois) :
sudo touch /var/lib/clickhouse/flags/force_drop_table
sudo chown clickhouse: /var/lib/clickhouse/flags/force_drop_table
Il est alors possible d’effectuer le « drop » de cette "grosse" table.
Ce paramétrage peut sembler judicieux car le chargement de ces tables est assez consommateur de temps et on ne les charge pas uniquement pour les détruire.
Encore un test
Encore un test jppCe test montre assez bien la vitesse de Clickhouse.
La table "origine" est stockée sur une machine distante, les accès se font donc à travers le réseau.
Pour MariaDB utilisation de Federatedx pour accès à la base distante, pour Clickhouse la structure équivalente de base Mysql distante avec une syntaxe de création assez semblable à celle utilisée par MariaDB.
Résultats :
MariaDB :
Query OK, 1938339 rows affected (33,521 sec)
Enregistrements: 1938339 Doublons: 0 Avertissements: 0
Clickhouse :
Query OK, 1939250 rows affected (19.682 sec)
Le temps de transfert depuis la machine d'origine doit être à peu près le même car j'ai redémarré le service sur la machine d'origine pour éviter l'influence du cache.
Les ordres SQL sont identiques :
insert into local_ntopng.flowsv4
select * from portail_maria.flowsv4
where idx > ( select max(idx) from local_ntopng.flowsv4 );
Les deux tests utilisent un accès réseau vers la machine "origine" des données.
Bases connues
Bases connues jppParmi les bases de données les plus courantes :
Oracle
Cette base de données n'est plus à présenter, mais quelques informations pratiques suivent :
Je ne parlerais pas des versions antérieures .... pour les versions postérieures ... plus tard.
Mysql / MariaDB
La base probablement la plus connue et très utilisée, elle est tombée dans le giron d'Oracle il y a déjà quelques années et poursuit sa route accompagnée de son "clone" MariaDB qui est la continuation de la version initiale. Depuis la version 5 cette base de données est devenue "adulte" et réponds correctement aux critères relationnels.
Oracle
Oracle jppSérie d'articles, qui maintenant datent un peu, sur Oracle avec installation de diverses configurations sur des machines virtuelles Xen ou KVM.
XEN : Oracle10g
XEN : Oracle10g jppLe montage (NFS ou Samba) pour l'installation du logiciel Oracle 10 est en place, on peut alors se connecter en tant qu'utilisateur "oracle" et lancer le très fameux "./runInstaller" depuis le répertoire d'installation.
Dès le premier écran on est dans l'ambiance ... 
Sur lequel on clique "Installation avancée" pour pouvoir choisir nos options à loisir.
Premier écran "Répertoire d'inventaire" : 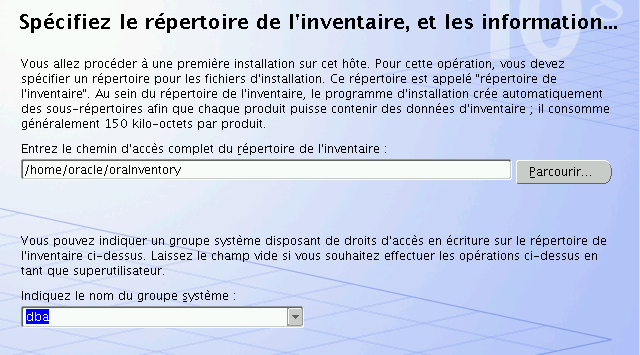
laisser le chemin du répertoire d'inventaire à la valeur proposée, Positionnez le groupe système à "dba".
Deuxième écran "Type d'installation", cocher "Entreprise Edition". C'est aussi ici que l'on peut ajouter des langues.
Troisième écran "Détails du répertoire d'origine Oracle Home",
les valeurs proposée me plaisent ... et on enchaine sur la vérification des paramètres qui me signale juste un avertissement pour mon espace de swap qui n'est pas égal ou supérieur à 1.5 * RAM, je passe à la suite en confirmant que j'ignore superbement cette remarque.
Dans quelques cas (cela vient de m'arriver), bien que tous les pré-requis soient marqués "success" il arrive qu'il faille "forcer" le passage en cliquant sur "Oui" dans la boite de dialogue qui vous signale un pré-requis non statisfait (?). Il s'agissait alors de la détection des interfaces réseau (pourtant pas en DHCP) ?
Quatrième écran "Option de configuration" : cocher "Créer une base de données".
Cinquième écran "Configuration de base de données" : cocher "Usage général", ce modèle est la plus adapté à nos besoins.
Sixième écran "Options de configuration de la base de données" : 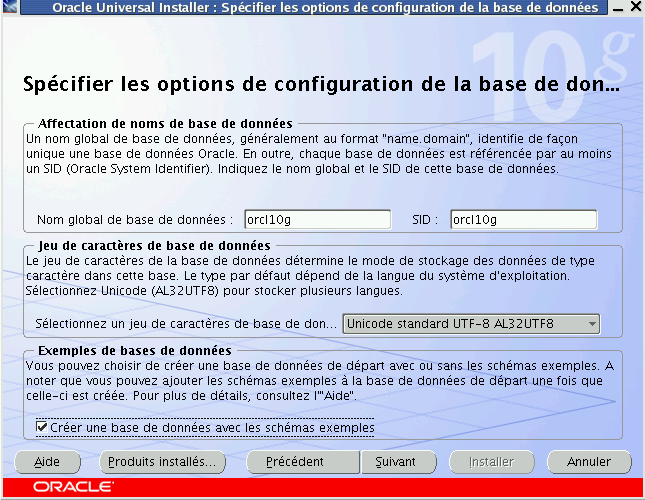
Ici on choisit le nom de la base de données, je la nomme "orcl10g".
Pour le jeu de caractères je sélectionne "Unicode standard UTF-8 AL32UTF8.
et je coche "Créer une base de données avec les schémas exemples".
Septième écran "Option de gestion de base de données" : cliquer "Utiliser le contrôle de base de données" ... et activer les notifications par mail en fournissant serveur de mail valide et adresse existante !
Huitième écran "Option de stockage de base de données" ; on clique "Système de fichiers" et on indique notre zone réservée "/DATA/u01".
Neuvième écran "Sauvegarde et récupération" : cocher "Ne pas activer les saubegardes automatiques".
Dixième écran : "Mots de passe" : je choisis "Utiliser le même mot de passe ..." et saisis un magnifique mot de passe ... et l'écran de résumé final s'affiche, 
on le vérifie pour éviter les surprises et on clique "Installer" et c'est parti :
Non, on ne clique pas "Arrêter l'installation" ! Le voyant disque clignote, cela doit avancer, la barre de progression aussi. Le link est en cours, c'est bon signe. On arrive aux assistants de configuration, Oracle Net s'est configuré tout seul,la création de la BDD démarre, c'est le pied : 
C'est fini, le récap s'affiche en nous rappelant la connexion pour Entreprise Manager : "http://com-ora10g:1158/em", c'est bien noté. On peut dans cet écran aller sur la gestion des mots de passe.
Et voici le moment des scripts à faire tourner en "root" 
et c'est exécuté en deux temps trois mouvements.
Enfin c'est terminé et l'écran de rappel apparait 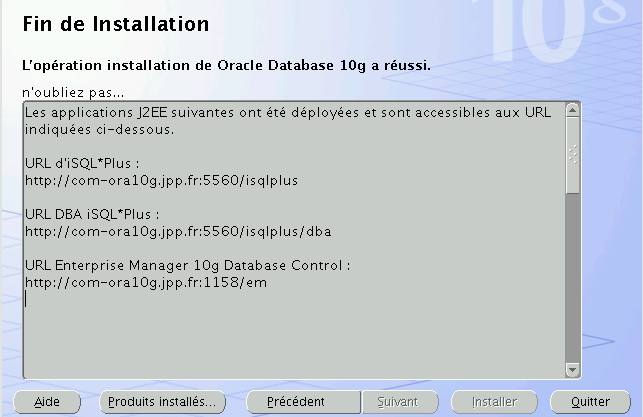
on note les info et on "Quitte".
Un petit "ps -ef' nous montre tous les processes oracle sagement en attente de boulot la "dbconsole" est lancée, on va voir si tout est OK 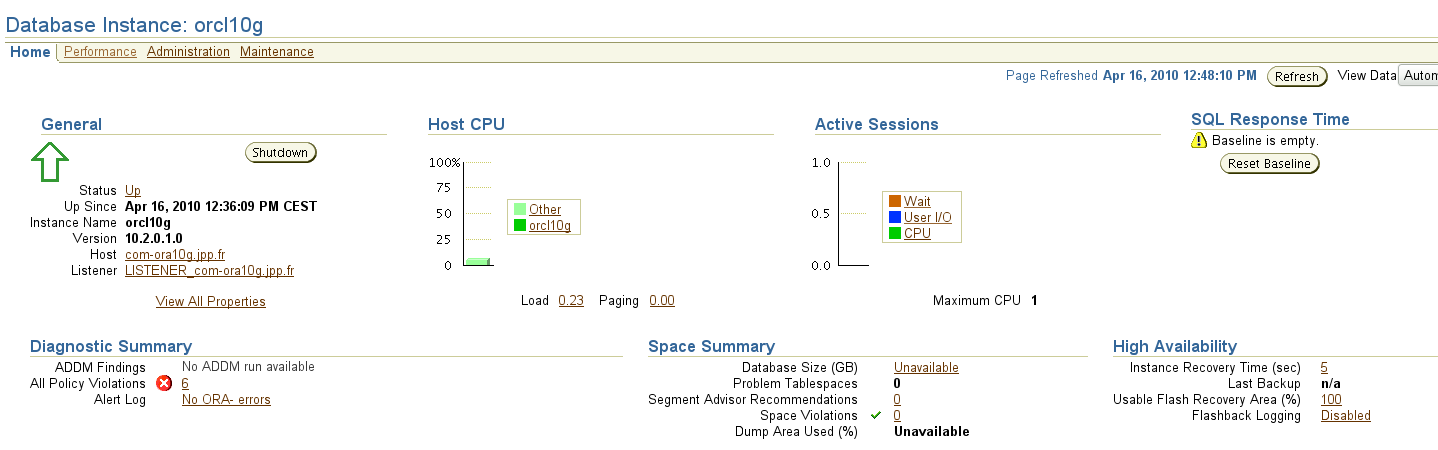
et cela semble bien être la cas.
On tente un reboot ... pour le prochain article.
Oracle ASM RAC
Oracle ASM RAC jppPlusieurs articles sur Oracle avec installation et tests de ASM et RAC.
Ces articles seront suivis de quelques tests.
Installation machine Oracle 11G (XEN)
Installation machine Oracle 11G (XEN) jppCe chapitre présente l'installation sous XEN d'une machine destinée à une installation de oracle11G.
La machine virtuelle XEN est dotée de :
- 1 CPU
- 3072 Mo de RAM
- 1 disque système de 16G
- 1 disque données de 40G
- 1 interface réseau
Le chapitre est divisé en plusieurs parties :
- Installation du Linux Oracle
- Installation des pré-requis
- Installation de Oracle
Xen : Installation d'un Linux Oracle
Xen : Installation d'un Linux Oracle jppJ'ai décidé d'installer une base ORACLE 11g pour ma formation personnelle et au passage de tester l'installation de la version "Oraclisée" de Linux en 64 bits.
Après téléchargement de la version 5.4 (# 4Go) et préparation d'une machine virtuelle :
- 2 processeurs
- Ram 3 Go
- Disque : un disque "système" de 16Go, un autre disque sera créé par la suite pour les données Oracle.
Ce disque est partitionné comme suit :
hda1 /boot 512Mo
hda2 LVM de 16,5Go divisé comme suit :
VOL00 / 12 Go
VOL01 swap 4 Go
Le fichier de description de cette machine virtuelle est attaché.
Au lancement de la machine le premier écran de boot s'affiche : 
Dans lequel je préfère prendre l'option "linux text" pour ne pas avoir de bugs d'affichage.
Après le lancement la procédure d'installation s'enchaine :
- Premier écran (ECRAN_001.png) choisir l'installation en mlode texte pour ne pas avoir de surprises.
- "CD Found" (vérification du CD) ressemble comme deux gouttes d'eau à celui de RedHat : on teste le CD pour vérifier son bon chargement, cela prends un peu de temps, mais cela rassure.
La vérification est bonne --> OK. - Ecran "Media check" : on n'a pas d'autre source d'installation --> Continue
- Ecran "Language Selection" --> French
- Ecran "Selection de clavier" --> fr-latin1
- Ecran "Type de partitionnement" --> Supprimer les partitions ... sur le seul disque connu "/dev/hda".

- Ecran "Avertissement", Oui on écrase le disque et on Continue
- Ecran "Examiner la structure de partitionnement" --> Oui
- Ecran "Partitionnement" l'écran propose Swap à 5Go et Data à 11 Go en LVM, je prefère un swap à 4Go seulement. Je modifie la taille du swap et automatiquement la taille des DATA passe à 12Go.
Je valide le tout --> OK - Ecran "Configuration du chargeur de démarrage" --> on utilise GRUB --> OK
- Ecran "Configuration du chargeur de démarrage" --> pas de forçage de LBA32 --> OK
- Ecran "Configuration du chargeur de démarrage" --> pas de mot de passe GRUB --> OK
- Ecran "Configuration du chargeur de démarrage" --> on utilise le seul volume dsponible --> OK
- Ecran "Configuration du chargeur de démarrage" --> laisser l'éiquette standard --> OK
- - "Configuration du chargeur de démarrage" --> on installe sur "/dev/hda" (MBR) --> OK
- Ecran "Configurer l'interface réseau" --> OUI
- Ecran "configuration réseau de eth0" --> Activer au démarrage, IPV4 seul --> OK
- Ecran "Configuration IPV4 pour eth0" --> Configuration adresse manuelle, fournir l'adresse/masque --> OK
- Ecran "Divers paramètres de réseau" --> Passerelle, DNS primaire et secondaire --> OK
- Ecran "Configuration du nom d'hôte" : "Manuellement" + nom machine --> OK
- Ecran "Sélection du fuseau horaire" --> Europe/Paris --> OK
- Ecran "Mot de passe root" --> mot de passe + confirmation --> OK
L'installation se lance et propose un premier niveau de personnalisation de la machine 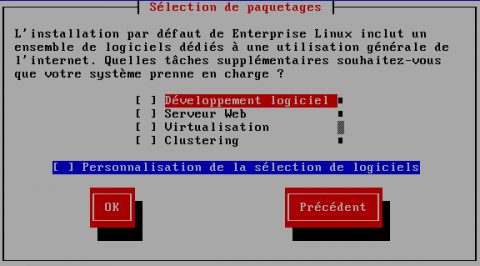
--> on sélectionne "Développement Logiciel" pour disposer des compilateurs et "Personalisation de la sélection des logiciels".
- Ecran "Package group Selection" : Sélectionner
- "Bibliothèques de développement",
- "Environnement de bureau Gnome",
- "Internet Graphique",
- "Outils d'administration",
- "Outils de configuration de serveur",
- "Outils de développement",
- "Outils système",
- "Système X Window",
- "Editeurs"
--> OK
L'installation débute alors réellement ... un écran de rappel vous signale que le log de l'installation sera disponible dans /root/install.log --> OK.
Et c'est enfin parti pour formater le disque et installer les paquetages : 
Après une quinzaine de minutes l'instant tant attendu : 
On redémarre le système (c'est un noyau 2.6.18), au bout d'une dizaine de secondes un écran de post installation apparait, il faut se dépêcher de configurer les services .... 
Par défaut au bout de 10 secondes le login apparaît à son tour.
Un premier test : le réseau est OK, la machine est accessible par ssh.
Mince, aucun écran graphique n'est disponible, le serveur X n'est pas configuré ou pas lancé.
On redémarre pour voir le premier écran de config :
Il permet de sélectionner les services à activer/désactiver, mais toujours pas d'interface graphique !
Le script de lancement de "gdm" n' pas été installé (??), j'en fabrique donc un petit et le lancement de mon script est concluant, l'accès XWindow fonctionne.
Mais seulement en 600x480, c'est un peu petit, après un petit tour dans le fichier /etc/X11/xorg.conf et un "stop/start" de mon petit script l'accès en 1024x768 est OK. C'est beaucoup plus confortable.
Après la mise en place des gadgets indispensables dans les panels Gnome je stoppe la machine pour en sauvegarder l'état.
XEN : Oracle 11gr2 avec ASM
XEN : Oracle 11gr2 avec ASM jppCet article a pour but de présenter une installation plus "perfectionnée" utilisant les dernières nouveautés (en fait ASM pour Automatic Storage Management date de la 10g) mais l'installation et la gestion en sont plus simples et mieux intégrées dans cette nouvelle version.
Pour plus de détails sur ASM voir les documentations Oracle où on peut trouver beaucoup de choses.
Le système de base sera un système Linux Oracle (image disque copiée de l'image "de base" d'installation) cf article : "installation d'un linux Oracle".
La configuration disques prévue est la suivante :
- Disque système de 16Go
- Disque "DATA" de 10Go
- Disque "RECO" de 10Go
En effet Oracle propose de définir par défaut deux groupes de disques séparés :
- Un pour les données
- L'autre pour les éléments liés à la sécurité (double des "redo logs", fichiers "archivelog", sauvegardes de la base par RMAN.
Nous n'utiliserons pas, dans un premier temps, la possibilité offerte par ASM de gérer lui même la redondance des données, ce qui explique la présence de seulement deux disques de données. Dans une phase ultérieure on reconfigurera cette machine avec 4 disques de données pour pouvoir jouer avec la redondance et les "disk failure groups".
En ne mettant pas tous ses oeufs dans le même panier on garantit mieux la pérénité de sa base, par défaut un exemplaire du "controlfile" est créé dans chacun des groupes.
En regardant d'un peu plus près ASM donne à l'administrateur de la base de données (le "DBA") beaucoup plus de pouvoirs sur le fonctionnement gobal de la base de données en lui permettant de contrôler l'ensemble de la chaine de gestion depuis le stockage des données sur les disques jusqu'à leur délivrance aux utilisateurs.
Mais qui dit plus de pouvoirs dit aussi plus de responsabilité car il devra aussi assurer :
- La sécurité de ces données par divers moyens dont la redondance,
- La rapidité des traitements par le stripping des fichiers de données.
- La résistance aux pannes par une distribution réfléchie des disques sur les contrôleurs
- La "scalabilité" par les bases de données multi-instances (RAC chez Oracle)
- ...
Il va falloir que le DBA assimile de nouvelles techniques, de nouvelles contraintes pour garantir l'accès aux données.
Cette installation sera divisée en cinq parties :
- Mise en place des pré-requis.
- Mise e place de la partie ASM (partie de "grid").
- Chargement du logiciel base de données
- Création de la base de données.elle même
- Finalisation de l'installation
Oracle 11gR2 : création de la base de données
Oracle 11gR2 : création de la base de données jppPour créer la base de données l'utilisation de l'assistant "dbca" est conseillée.
La base n'étant pas encore créée le "ORACLE_HOME" n'existe pas encore il nous faut donc "forcer" l'utilisation du "bon" (/opt/oracle/product/11.2.0/dbhome_1) lors de l'appel à "oraenv" :
. oraenv ORACLE_SID = [oracle] ?
ORACLE_HOME = [/home/oracle] ? /opt/oracle/product/11.2.0/dbhome_1
The Oracle base for ORACLE_HOME=/opt/oracle/product/11.2.0/dbhome_1 is /opt/oracle
On vérifie par :
echo $PATH
/usr/kerberos/bin:/usr/local/bin:/bin:/usr/bin:/home/oracle/bin:/opt/oracle/product/11.2.0/dbhome_1/bin
C'est OK, on peut lancer la commande "dbca", l'écran initial de OUI est à passer pour arriver au premier écran de l'installation :
- Premier écran "Sélectionner le type d'opération", on coche évidemment "Créer une base de données".

- Deuxième écran on coche "Bd généraliste...".
- Troisième écran "Nom de la base de données", le "nom global" sera "orcl.toto.fr", le SID sera automatiquement mis à "orcl".
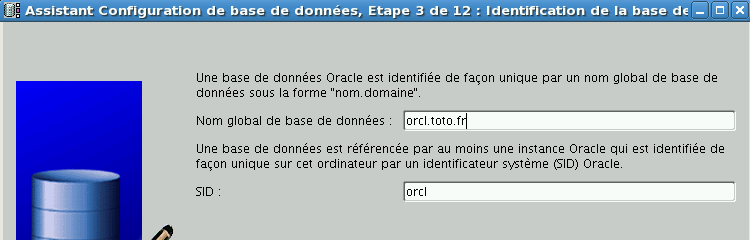
- Quatrième écran : "Options de gestion", on coche "Configurer Entreprise Manager", "Configurer Database Control pour la gestion locale". Sur l'onglet "Taches de maintenance automatique " bien cocher "Activer les tâches de maintenance automatiques".
- Cinquième écran "Information d'identification" pour simplifier utiliser le même mot de passe pour tous les comptes
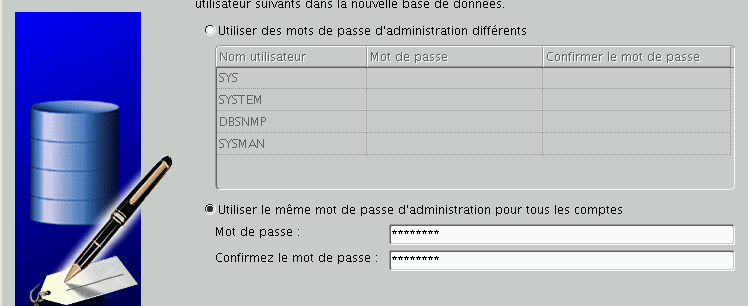
- Sixième écran "Emplacement des fichiers", c'est là qu'il faut sélectionner le choix "Automatic Storage Management" pour le type de stockage et cocher "utiliser Oracle Managed Files (OMF) ,

cliquer ensuite "Parcourir" pour sélectionner la "zone de base de données". Comme nous avons choisi "ASM" la boite de sélection des groupes de disques s'ouvre et nous sélectionnons notre groupe "DATA" 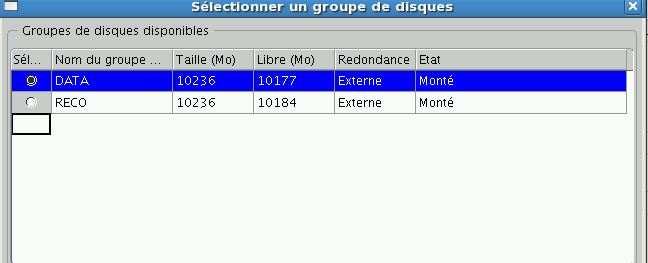
Nous pouvons ensuite passer à la suite.
- Septième écran : on nous demande le mot de passe de ASMSNMP (ne pas l'oublier !) qu'il faut fournir avant de continuer sur la "configuration de la récupération" (Flash-recovery ou Fast-recovery). Il faut cocher "Indiquer la zone de récupération rapide" et saisir "+RECO" pour le nom de la zone (ou cliquer "Parcourir" pour ré-ouvrir la boite de choix des groupes de disques) et laisser la taille proposée. Vous pouvez dès maintenant activer l'archivage (comme sur une "vraie" base).
- Huitième écran : cocher "exemples de schémas" pour bénéficier et SCOTT/TIGER et autres HR/HR, laisser tranquille l'onglet "Scrips personnalisés".
- Neuvième écran "Parametres d'initialisation", Onglet "Mémoire" :
mettre la Taille de la SGA vers 500 Mo,
cochez "Utilisez la gestion automatique de la mémoire".
Onglet "Dimensionnement" : la taille de bloc est figée à 8192 octest (conséquence de notre choix du modèle), réduire le nombre de processus à 100.
Onglet "Jeu de caractères" : c'est très important en production, ici on coche "Utiliser Unicode (AL32UTF8) et on laisse tel quel le "Jeu de caractère National", on positionne la langue par défaut à "Français" et le territoie par défaut à "France" (je suis un peu chauvin !).
Onglet "Mode de connection" : on coche mode serveur dédié car on ne compte pas avoir 3000 utilisateurs connectés. - Dixième écran : "Stockage de la base de données" : on vérifie que tout est OK sur nos disques ASM, en principe rien à toucher pour nos tests.
- Sur l'écran suivant (le dernier) on coche "Générer les scripts de création de la base de données" pour pouvoir s'instruire plus tard et on clique "Terminer".
Le récapitulatif de notre paramétrage s'affiche 
Il est de bon ton de le vérifier, et même de 'enregistrer au format HTML pour historique, avant de confirmer.
La création de la base démarre ensuite et est assez longue car il y a
- du boulot
- pas mal d'IO).
Selon l'heure un café ou une tisane peuvent être bienvenus.  Pour finir un petit "Recap" des actions s'affiche, il rappelle notament l'adresse et le port à utiliser pour l'accès à la console d'admin (en https maintenant).
Pour finir un petit "Recap" des actions s'affiche, il rappelle notament l'adresse et le port à utiliser pour l'accès à la console d'admin (en https maintenant). 
on peut depuis cet écran aller "activer" certains utilisateurs (SCOTT/TIGER par exemple en confirmant ce mot de passe qui ne répond pas aux normes !), mais on pourra le faire plus tard par l'intérmédiaire de la consle d'administration.
Remarques : - pour la gestion des autorisations il faudrait, sur une base réelle, être beaucoup plus "fins" et créer différents groupes au niveau du système afin de pouvoir déléguer un certain nombre de tâches "administratives" (stop/start des instances par exemple, à des personnes n'ayant pas à disposer d'autres droits d'administrateur.
Ceci est particulièrement vrai pour les privilèges "oper" destinés aux opérateurs qui doivent au moins pouvoir arrêter et démarrer la base.
. - La version 11gR2 intègre "Oracle restart" qui permet de démarrer et de stopper les éléments en respectant l'ordre des dépendances :
- Asm doit avoir un "listener" pour fonctionner,
- la base a besoin d'Asm pour démarrer ...
Oracle restart se commande en ligne de commande par "srvctrl (start|stop|status) (database|asm...) .....
Pour finir vérifions que tout est OK :
. oraenv
ORACLE_SID = [orcl] ? orcl
The Oracle base for ORACLE_HOME=/opt/oracle/product/11.2.0/dbhome_1 is /opt/oracle
et on lance le test final
sqlplus scott/tiger
SQL*Plus: Release 11.2.0.1.0 Production on Wed Feb 17 02:36:07 2010
Copyright (c) 1982, 2009, Oracle. All rights reserved.
Connecte a : Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production With the Partitioning, Automatic Storage Management, OLAP, Data Mining and Real Application Testing options
SQL> select table_name from user_tables;
TABLE_NAME ------------------------------
SALGRADE
BONUS
EMP
DEPT
SQL> exit
Deconnecte de Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production With the Partitioning, Automatic Storage Management, OLAP, Data Mining and Real Application Testing options
Tout baigne ... on va pouvoir lancer la console https:127.0.0.1:1158/em et après un "echec de la connexion sécurisée" et l'ajout d'une exception dans Firefox pour accepter le certificat voici la merveilleuse console d'administration : 
Xen : finalisation installation Oracle 11g
Xen : finalisation installation Oracle 11g jppPour finaliser l'installation de Oracle 11G il faut effectuer quelques ajustements :
- Modifier le fichier "/etc/oratab"
- Mettre en place les bonnes variables lors du login.
- Corriger deux scripts (dbstart et dbshut)
Le fichier /etc/oratab doit être légèrement modifié, il s'agit juste de déclarer notre base de données fonctionnelle en remplaçant un "N" par un "Y" :
# Multiple entries with the same $ORACLE_SID are not allowed.
#
#
ORA11G64:/home/oracle/app/oracle/product/11.2.0/dbhome_1:Y
Mettre en place les "bonnes" variables lors du login :
Pour réaliser cette opération nous allons créer un petit fichier "/etc/default/oracle" contenant les déclarations de variables, celui-ci pourra être déclenché lors du login des utilisateurs ayant besoin d'un accès à Oracle par un appel dans le fichier ".bashrc". Ce petit fichier contiendra pour nous :
ORACLE_BASE=/home/oracle/app/oracle
ORACLE_HOME=/home/oracle/app/oracle/product/11.2.0/dbhome_1
export ORACLE_BASE ORACLE_HOME
PATH=$PATH':'$ORACLE_HOME'/bin'
ORACLE_SID=ORA11G64
export ORACLE_SID
ORACLE_TERM=xterm
LD_LIBRARY_PATH=$ORACLE_HOME/lib':/lib:/usr/lib'
CLASSPATH=$ORACLE_HOME'/JRE:'$ORACLE_HOME'/jlib:'$ORACLE_HOME'/rdbms/jlib'
ORATAB=/etc/oratab
export ORACLE_TERM LD_LIBRARY_PATH ORATAB CLASSPATH
Le fichier ".bashrc" de "oracle" sera modifié comme suit :
# .bashrc
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
. /etc/default/oracle
# User specific aliases and functions
La ligne en rouge est à ajouter. Il faut ensuite se déconnecter, se reconnecter et vérifier que les variables "ORACLE_..." sont bien en place, ici :
env | grep ORACLE
ORACLE_SID=ORA11G64
ORACLE_BASE=/home/oracle/app/oracle
ORACLE_TERM=xterm
ORACLE_HOME=/home/oracle/app/oracle/product/11.2.0/dbhome_1
Aller modifier les scripts "dbshut" et "dbstart" situés dans $ORACLE_HOME/bin pour y ajouter une ligne qui permettra au "listener" de démarrer tranquillement sans besoin 'avoir recours à "lsnrctl start" systématiquement ou à " dbstart|dbshut $ORACLE_HOME ".
- dbstart.
79 # First argument is used to bring up Oracle Net Listener
80 ORACLE_HOME_LISTNER=$1
81 ORACLE_HOME_LISTNER=$ORACLE_HOME
Ajouter la ligne en rouge et supprimer la précédente si vous voulez ... - dbshut
49 # The this to bring down Oracle Net Listener
50 ORACLE_HOME_LISTNER=$1
51 ORACLE_HOME_LISTNER=$ORACLE_HOME
Ajouter la ligne en rouge et supprimer la précédente si vous voulez ...
Les numéros de lignes sont valables pour ma version seulement ....
On peut alors utiliser la commande qui lance la base de données :
dbstart
Processing Database instance "ORA11G64": log file /home/oracle/app/oracle/product/11.2.0/dbhome_1/startup.log
Et c'est parti, la base de données est activée, la preuve :
sqlplus system
SQL*Plus: Release 11.2.0.1.0 Production on Fri Feb 12 16:15:14 2010
Copyright (c) 1982, 2009, Oracle. All rights reserved.
Enter password:
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL>exit
Si vous voulez, en plus, l'accès par le web à la console Oracle il faudra lancer la commande :
emctl start dbconsole
Qui devrait vous renvoyer quelque chose comme :
Oracle Enterprise Manager 11g Database Control Release 11.2.0.1.0
Copyright (c) 1996, 2009 Oracle Corporation. All rights reserved.
https://k2000-ora64.jpp.fr:1158/em/console/aboutApplication
Starting Oracle Enterprise Manager 11g Database Control .......... started.
------------------------------------------------------------------
Logs are generated in directory /home/oracle/app/oracle/product/11.2.0/dbhome_1/k2000-ora64.jpp.fr_ORA11G64/sysman/log
Et vous permettre d'accéder au nirvana des DBA, grâce à un "https://serveur:1158/em" : 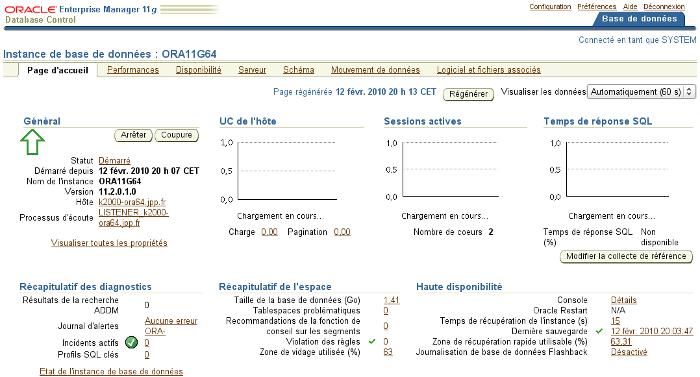
That's all folk.
ASM : plus loin vers RAC
ASM : plus loin vers RAC jppPour aller plus loin avec ASM la machine "simple" créée précédemment permet de se familiariser avec ASM mais ne permet pas d'essayer des choses que l'on pourrait faire avec une "grosse" machine, ni de tester les possibilités de RAC. Pour réaliser cet essai Xen va me permettre de simuler une machine d'enfer :
- 10 disques dont 9 de données
- 2 processeurs ( seulement sniff...)
- 3 Go de RAM ( seulement re sniff ...)
L'installation sera faite progressivement en partant des pré-requis, tout ceci sera simplifié par la ré-utilisation de l'image du Linux d'Oracle déjà utilisée. Le tout présenté en cinq phases :
- Mise en place des pré-requis
- Installation de ASM complet pour RAC
- Finalisation ASM + cluster
- Installation de la base de données
- Tests
Note : il existe des différences avec l'installation de ASM "simple", elle ne sont que faibles et dues à la gestion supplémentaire d'un "cluster".
Rappel : voir la doc Oracle ici et pour le détail des commandes de "asmcmd" allez voir là, ces docs sont, bien sûr, en anglais, la langue de ceux qui ignorent qu'il existe d'étranges individus dont la langue maternelle n'est pas l'anglais.
ORACLE pré-requis pour ASM
ORACLE pré-requis pour ASM jppL'installation de la machine Linux étant terminée (et une image sauvegardée) on va pouvoir s'attaquer au plus gros : l'installation de Oracle avec ASM.
Il y a d'abord un certain nombre de pré-requis pour que l'installation se passe sans anicroches (les pré-requis et l'image Linux de base ont été "pompés" d'un autre article !).
Rappel : ceci n'est pas une installation destinée à la production mais une installation de test dont la sécurité n'est pas assurée correctement !
Ajouter les lignes suivantes dans le fichier "/etc/sysctl.conf" :
------------------------------------------
# add for Oracle GRID
fs.file-max = 6815744
fs.aio-max-nr = 1048576
kernel.shmmni = 4096
kernel.shmall = 2097152
kernel.shmmax = 536870912
kernel.sem = 250 32000 100 128
net.ipv4.ip_local_port_range = 9000 65500
net.core.rmem_default = 262144
net.core.rmem_max = 4194304
net.core.wmem_default = 262144
net.core.wmem_max = 1048576
------------------------------------------
Ne pas oublier ensuite un "systcl -p" pour valider les modifiations.
A modifier le fichier "/etc/security/limit.conf" et y ajouter :
-----------------------------------------
# for oracle
@dba soft nproc 2047
@dba hard nproc 16384
@dba soft nofile 65536
@dba hard nofile 131072
-----------------------------------------
Nous sommes en test et nous n'allons pas séparer les privilèges entre "oracle" et "grid", nous installerons le tout par l'utilisateur "oracle" afin de simplifier l'installation.
Créer quelques groupes :
- dba ( réservé à l'utilisation)
- oinstall (réservé à l'installation, sera "owner" du logiciel).
Créer l'utilisateur "oracle" membre des groupes : "oracle" en groupe primaire + "oinstall" et "dba".
Mettre à jour la version Linux et initialiser "yum" :
cd /etc/yum.repo.d
wget http://public-yum.oracle.com/public-yum-el5.repo
Lancer l'éditeur sur le fichier repo et passer à "enabled = 1" les repositories à utiliser (el5_ga_bas, el5_u4-base)
Lancer un "yum repolist" qui déclenche le chargement des données de catalogue.
Vous pouvez ensuite utiliser les commandes "yum" pour installer les paquets manquants :
- libaio-devel
- sysstat
- unixODBC
- unixODBC-devel
Un grand coup de "yum install ...." et c'est torché (presque aussi bien que aptitude).
Installer les "bons" drivers pour ASMLIB, ceux ci dépendent du système, comme nous avons un Linux made by Oracle un petit coup de :
yum search asm
vous donnera la liste des candidats, ici je choisit (en fonction du noyau installé (uname -a)) :
oracleasm-support.x86_64 : The Oracle Automatic Storage Management support programs.
puis donc :
yum install oracleasm-2.6.18-164.el5.x86_64 oracleasm-support.x86_64
Comme il y a un driver au niveau du noyau un redémarrage est prudent pour véfifier.
Après un reboot il reste encore des "choses" à faire pour ne pas tomber en rade lors de l'installation.
Lancer la commande suivante pour vérifier l'espace partagé :
df -h /dev/shm/
Chez moi elle donne :
df -h /dev/shm/
Sys. de fich. Tail. Occ. Disp. %Occ. Monté sur
tmpfs 1,5G 0 1,5G 0% /dev/shm
Ce qui devrait nous permettre d'utiliser un "MEMORY_TARGET" <= 1,5Go
Beaucoup d'autres pré-requis sur l'espace nécessaire dans les différents filesystems, le swap, il faut aussi disposer d'un écran X de 1024x768 mini. Mais comme la partition unique destinée au système et au logiciel est dimensionnée généreusement cela ne devrait pas poser de problèmes. L'installation de Oracle Linux est normalement compatible si vous avez installé le système de développement car Oracle a besoin de compilateurs.
Mise en place des chemins "qui vont bien" et des variables d'environnement communes à toute l'installation. J'ai créé un répertoire ORACLE dans /etc/default pour contenir ces infos communes. Ce fichier est exécuté (. /etc/default/ORACLE ) dans le fichier profile des utilisateurs concernés.
- ORACLE_BASE pointe ici vers notre répertoire "/opt/oracle"
- export ORACLE_BASE
Le tout placé dans le fichier "/home/oracle/.bashrc".
Créer ensuite un fichier "99-oracle-rules" de règles dans "/etc/udev/rules.d" qui contiendra pour nous :
# Regles pour ASM
KERNEL=="hdb[1-9]", OWNER="oracle", GROUP="dba", MODE="0660"
KERNEL=="hdc[1-9]", OWNER="oracle", GROUP="dba", MODE="0660"
Nous allons ensuite affecter 2 "disques" à la machine virtuelle en /dev/hdb et /dev/hdc. Ici il s'agira de deux partitions LVM sur deux disques physiques différents pour avoir de meilleures performances. Ces "disques" seront créés avec chacun une seule partition.
Ces deux disques seront utilisés pour "imiter" une base de produtcion où, en dehors de toute option de performance, il ne faut pas oublier de séparer la base des fichiers permettant de la reconstituer (archives, double des "redologs", sauvegarde RMAN, zone de "flash-back"), ne serait-ce que pour assurer un minimum de sécurité :si on perd les données on aura les sauvegardes (RMAN), le double des redologs et la zone Flash.
Ceci réalisé il sera possible de passer à l'opération suivante : Installation des éléments du "grid" où se trouve ASM et préparation des zones ASM destinées à recevoir notre BDD.
ASM RAC : installation ASM et cluster
ASM RAC : installation ASM et cluster jppComme d'habitude se rendre dans le répertoire où le logiciel a été décompressé, ici sur un montage Samba et lancer la commande "./runInstaller.sh" qui démarre l'installeur "OUI". Après quelques contrôles et un certain temps la fenêtre de "OUI" s'ouvre.
Ouvrir un terminal "root" en ssh sur la machine, cela va servir !
Ecran 1 "Option d'installation", cocher "Installer ... pour un cluster, comme cela on pourra plus tard tenter le RAC puisque un "cluster" d'une seule machine ne mérite guère son nom !
Ecran 2 "Type d'installation", cocher "Installation Standard"
Ecran 3 : "Configuration du cluster", garder les noms proposés (toute la partie réseau a été préparée pour cela). 
a) Il faut identifier les interfaces réseau, "eth0" en "public" et "eth1" en "privé". 
b) paramétrer la connexion ssh en la configurant puis en testant 
Ecran 4 : "Emplacement d'installation", Il faut (terminal "root" que vous avez déjà ouvert) créer le répertoire "11.2.0" dans /opt et faire un "chown oracle:dba 11.2.0", le rouge de la zone disparait alors par miracle.
Il faut sélectionner "Automatic Storage Management" pour le "type de stockage...". Il faut aussi donner le mot de passe de "SYSASM" (c'est "dieu le père", l'équivalent du user "SYS" pour la base de données), ne pas perdre ce mot de passe ! Je sélectionne "dba" pour le groupe "OSASM". 
Mon mot de passe n'entre pas dans les règles il me faut donc confirmer, on voit d'ailleurs la zone en jaune sur l'écran.
Ecran 5 : "Groupes de disque ASM", on ne crée ici que le groupe initial, on l'appelera "DATA" pour rester dans le standard. Cocher la redondance "externe" car un seul disque est réservé (je m'en fous c'est un RAID0 !à. Après avoir "modifié l chemin de repérage" 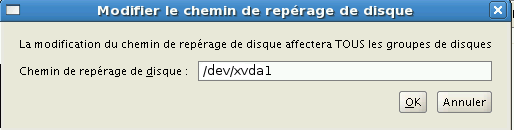
on voit apparaître notre premier disque, rappelez vous celui réservé sur /dev/hdb1 en dehors de notre future "batterie" de disques. On sélectionne le disque "candidat". 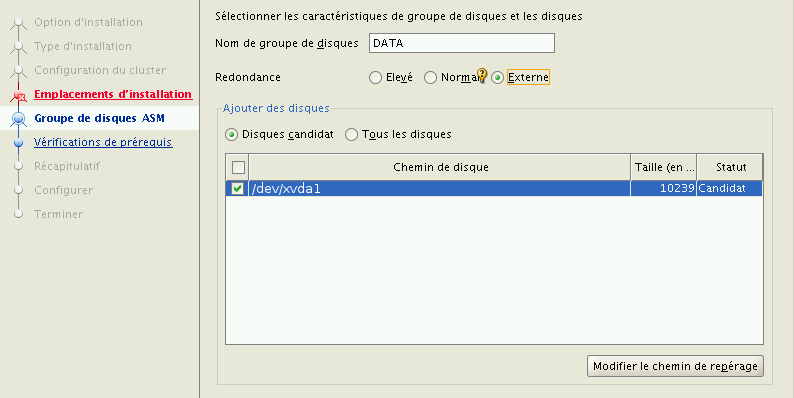
Ecran 6 : "Créer un inventaire", créer (terminal "root") le répertoire "/opt/oraInventory" et executer "chown oracle:dba oraInventory" et faire immédiatement "Suivant".
Ecran 7 : "Vérification des pré-requis", si rien ne cloche il ne devrait pas y avoir de problèmes et l'écran "Récapitulatif" s'affiche : 
Et on clique "Fin" pour que cette N...! de machine se mette sérieusement à bosser et que je puisse aller déguster mon café : 
Enfin arrive le moment des scripts "root" (dans le beau terminal que vous avez ouvert) :
- /opt/oraInventory/orainstRoot.sh
- /opt/11.2.0/grid/root.sh
Le premier est une simple formalité, le deuxième est beaucoup plus importat (et long) car il configure réellement le "cluster".
./orainstRoot.sh
Modification des droits d'accès de /opt/oraInventory.
Ajout de droits d'accès en lecture/écriture pour le groupe.
Suppression des droits d'accès en lecture/écriture/exécution pour le monde.
Modification du nom de groupe de /opt/oraInventory en oracle.
L'exécution du script est terminée. Pas bavard et court ! Il n'en pas de même pour le suivant :
/root.sh 2>&1 | tee ROOT.LOG
Running Oracle 11g root.sh script...
The following environment variables are set as:
ORACLE_OWNER= oracle
ORACLE_HOME= /opt/11.2.0/grid
Enter the full pathname of the local bin directory: [/usr/local/bin]:
Après l'appui sur "Entrée" il se passe des choses (prévoir un deuxième café ou une petite promenade) ... la suite du listing en fichier attaché pour information.
Après appui sur OK c'est reparti : 
pour le final (une minute!).Et c'est l'instant tant attendu : 
Après fermeture de la session X "oracle" il y a 41 processes qui tournent sous le user "oracle" !
L'étape suivante est : une bonne sauvegarde avant d'aller plus loin suivi d'un redémarrage pour vérifier que tout est toujours en place.
Au redémarrage, les disques sont toujjours là (et attribués à "oracle"), et nous pouvons remarquer que la machine est dotée de deux pseudo interfaces réseau supplémentaires et qu'elle répond bien aux noms supplémentaires préparés :
- k2000-ora65-vip
ping -c1 k2000-ora65-vip
PING k2000-ora65-vip.jpp.fr (192.168.1.150) 56(84) bytes of data.
64 bytes from k2000-ora65-vip.jpp.fr (192.168.1.150): icmp_seq=1 ttl=64 time=0.038 ms
--- k2000-ora65-vip.jpp.fr ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.038/0.038/0.038/0.000 ms - k2000-o-cluster
ping -c1 k2000-o-cluster
PING k2000-o-cluster.jpp.fr (192.168.1.151) 56(84) bytes of data.
64 bytes from k2000-o-cluster.jpp.fr (192.168.1.151): icmp_seq=1 ttl=64 time=0.041 ms
--- k2000-o-cluster.jpp.fr ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.041/0.041/0.041/0.000 ms
Si l'on regarde les interfaces deux pseudo interfaces ont ét créés :
# ifconfig eth0:1
eth0:1 Link encap:Ethernet HWaddr 00:16:3E:30:07:01
inet adr:192.168.1.151 Bcast:192.168.1.255 Masque:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interruption:177 Adresse de base:0x2000
# ifconfig eth0:2
eth0:2 Link encap:Ethernet HWaddr 00:16:3E:30:07:01
inet adr:192.168.1.150 Bcast:192.168.1.255 Masque:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interruption:177 Adresse de base:0x2000
..
Tout semble OK pour passer à l'étape suivante : configurer notre jeu de disques ASM pour accueillir en toute sécurité nos bases de données.
ASM RAC : Installation logiciel base de données
ASM RAC : Installation logiciel base de données jppAprès quelques vacances il va enfin être possible de se lancer dans l'installation de la base de données sur notre machine. Toutefois un incident de dernière minute (crash disque) retarde un peu la publication de cette partie.
Bonne nouvelle (29/03/2010) le disque est changé, un système "propre" réinstallé. Il me reste juste à compiler et installer la dernière version (3.4.3-rc...) de XEN.
Mais il me faut restaurer la machine virtuelle "RAC" car elle avait souffert lors du crash du serveur (elle était en pleine installation) et il me faut ré-installer la partie grid (excellent test du petit tutorial précédent) avant de pouvoir installer le logiciel et la base de données.Quelques soucis dans la nouvelle installation avec le SSD (il faut le "trimmer" pour améliorer les performances, et ce n'est pas évident, probablement un sujet à traiter), décidemment celà n'avance pas !
Le nouveau noyau linux/xen que je teste ne supporte que très mal Xwindows, il me faut donc me résoudre à installer "libvirt" et "virt-manager" sur une autre machine, à configurer le tout pour pouvoir me passer de X sur le serveur principal. Enfin, tout est prêt, la partie "grid" s'est installée sans problèmes (je pourrais maintenant l'installer quasiment les yeux fermés !), après une petite sauvegarde l'installation de la partie Base de Données peut commencer.
En ce qui concerne l'installation du logiciel et de la base de données il vaut mieux séparer les deux opérations car il me semble que l'assistant de création de base (dbca) ne présente pas toutes les options lorsqu'il est lancé depuis l'installeur.
Cette partie est assez simple, l'article sera court et avec peu de copies d'écran.
Lancer l'installeur dans le répertoire d'installation : ./runInstaller.sh
- Premier écran "Configurer les mises à jour" :
Tout décocher (il faudra confirmer après le clic sur suivant).
- Deuxième écran "Options d'installation" : 
Cocher "Installer le logiciel de base de données uniquement". Copie écran avec la petite boîte explicative pour exemple.
- Troisième écran "Options de grille" : 
Vérifier la connexion SSH.
- Quatrième écran "Langues du produit" : ajouter les langues désirées, pour moi anglais + français cela me suffit !
- Cinquième écran "Edition de base de données" :
Cocher "Entreprise Edition", on est là pour tout voir !
Le bouton "Sélectionner des options" peut permettre d'installer ou non certaines options, on n'y touche pas par principe.
- Sixième écran "Emplacement d'installation" :
Laisser les valeurs présentes ... pas de surprises, sauf un "dbhome_2" pour moi car j'ai du annuler (en cours) une installation précédente, et je n'ai pas détruit ce répertoire résiduel.
- Septième écran "Groupes de système d'exploitation" : et hop "dba" pour tout le monde. L'enchainement sur la vérification ne devrait pas nous poser de problèmes ... et c'est bien le cas. 
Il est bon de passer tout cela en revue avant de cliquer "Fin".
Et c'est parti ... 
le voyant du disque (physique) clignote frénétiquement pendant la copie des fichiers. Ce n'est pas super rapide et en plus le répertoire d'installation est sur un partage Samba.
Le link des fichiers binaires est nettement plus rapide et arrive enfin le moment de passer le script "root.sh", je ne résiste pas à la prise d'une petite image ! 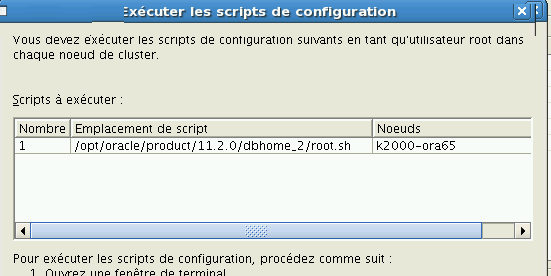
./root.sh
Running Oracle 11g root.sh script...
The following environment variables are set as:
ORACLE_OWNER= oracle
ORACLE_HOME= /opt/oracle/product/11.2.0/dbhome_2
Enter the full pathname of the local bin directory: [/usr/local/bin]:
The file "dbhome" already exists in /usr/local/bin. Overwrite it? (y/n)
[n]: n
The file "oraenv" already exists in /usr/local/bin. Overwrite it? (y/n)
[n]: n
The file "coraenv" already exists in /usr/local/bin. Overwrite it? (y/n)
[n]: n
Entries will be added to the /etc/oratab file as needed by
Database Configuration Assistant when a database is created
Finished running generic part of root.sh script.
Now product-specific root actions will be performed.
Finished product-specific root actions.
Ensuite après le "OK" final un magnifique écran nous indiquant que l'installation a réussi, on n'en doutais pas !
Oracle 11g R2 : installation "grid"
Oracle 11g R2 : installation "grid" jppUne fois la machine démarrée créer les partitions sur les disques "hdb" et "hdc" avec fdisk, une partiton par disque. Ne pas monter les nouvelles partitions et lancer la commande "partprobe" pour valider ces nouvelles partitions auprès du noyau :
partprobe /dev/hdb
partprobe /dev/hdc
Un reboot peut permettre de s'assurer que les disques sont bien "chownés" par le système au démarrage :
ls -al /dev/hdb*
brw-r----- 1 root disk 3, 64 fév 21 2010 /dev/hdb
brw-rw---- 1 oracle dba 3, 65 fév 21 14:01 /dev/hdb1
Les partitions seront alors reconnues par le kernel. On peut ensuite quitter le user "root" et lancer l'interface graphique et se connecter avec le user "oracle".
Vérifier que le répertoire d'installation (pour nous "/opt/oracle" est bien pointé par la variable "ORACLE_BASE" et que le répertoire est bien "chowné" "dba".
Dans le répertoire d'installation, oui, celui où l'archive "zip"' a été décompressée, on trouve un sous-répertoire "grid" qui contient l'habituel "runInstaller.sh" qui permet le lancement de l'installer ("OUI" de son petit nom).
drwxr-xr-x 9 1000 root 0 aoû 16 2009 doc
drwxr-xr-x 4 1000 root 0 aoû 15 2009 install
drwxrwxr-x 2 1000 root 0 aoû 15 2009 response
drwxrwxr-x 2 1000 root 0 aoû 15 2009 rpm
-rwxrwxr-x 1 1000 root 3795 jan 8 01:03 runcluvfy.sh
-rwxr-xr-x 1 1000 root 3227 jan 8 01:03 runInstaller
drwxrwxr-x 2 1000 root 0 aoû 15 2009 sshsetup
drwxr-xr-x 14 1000 root 0 aoû 15 2009 stage
-rw-r--r-- 1 1000 root 4228 jan 8 01:04 welcome.html
Un "./runInstaller.sh" lance le tout et on se retrouve après quelques vérifications devant l'écran : 
Premier écran "Option d'installation" : On remarque sur cet écran (partie gauche) une échelle de suivi des différentes phases. Ici on choisira une installation pour un "...serveur autonome". Pas de RAC pour cette fois.
Deuxième écran : "Langues du produit" : ajouter la ou les langues désirées.
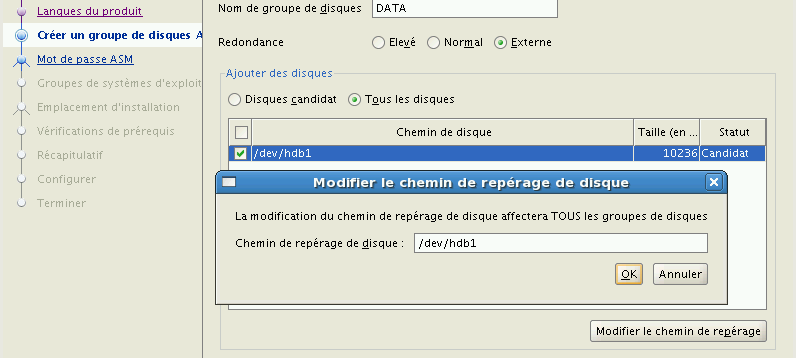
Troisième écran "Créer un groupe de disques", on ne créera ici qu'un groupe de disque sur les deux que nous avons définis. Nous ne sommes pas en production et je n'ai pas "plein" de disques. Je fais le chois de redondance externe pour le groupe par défaut "DATA" dans lequel nous allons intégrer notre partition "hdb1". Le disque n'étant pas reconnu par défaut par ASM il nous faut lui "forcer" un peu la main en passant par l'option "Modifier le chemin de repérage" où nous indiquerons "/dev/hdb1". Cocher ensuite ce disque "candidat".
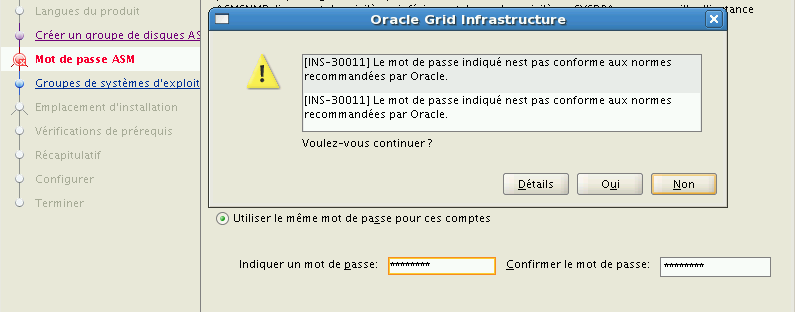
Quatrième écran "Mot de passe ASM", je sélectionne un seul mot de passe pour les deux users "ASM" : SYS et ASMSNMP (ne pas confondre avec le user SYS de la base de données !). Si le mot de passe est "trop simple", il faudra confirmer notre "volonté" d'utiliser un mot de passe si simple !
Cinquième écran "Groupes de système d'exploitation" : on choisit "dba" pour les trois groupes. Encore une fois, en production il serait "sage" d'utiliser un groupe par catégorie d'activité. C'est déconseillé par Oracle --> il faut confirmer cette volonté délibéreé de faire simple (et pas très sécurisé).
Sixième écran "Emplacement d'installation" : je laisse les emplacements par défaut dérivés de "ORACLE_BASE".
Septième écran " : corriger l'emplacement de l'inventaire par défaut en "/home/oracle/oraInventory".
Huitième écran "Vérification de prérequis" : normalement pas de problème ici l'installer passe ensuite à l'écran suivant.
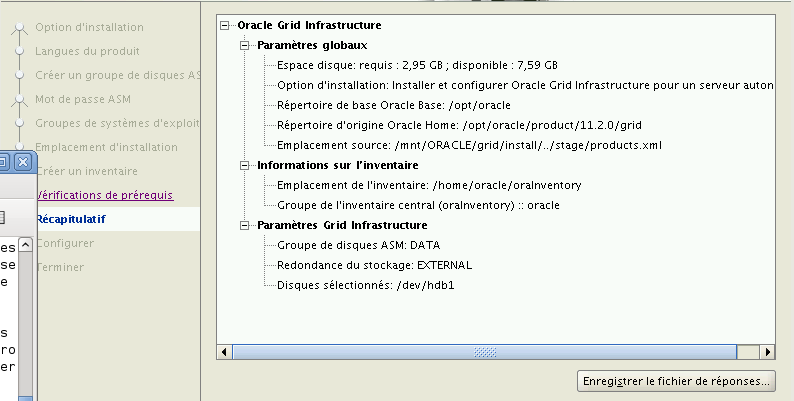
Neuvième écran "Récapitulatif" (ORAGRI_004.png) on peut ici enregistrer les réponses pour les "rejouer" plus tard sur un autre serveur.
L'installation est ensuite lancée ...
Et le miracle s'accomplit ... 
C'est bon, on ferme avec soulagement.
Pour le deuxième groupe de disques on commence par vérifier que nos disques seront bien accessibles par :
ls -al /dev/hdc1
brw-rw---- 1 oracle dba 22, 1 fév 16 03:12 /dev/hdc1
C'est OK, on commute dans le "bon" environnement par :
. oraenv
ORACLE_SID = [oracle] ?+ASM
The Oracle base for ORACLE_HOME=/opt/oracle/product/11.2.0/grid is /opt/oracle
Suivi de (pour montrer le travail de "oraenv" :
echo $PATH
/usr/kerberos/bin:/usr/local/bin:/bin:/usr/bin:/home/oracle/bin:/opt/oracle/product/11.2.0/grid/bin
Suivi de la commande :
asmca
Qui lance l'écran principal de l'assistant asm 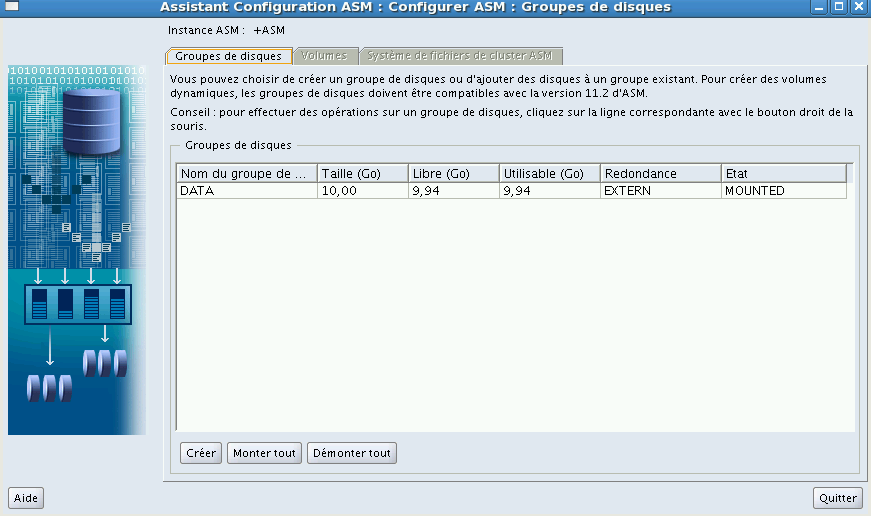
On va ensuite créer notre deuxième groupe de disques par le bouton intelligement appelé "Créer" 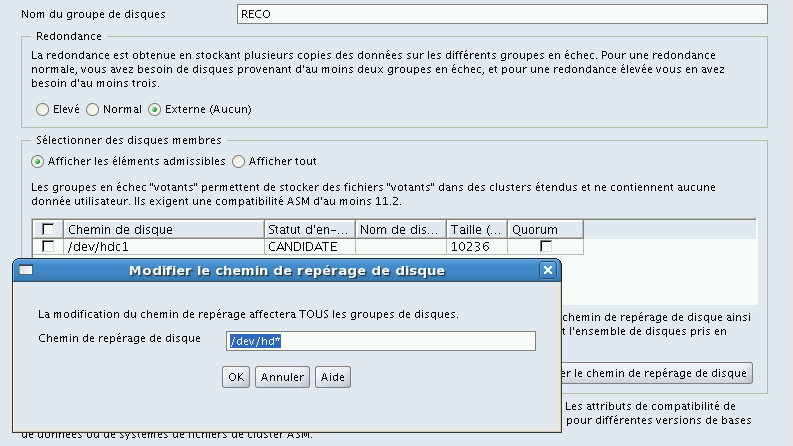
on modifie le chemin de repérage en "/dev/hd*" et on coche notre disque "/dev/hdc1" et on clique "OK". Le groupe de disque "RECO" est alors créé 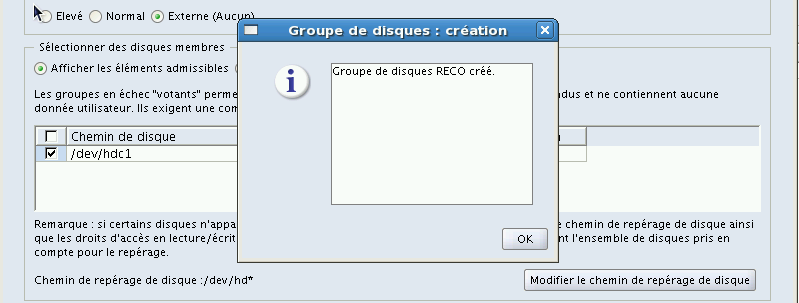 .
.
Ne croyant que ce que je vois je tente le reboot. Après le reboot, voyons si notre "disque" ASM est bien là en utilisant un autre type de commande (asmcmd fait partie du paquet, c'est une sorte de shell permettant d'explorer les disques ASM) :
. oraenv
ORACLE_SID = [oracle] ? +ASM
...
asmcmd
ASMCMD> ls -al
State Type Rebal Name
MOUNTED EXTERN N DATA/
MOUNTED EXTERN N RECO/
ASMCMD> exit
Nos deux disques sont bien là ... tout à l'air OK on va pouvoir prendre une image de notre machine et lancer l'opération suivante.
ASM RAC : première base de données
ASM RAC : première base de données jppDans ce chapitre nous allons créer notre première base de données grâce à l'assistant de création de bases de données, j'ai nommé "dbca". Plus besoin de recourir aux CD d'installation, tout fonctionne maintenant "en local", nous avons pris notre indépendance.
Le but de cet article est de présenter l'installation d'une base de données à la fois performante et sécurisée.
L'installation sera faite sur deux groupes de disques, un pour les données, un pour la zone de sécurité (Fast Recovery Area). Cette zone de sécurité doit permettre de redémarrer une base saine même en cas de perte (ou de corruption) des disques principaux.
Un petit schéma valant mieux qu'un long discours ... 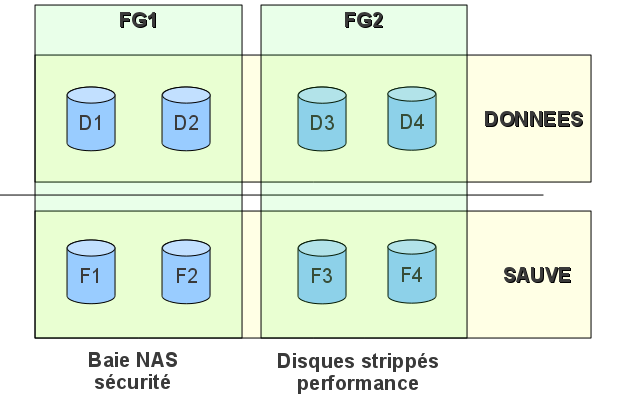
Cette configuration ne se prête pas au "vrai" RAC car les disques internes ne seront pas partageables entre deux instances. On verra cela un peu plus tard.
Après cette petite mise en bouche connectons nous un terminal sous X et dans le bon environnement :
. oraenv
ORACLE_SID = [oracle] ?
ORACLE_HOME = [/home/oracle] ? /opt/oracle/product/11.2.0/dbhome_2
The Oracle base for ORACLE_HOME=/opt/oracle/product/11.2.0/dbhome_2 is /opt/oracle
Lançons l'assistant de création "dbca" qui nous accueille après avoir murement réfléchi i
"Etape 0 ?" : Premier écran "Bienvenue" 
Cocher "Base de données RAC".
- "Etape 1" : cocher "Créer une base de données".
- "Etape 2" : cocher "BD généraliste... Sur cet écran on peut déjà avoir un avant-goût de ce que sera notre base ("Afficher les détails"), au détail près de ASM qui n'est pas pris en compte dans le modèle.
- "Etape 3" : je coche "Configuration gérée par un administrateur",
je coche "Configuration gérée par un administrateur".
je choisis le nom "rac001"
Un seul cluster étant présent pas d'angoisse de choix.
"Etape 4 " :
Premier onglet : 
- Cocher "Configurer Entreprise Manager"
- Cocher "Configurer Database control", "Activer les notifications d'alerte"
- Fournir l'adresse d'un serveur mail valide (c'est vérifié !) et une adresse non moins valide.
- Cocher "Activer la sauvegarde....", on pourra la gérer "à la main ensuite"
Donner le user et le password d'un utilisateur autorisé à effectuer les sauvegardes. Pour nous un utilisateur avec les droits "dba".
Deuxième onglet : vérifier que les "taches de maintenance automatique" sont bien cochées.
"Etape 5" : par simplification je coche "Utiliser le même mot de passe pour tous les comptes" et donne un mot de passe (trop simple qu'il faudra confirmer par la suite).
"Etape 6" : 
. Pour "Type de stockage" choisir ASM
. cocher "Utiliser OMF"
. "Zone base de données", choisir "DONNEES" qui affichera +DONNEES dans la boite.
Cliquer "Multplexer les fichiers ..." : 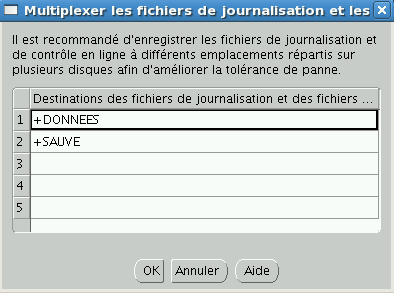
Indiquer ici le groupe principal +DONNEES et le groupe de sécurité +SAUVE
Rappel le "+" pour ASM correspond au "/" pour un filesystem Unix.
Inutile de cliquer "Variables d'emplacement de fichier" :
Lors du clic sur "Suivant" une boite demandant le mot de passe ASM s'ouvre.
"Etape 7" :
Ici les choses importantes, on sépare les données de sécurité des données de la base, il faut donc cocher "Indiquer la zone de récupération rapide" et la faire pointer sur "+SAUVE", augmentons un peu la taille à 5120M. Cette zone est fonction de la taille de la base hébergée. Au passage quelqu'un aurait-il une base de 4 à 6 G à prêter ? ...
Cocher "Activer l'archivage", c'est indispensable (et je ne parle même pas d'une base de production OLTP).
Inutile de cliquer "Variables d'emplacement de fichier".
"Etape 8" :
. Premier onglet, je coche "Exemples de schémas" car je suis un addict de scott/tiger et du schéma HR.
. Deuxième onglet, je n'ai pas de scrpts personnalisés.
Etape 9 :
. Premier onglet "Mémoire" : 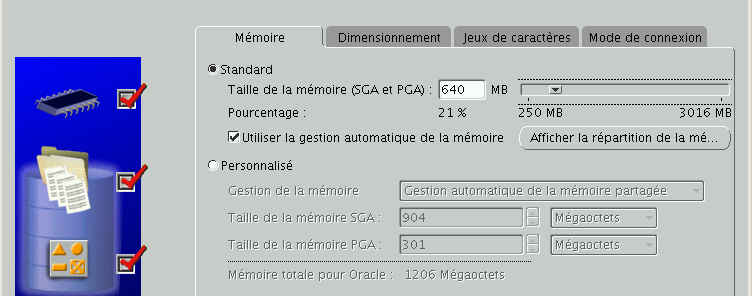
pour des tests je limite la taille mémoire à 640M et je coche "Utiliser gestion auto"
Deuxième onglet "Dimensionnement" : la taille de bocs n'est pas modifiable ... et 150 processus est un bon chiffre ... on ne touche rien.
Troisième onglet "Jeu de caractères" : 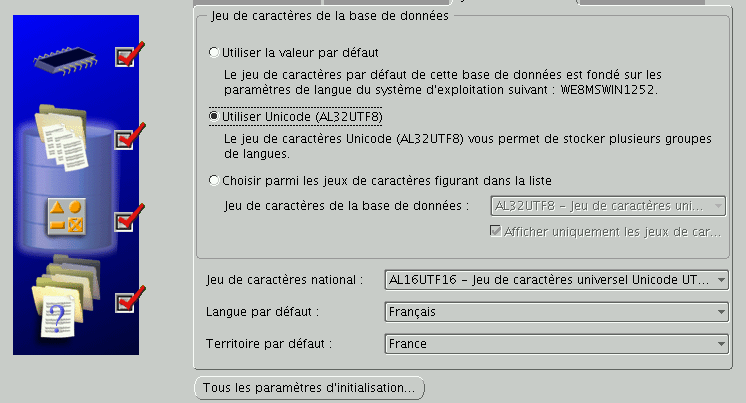
Je sélectionne "Utiliser Unicode" et laisse les autres valeurs par défaut.
. Quatrième onglet : je coche "Mode serveur dédié"
Je ne touche pas à "Tous les paramètres d'initialisation", mais je vais y jeter un oeil.
"Etape 10 " :
On peut ici vérifier (et éventuellement modifier les éléments de stockage).
"Etape 11" : cocher "Créer une base de données" et "Générer les scripts", stocker les scripts où vous voulez !
Et on arrive au moment fatidique de cliquer sur le bouton "Terminer" ce qu'il est fortement conseillé de faire.
Un écran récapitulatif s'affiche et permet de vérifier toute la configuration qui peut même être enregistrée en fichier HTML pour historique.
On clique "OK" et c'est parti .... d'abord la création du script ... "OK" ... 
et je n'ai pas besoin cette fois de cliquer "Arrêter".
Le voyant disques clignote frénétiquememt .. tout semble se dérouler correctement, largement le temps de prendre un café.
Enfin la base est créée ... 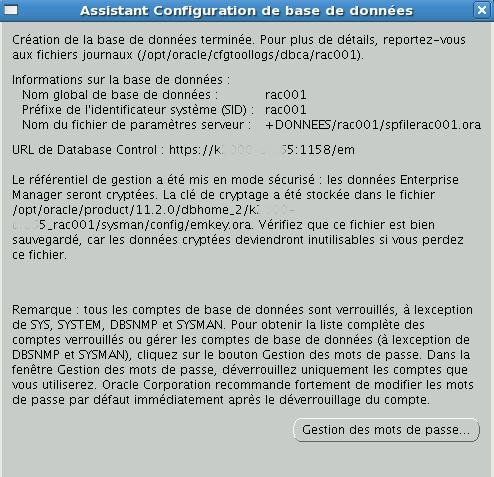
je ne touche pas à la gestion des mots de passe ... et clique sur "Quitter".
Le fichier "/etc/oratab" comporte bien une nouvelle ligne "rac001......" et un "ps -ef | grep rac001" montre une belle liste de process.
Une connexion https montre (après avoir accepté le certificat SSL) une belle image : 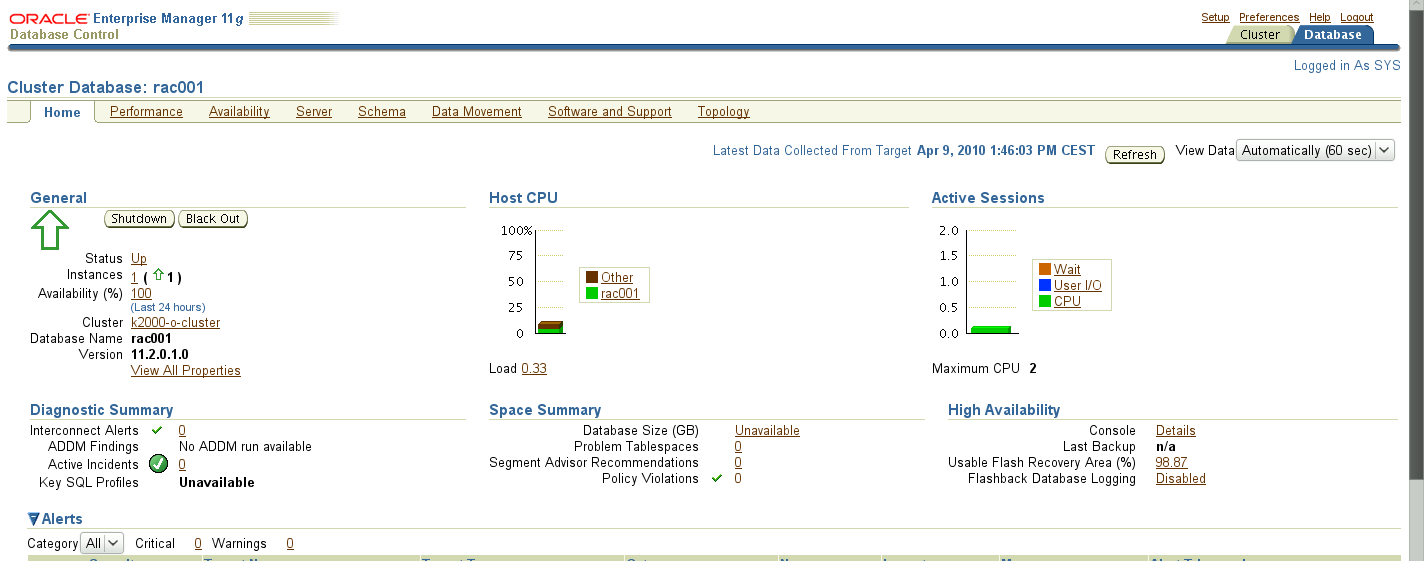
Enfin on va pouvoir s'amuser ... mais auparavant il nous faudra initialiser quelques variables permettant de discuter avec cette instance (rac0011) de la base de données (rac001).
ASM RAC : finalisation
ASM RAC : finalisation jppComme indiqué en fin du chapitre précédent il reste un certain nombre de manipulations à effectuer avant de pouvoir accéder "normalement" à la base. En effet ce n'est pas une base "normale" mais l'instance numéro un d'une base RAC.
Pour simplifier les choses j'ai préparé un script ( à lancer en début de connexion par ". mon_script" ) :
# My Oracle Settings
export ORACLE_SID=rac001
export ORAENV_ASK=NO
. oraenv
export TMP=/tmp
export TMPDIR=$TMP
export ORACLE_HOSTNAME=k2000-ora65
export ORACLE_UNQNAME=rac001
export ORACLE_BASE=/opt/oracle
export ORACLE_HOME=$ORACLE_BASE/product/11.2.0/dbhome_2
export ORACLE_TERM=xterm
export PATH=/usr/sbin:$PATH
# export PATH=$ORACLE_HOME/bin:$PATH
export LD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib:/usr/lib
export CLASSPATH=$ORACLE_HOME/JRE:$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib
ORAENV_ASK=''
Une fois le script de lancement exécuté notre environnement est "propre" et nous pouvons utiliser les commandes classiques.
D'abord démarrer l'instance :
srvctl start instance -d rac001 -i rac0011
on peut ensuite se connecter avec sqlplus :
sqlplus sys@rac001 as sysdba
SQL*Plus: Release 11.2.0.1.0 Production on Sat Apr 10 11:23:14 2010
Copyright (c) 1982, 2009, Oracle. All rights reserved.
Enter password:
Connecte a :
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production
With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP,
Data Mining and Real Application Testing options
SQL>
Et c'est parti ... tout est OK.
Toutes ces opérations sont faites "en manuel" il faudra automatiser tout cela dès que possible.
Premier essai : connectons nous avec sqlplus et créons un premier tablespace :
CREATE TABLESPACE "TEST_SPACE" DATAFILE
SIZE 512M
AUTOEXTEND ON NEXT 32M MAXSIZE 1024M;
Avec "OMF" et "ASM" pas la peine de nommer le datafile, le pied pour les paresseux.
Ensuite n'oubliez pas de lancer la console Web par :
emctl start dbconsole
Après un temps certain vous pourrez découvrir (en https maintenant) la console Web qui n'a pas fini de vous occuper car on peut tout faire depuis cet outil :
- Gérer la base de données :
- instance par instance (database instance)
- globalement (cluster database)
- Gérer le "cluster"
- Gérer ASM, pour y aller passer par l'onglet "cluster" (en haut à droite) puis dans le nouvel écran l'onglet "target" qui donne accès à une liste des objets gérables, y compris notre console ASM.
- Gérer les listener
Il y a beaucoup à découvrir, y compris du coté des backups ou RMAN est particulièrement bien "empaqueté" et si facilement utilisable : backups compressés, backups incrémentaux, backups "online" ...
Allez aussi voir du coté des "advisors" en passant pas "Advisor central" (lien disponible entre autres endroits en bas à droite de la page "Home").
La surveillance des performances n'est pas en reste et permet de surveiller la performance :
- au niveau du cluster
- au niveau d'une instance
- au niveau de ASM.
En bref cette console est un monde à part entière a découvrir et offre réellement un très grand nombre de possibilités.
Si vous cherchez les fichiers de trace (donr le célèbre alert...log) rendez vous dans :
$ORACLE_BASE/diag
où une arborescence fournie vous attends, allez voir dans "rdbms/nom_base/nom_instance" pour voir.
Oracle 23 c
Oracle 23 c jppChapitres en cours de réalisation et un peu retardés par des congés et 'autres réalisations ...
J'ai décidé de tester l'installation de Oracle 23c (édition développeur), cette installation sera faite dans une machine virtuelle (KVM) Oracle Linux 8.8 définie comme suit :
Processeurs : 4 VCPU
RAM : 12 Go
Disques
Système : 32Go
DATA : 128Go
INDEX : 128Go
Ceci afin de pouvoir effectuer des tests "avec du volume".
Les disques DATA et INDEX sont des partitions LVM sur des SSD, le disque système est sur un HD classique.
1) Installation système Oracle Linux 8.8.
2) Installation Oracle 23c.
3) Paramétrage minimum.
4) Quelques tests.
L'installation de Oracle Linux 8.8 se passe sans inconvénients majeurs, ci dessous quelques captures d'écrans.
Mais il reste encore des choses à faire ...
Pour commencer l'installation ... en cliquant sur "Commencer l'installation" et après quelques minutes ...
La suite "à venir" après quelque congé ...
Ca y est je suis revenu de loooongs congés et je vais me remettre aux tests de cette version.
Oracle Linux 8.8
Oracle Linux 8.8 jppLe nouveau système se lance bien, on a le choix entre deux versions de kernel 5.15 et 4.18, je laisse démarrer sur le 5.15 par défaut et comme j'ai choisi un mode "graphique" une session X s'ouvre.
Après avoir indiqué user/mot de passe il faut terminer le configuration de l'utilisateur courant et accepter ou refuser quelques "contraintes" telles que la géolocalisation et la transmission de données de fonctionnement (rapports de plantage).
L'aspect visuel est "classique" et tout fonctionne normalement.
Il faut maintenant monter et formater les deux disques (Data et Index) prévus pour cette machine. Pour ce faire une connection en "root" sera utilisée.
Sur les deux disques (125 GO chacun) j'implante sur chacun des deux disques (vdb et vdc) :
- Une table de partitions GPT
- Une partition unique de 125Go
Les deux partitions sont formatées en xfs :
mkfs -t xfs /dev/vdb1
meta-data=/dev/vdb1 isize=512 agcount=4, agsize=8191935 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1 bigtime=0 inobtcount=0
data = bsize=4096 blocks=32767739, imaxpct=25
= sunit=0 swidth=0 blks
naming = version 2 bsize=4096 ascii-ci=0, ftype=1
log = internal log bsize=4096 blocks=25600, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime = none extsz=4096 blocks=0, rtextents=0
Discarding blocks...Done.
Et "baptise" mes deux nouveaux FS : DATA et INDEX.
Il faut pour cela utiliser la commande "xfs_admin" avec les "bonnes" options, ici :
xfs_admin -L DATA /dev/vdb1
writing all SBs
new label = "DATA"
xfs_admin -L INDEX /dev/vdc1
writing all SBs
new label = "INDEX"
On teste que le montage de nos disques est OK :
mount LABEL=DATA /u/DATA
mount LABEL=INDEX /u/INDEX
Vérification :
df /u/*
Sys. de fichiers blocs de 1K Utilisé Disponible Uti% Monté sur
/dev/vdb1 130968556 946168 130022388 1% /u/DATA
/dev/vdc1 130968556 946168 130022388 1% /u/INDEX
Le montage est OK, on va pouvoir mettre à jour /etc/fstab pour le montage automatique de ces deux File Systems avec utilisation du "nom" des disques.
Avec la syntaxe "xfs" il suffit d'ajouter en fin du fichier fstab :
LABEL=DATA /u/DATA xfs nodiratime,relatime 1 2
#
LABEL=INDEX /u/INDEX xfs nodiratime,relatime 1 2
Au reboot tout se passe bien et mes deux partitions DATA et INDEX sont bien présentes.
J'installe immédiatement mon éditeur indispensable et préféré :
dnf install vim-X11.x86_64
Maintenant que le "support" est OK, on va pouvoir passer à la suite, installer Oracle 23c.
Note :
Deux Kernels sont proposée : 5.15 et 4.18, pas encore de 6.0, mais le 5.15 devrait nous suffire.
Installer Oracle23
Installer Oracle23 jppAprès le redémarrage de la machine on a accès au "login", ici en mode graphique car j'aime bien utiliser Gvim pour la maintenance des fichiers de paramétrage.
Tout a l'air OK on peut lancer les opérations d'installation :
1) Télécharger les deux RPM d'installation dans un répertoire tranquille :
- pre-install
wget https://yum.oracle.com/repo/OracleLinux/OL8/developer/x86_64/getPackage/oracle-database-preinstall-23c-1.0-0.5.el8.x86_64.rpm
- oracle-database-free-23c
wget https://download.oracle.com/otn-pub/otn_software/db-free/oracle-database-free-2…;
2) Installer le RPM "preinstall"
yum -y localinstall oracle-database-preinstall-23c-1.0-0.5.el8.x86_64.rpm
3) Installer Oracle 23c
yum -y localinstall oracle-database-free-23c-1.0-1.el8.x86_64.rpm
Au vu du volume (1,67Go) cela promet d'être assez long, mais cela se termine quand même.
Note :
Le paquet "preinstall" crée un fichier "/etc/sysctl.d99-oracle-database-preinstall-23c-sysctl.conf" qui contient tous les paramètres conseillés par Oracle, donc pas besoin de bricoler de ce coté.
La prochaine étape : configurer la base et cela se réalise (en tant que "root") avec :
/etc/init.d/oracle-free-23c configure
Ici pas de mode graphique, tout est enchaîné depuis le script de configuration.
Mysql et MariaDB
Mysql et MariaDB jppJ'ai rajouté un "chapeau" à d'anciens articles sur Mysql/PariaDB "Maître/esclave" en faisant une version plus "moderne" sur le même sujet : création d'un cluster MariaDB "Maître/Esclave", mais en allant un peu plus loin.
Note : la plupart des éléments cités dans ces articles s'appliquent aussi bien à MariaDB qu'à Mysql proprement dit.
- Premier article de 2013.
- Articles récents (2016, 2017)) qui vont plus loin sur le sujet en abordant quelques points supplémentaires:
- Possibilité de partir d'un serveur "plein" de données.
- Les "proxy" permettant d'exploiter plusieurs serveurs.
- Les problèmes et possibilités de "failover" en cas d'arrrêt du maître. L'arrêt peut être involontaire (panne ...) ou volontaire pour maintenance.
- Installation personnalisée de Mysql-community-server 5.7
- Test sur l'utilisation des "Huges pages".
- Utilisation des tables "FEDERATED" ou "FEDERATEDX".
- Mise en place d'une architecture maître/maître.
Bonne lecture ... et bons tests.
Mysql maitre / esclave (2013)
Mysql maitre / esclave (2013) jppArticle original de 2013.
Cette notion de maître / esclave permet diverses améliorations dont la principale est la sécurité, mais on peut y ajouter aussi des améliorations de performance qui seront précisées dans un autre article.
Dans cet exemple on part de deux machines (virtuelles) identiques avec des bases Mysql « vierges » .
Il faut d'abord vérifier la présence du paquet "libaio1" et dans un premier temps créer les mêmes utilisateurs initiaux avec les mêmes droits.
On passe ensuite aux opérations "sérieuses" :
Sur l'esclave modifier le fichier « my.cnf » et modifier le « server-id », 'jamais deux serveurs de même ID dans le même réseau) :
Ancien : server-id = 1
Nouveau : server-id = 2
Redémarrer le service.
Sur le maître :
Vérifier dans le fichier "my.cnf" que le « binlog » est bien activé (Ligne dé-commentée) :
log_bin = /var/log/mysql/mysql-bin.log
Redémarrer le service.
Sur la machine maître créer un utilisateur spécifique pour la réplication :
CREATE USER 'replicator'@'%' IDENTIFIED BY 'replicateur';
GRANT REPLICATION SLAVE ON *.* TO 'replicator'@'%';
Vérifier la connexion de l'esclave vers le maître avec votre utilisateur de réplication avec la commande suivante (sur l'esclave) :
mysql –host=maitre –user=replicator –password=replicateur
qui doit fournir une connexion correcte.
On peut alors, toujours sur l'esclave, le « lier » à son maître :
CHANGE MASTER TO MASTER_HOST='mysql1', MASTER_USER='replicator',
MASTER_PASSWORD='replicateur'; START SLAVE;
1) Les premiers tests (simples).
- Vérifier le fonctionnement sur l'esclave :
SHOW SLAVE STATUS;
qui doit vous retourner un rang donnant le "point" de la synchronisation notamment le numéro du fichier "mysql-bin" en cours et d'autres valeurs de la position courante.
- Créer une DATABASE.
Sur le maître créer une base :
CREATE DATABASE VALID ;
Sur l'esclave vérifier l'existence de la base :
USE DATABASE VALID ;
Une fois ce test passé on peut continuer avec
- Créer table :
Sur le maître on crée une table dans notre DB VALID :
CREATE TABLE TOTO ( zone char(6)) ;
On vérifie sur l'esclave :
DESC TOTO ;
Qui doit vous retourner la description de la table TOTO.
On peut ensuite, pour faire bien, insérer des choses dans notre table sur le maître.
insert into TOTO ( zone) values ( "un" );
insert into TOTO ( zone) values ( "deux" );
Dans notre base esclave :
select * from TOTO;
retourne :
+------+
| zone |
+------+
| un |
| deux |
+------+
2 rows in set (0.00 sec)
Ce qui est exceptionnel !!
2) Des tests plus évolués.
Que se passe-t-il maintenant si :
- on stoppe l'esclave
- on fait une insertion sur le maître :
insert into TOTO (zone) values (« trois »).
- on redémarre l'esclave et on effectue le « select » précédent , miracle il nous retourne bien :
+-------+
| zone |
+-------+
| un |
| deux |
| trois |
+-------+
3 rows in set (0.00 sec)
3) Remarques finales.
La procédure est ici très simple avec du matériel simple (virtuel ! ), dans la réalité il faudrait prévoir :
- deux liens réseau dont un spécifique à la réplication et qui serait un plus pour limiter au maximum la latence du système.
- de se servir de la base répliquée pour faire des sauvegardes tranquillement, sana perturber la machine "maître".
- de se servir de la machine "esclave" pour lancer de "gros" ordres SQL de statistiques qui perturberaient plus ou moins fortement le serveur principal.
Il reste très simple d'effectuer cette mise en réplication et cela est assez performant.
Mysql: 5.6.30,5.7.16,SSD
Mysql: 5.6.30,5.7.16,SSD jppAyant un petit serveur "libre", le malheureux chauffait tellement qu'il se plantait régulièrement et que j'ai du le remplacer vite fait (voir article). Lorsque je l'ai démonté pour voir ce qu'il avait dans le ventre j'ai touché le radiateur et j'ai entendu un petit "clic", depuis cet engin ne chauffe plus ! J'ai donc décidé de l'utiliser avec quelques "vieux" SSD qui traînaient dans un coin pour faire quelques tests avec Mysql.
J'ai utilisé une base disponible sur une autre machine et qui possède deux tables un peu volumineuses : 10 millions de rangs pour l'une et un peu plus de 100 000 pour l'autre, le tout "pesant" environ 4GO.
La machine d'origine que j'ai prise pour référence possède :
CPU CoreI5 à 3.4Ghz série 5
RAM 16 Go
Disques 2 disques 1To à 7200 tours en Raid 1
Mysql 5.6.30
La machine "ressuscitée" dispose de :
CPU CoreI3 à 3.4GHz série 4
RAM 16 Go
Disques 3 SSD assez anciens mais encore vaillants de 32 à 128Go.
Mysql 5.6.30 puis 5.7.16
J'ai essayé 2 configurations :
Standard, tout sur le même disque (SSD), répertoires /var/lib/mysql et /var/log/mysql
Optimisée système sur un disque, DATA (ex /var/lib/mysql) sur un SSD et LOG (ex /var/log/mysql) sur un autre SSD, bien qu'avec des ordres "SELECT" le log ne soit pas sollicité.
Remarques : Toutes les tables sont en InnoDB et la valeur de "innodb_buffer_size" est fixée à 2048M.
La suite bientôt ... c'est fait et c'est ICI.
Mysql : Maitre/esclave (2016)
Mysql : Maitre/esclave (2016) jppMysql : mise en cluster maître/esclave.
Vous disposez d'une belle application fonctionnant sur une non moins belle base de données Mysql qui contient tout ce qui est nécessaire à votre application.
Mais que se passera-t-il si votre base est indisponible (crash base, disque ayant rendu l'âme, prise de pied dans la prise de courant ....) ?
Votre belle application ne fonctionnera plus du tout ...
La solution : Clusteriser votre base de données en mode maître/esclave.
Oui, mais ma base existe déjà, comment faire ? Je n'ai pas envie de "dumper" toutes mes tables .... !!! et de les recharger.
C'est cette histoire que je vais vous conter.
Vous ne touchez pas à votre serveur original (il marche, ne pas le déranger), et vous préparez une merveilleuse machine, identique pour bien faire, et faites-y une installation complète de Mysql de préférence dans la même version, ici c'est du 5.6 ! Cela marche aussi très bien avec MariaDB.
Si la structure des répertoires de DATA n'est pas "standard" il vaut mieux refaire à l'identique, cela simplifiera toute la maintenance.
Un peu de vocabulaire pour la suite :
- Serveur1 : votre serveur "actuel"
- Serveur2 : le petit nouveau.
L'opération consiste à :
- Créer les utilisateurs nécessaires à la réplication (Serveur1).
- Stopper Mysql sur le Serveur1
- Sauvegarder l'intégralité des fichiers de la BDD, si vous utilisez LVM (ou BTRFS) vous pouvez faire un snapshot du support disque de votre base, et la relancer immédiatement. Sinon "tar" fonctionne encore ...
- Modifier le fichier de config de Serveur1
- Stopper Mysql sur Serveur2, et bien nettoyer les répertoires de Mysql, y compris les fichiers de "/var/log/mysql"
- Restaurer les données de Serveur1 sur Serveur2.
- Détruire un petit fichier sur Serveur2 (/var/lib/mysql/auto.cnf)
- Reparamétrer Serveur2 en esclave, et en "read-only", c'est plus prudent.
- Redémarrer Serveur2
Note : Il existe des moyens de faire une sauvegarde "on line" ce qui évite de stopper le serveur, mais dans ce cas il faut enregistrer la position dans le "binlog" pour permettre à l'esclave de repartir juste après la dernière transaction enregistrée.
Vous pouvez alors passer Serveur2 en mode "esclave" et Serveur2 sera maintenu à jour par rapport à Serveur1.
Un peu de détail pour arriver à ce Nirvana :
1) Créer les utilisateurs pour la réplication sur Serveur1 :
|
* create user 'replic_usr'@'192.168.2.62' identified by 'Mon_Secret'; create user 'replic_usr'@'192.168.2.63' identified by 'Mon_Secret'; |
Note :
Vous avez un Mysql installé sur Serveur2, vérifiez que le user "replic_usr" peut bien se connecter sur Serveur1 :
mysql -user=replic_usr --password=Mon_Secret -D mysql
Si tout va bien vous pouvez alors stopper Mysql sur Serveur2.
2) Une fois ceci réalisé stopper Mysql sur serveur 1.
Sauvegardez /var/lib/mysql et ici, en plus /DATA/D1 et /DATA/D2 pour compliquer un peu.
3) Pendant ce temps modifier votre fichier "mysqld.cnf" et ajoutez-y :
| ### pour Master server-id = 1 log-bin = mysql-bin binlog-format = MIXED log-slave-updates = true gtid-mode = on enforce-gtid-consistency= on master-info-repository = table report-host = mysql1 |
4) Stoppez Mysql sur Serveur2.
5) Transportez vos copies sur Serveur2 et restaurez les "en place".
6) Supprimer le fichier "auto.cnf" dans /var/lib/mysql.
6) Modifiez le fichier "mysqld.cnf", comme pour Serveur1 sauf "server-id" et "report-host":
| ### pour Slave server-id = 2 read-only = 1 log-bin = mysql-bin binlog-format = MIXED log-slave-updates = true gtid-mode = on enforce-gtid-consistency = 1 master-info-repository = table report-host = mysql2 |
7) C'est presque fini :
Redémarrez Mysql sur Serveur1 et verifiez dans le fichier "error.log" la présence du message :
/usr/sbin/mysqld: ready for connections.
Passons maintenant au Serveur2 :
Nettoyer certains fichier que vous venez de restaurer dans /var/lib/mysql :
- mysql-bin*
Son fichier de configuration est correct, bien vérifier que le fichier "auto.cnf" (il contient un UUID) "/var/lib/mysql/auto.cnf" est effacé avant de redémarrer le serveur qui va s'empresser de le recréer avec un nouvel "UUID" différent de celui de Serveur1.
On peut alors "asservir" notre futur esclave :
|
mysql -u root -p -D Le_mot_de_passe_qui_va_bien \q |
Qui devrait répondre gentiment :
Query OK, 0 rows affected, 2 warnings (0,31 sec)
Puis :
start slave;
qui répond (gentiment lui aussi) :
Query OK, 0 rows affected (0,11 sec)
Verifications :
Nos données sont-elles toujours sur le maître :
| mysql> show tables; +--------------------+ | Tables_in_test_del | +--------------------+ | ANAL_FIR_ARC | | ANAL_FIR_TEST | | TEST_LOG | +--------------------+ 3 rows in set (0,00 sec) |
Et sur l'esclave ?
| mysql> show tables; +--------------------+ | Tables_in_test_del | +--------------------+ | ANAL_FIR_ARC | | ANAL_FIR_TEST | | TEST_LOG | +--------------------+ 3 rows in set (0,00 sec) |
Rien ne s'est perdu en route, nos petites données sont maintenant en sécurité !
Maintenant créons une table sur le maître :
| create table toto ( zone varchar(32) ); Query OK, 0 rows affected (0,36 sec) mysql> show tables; +--------------------+ | Tables_in_test_del | +--------------------+ | ANAL_FIR_ARC | | ANAL_FIR_TEST | | TEST_LOG | | toto | +--------------------+ 4 rows in set (0,00 sec) |
Et sur l'esclave :
| mysql> sow tables; +--------------------+ | Tables_in_test_del | +--------------------+ | ANAL_FIR_ARC | | ANAL_FIR_TEST | | TEST_LOG | | toto | +--------------------+ 4 rows in set (0,00 sec) |
Allez on s'en refait un coup, sur le maître :
| mysql> insert into toto (zone) values ('Ah oui, comme cela est bon'); commit; |
Et sur l'esclave :
| mysql> select * from toto; +----------------------------+ | zone | +----------------------------+ | Ah oui, comme cela est bon | +----------------------------+ 1 row in set (0,00 sec) |
A bientôt pour la suite de ces passionnantes aventures dans le monde de Mysql.
MariaDB : maître maître
MariaDB : maître maître jppJ'ai décidé d'installer deux serveurs MariaDB (cela ne change que peu de Mysql) pour tester une configuration multi-maîtres. Pour cela il faut d'abord installer deux machines (virtuelles) identiques. J'ai choisi d'installer une Debian "Stretch" qui devrait prochainement passer en "stable".
Description des machines :
- CPU 2
- RAM 4096GB
- Disque système 16GB ext4
- Disque DATA 32GB LVM, partition "VGDATA/MYSQL" de 24GB montée sur /DATA/mysql.
Il restera ainsi 8GB pour effectuer des "snapshots" destinés à la sauvegarde (article à suivre).
Pour faciliter l'installation (IP et nom viennent "automagiquement) j'ai créé ces machines dans le serveur dhcp et je les ai insérées dans mon serveur DNS.
Installation des machines à partir d'une image de cd "debian-testing-amd64-xfce-CD-1.iso".
Pas de serveur WEB, serveur SSH plus quelques paquets indispensables.
apt-get install system-config-lvm iproute2 net-tools vim-gtk
et enlevé "network-manager" que je n'apprécie pas, je préfère le bon vieux fichier "/etc/network/interfaces" et gérer moi même /"etc/resolv.conf".
Ensuite j'ai installé MariaDB client et serveur en "standard" (je précise la version 10.1) :
apt-get install mariadb-client-10.1 mariadb-server-10.1
Quelques modifications dans le fichier /etc/mysql/mysqld.conf.d/50-server.cnf :
Mettre la BDD "en ligne" :
bind-address = 0.0.0.0
Dans le "bloc" InnoDB (par exemple) ajout de :
innodb-buffer-pool-size = 1024M
innodb_buffer_pool_instances = 2
innodb-file-per-table = 1
innodb_additional_mem_pool_size = 8M
innodb_log_file_size = 512M
innodb_log_buffer_size = 8M
innodb_read_io_threads = 2
innodb_write_io_threads = 2
innodb_stats_persistent = 1
innodb_stats_persistent_sample_pages = 512
Positionner la variable "server-id" à 1 pour le premier serveur et = 2 pour le second.
Ajouter dans le bloc "[mariadb-10.1]" :
innodb_flush_log_at_trx_commit = 2
event_scheduler = on
local_infile = 0
plugin-load=validate_password.so
skip-symbolic-links = 1
innodb_flush_method = O_DIRECT
binlog_row_image = minimal
#
concurrent_insert = AUTO
sync_binlog = 1
innodb_use_native_aio = 1
# Sans oublier d'activer le "bin-log" nécessaire au maître
log_bin = /var/log/mysql/mysql-bin.log
# et le format de log, je préfère "mixed" à "row" ou "statement"
binlog_format = mixed
Et pour terminer et éviter des problèmes dus aux tables avec identifiant en "auto-increment" :
Mettre chacune des deux machines (ou plus) sur des séries différentes. Ici l'une générera des identifiants pairs, l'autre des identifiants impairs réduisant ainsi à zéro les risques de collision.
Sur le serveur 1 :
auto_increment_increment = 1
Sur le serveur 2 :
auto_increment_increment = 2
et sur les deux machines :
auto_increment_offset = 2
La machine 1 génère ainsi la série 1,3,5,7 ....
la machine 2 la série 2,4,6,8 ....
Après ces quelques modifications on redémarre Mariadb pour valider nos modifications.
Il faut ensuite configurer le volume destiné aux données (LVM).
C'est pour cela que j'ai installé le peu gourmand "system-config-lvm",
Créer un volume "MARIADBDATA1" (partition 1 du second disque "/dev/xvdb1"), dans ce volume créer un LV "DATA" de 24GB conservant ainsi 8GB pour des snapshots.
Ce LV est créé en "ext4" et monté sur /DATA/mysql que l'on aura créé auparavant sans oublier un "chmod mysql:mysql /DATA/mysql".
Ensuite arrêter MariaDB et copier le contenu cd /var/lib/mysql dans le répertoire /DATA/mysql (après montage du disque bien sûr !) et remplacer le répertoire (renommé par sécurité !) d'origine par un lien /var/lib/mysql --> /DATA/mysql on peut alors redémarrer MariaDB.
Les deux machines ont été installées "à la main" (pas en copiant l'image disque) afin de bien vérifier la procédure d'installation.
Ces deux machines ont une structure identique, le report des données présentes dans le S1 est facilité :
- On arrête les deux services "mysql"
- On copie "bêtement les fichiers du répertoire /DATA/mysql de S1 dans celui de S2 (tar)
- On relance le service et on resynchronise les deux "masters" entre eux.
MariaDB : maître maître : sauvegarde
MariaDB : maître maître : sauvegarde drupadminOn a un beau système, performant, efficace, je vous laisse imaginer différentes manières de s'en servir mais on peut, par exemple :
- Spécialiser un serveur dans l'écriture, L'autre dans la lecture, par exemple pour la création de ces gros rapports dont raffolent certaines personnes et qui "écroulent" le serveur principal.
- Spécialiser une des machines en écriture, l'autre en lecture. On peu faire ce type d'utilisation à l'aide d'adresses IP virtuelles (1 pour l'écriture, l'autre pour la lecture), un système de fail-over permet en cas d'incident sur l'un des serveurs bascule les 2 VIP sur le serveur valide..
Une Sauvegarde quasi "ON LINE".
Sauvegarde non testée --> DANGER, n'oubliez de tester une restauration ...
MariaDB : maître/maître mise en place
MariaDB : maître/maître mise en place jppPassons maintenant à la pratique du passage en "maître / maître" !
Le principe du maître / maître est très simple, chaque machine est à la fois le maître et l'esclave de l'autre.
Cela impose quelques contraintes déjà connues telles que d'utiliser différentes valeurs de "server-id" et, comme précisé dans le précédent article, d'utiliser des valeurs correctes de "auto-increment-increment" et "auto-increment-offset" afin de limiter les risques de doublons.
Il est par ailleurs déconseillé d'utiliser les deux machines en écriture simultanément car un risque de corruption existe. Il est par contre intéressant au niveau de la performance globale d'utiliser une machine en écriture et de diriger vers l'autre les applications en lecture seule, particulièrement des applications grosses consommatrices de lecture : états et statistiques diverses. Le retard entre les deux machines est en général à peu près négligeable.
Ce type de redondance permet par contre un basculement extrêmement rapide en car d'incident sur le serveur "écriture". Les adresses IP virtuelles permettent de réaliser la basculement sans délai ni manipulation complexe et cela peut être automatisé à l'aide de divers outils.
Pour simplifier nous nommerons S1 et S2 les deux machines. Les deux opérations à réaliser sont extrêmement simples :
- Rendre S2 "esclave" de S1, et lorsque cela est réalisé passer à la phase suivante
- Rendre S1 "esclave" de S2.
1) Rendre S2 esclave de S1.
Les commandes suivantes permettent :
d'autoriser S2 à se connecter comme esclave :
|
/* /* |
|
/* start SLAVE; |
Lorsque cette opération est réalisée, on teste un peu en redémarrant chacun des deux serveurs et en vérifiant la synchro à l'aide des commandes :
SHOW MASTER STATUS;
et
SHOW SLAVE STATUS\G
(le \G permet un affichage plus agréable .... pour les quelques malheureux qui l'ignorent encore).
Il est alors possible d'effectuer les tests habituels de création de table et d'insertion de rangs en vérifiant bien que les séries des identifiants attribués diffèrent bien entre les deux machines. Cela marche aussi avec trois machines en utilisant les "bons" paramètres d'incrément pour créer les séries 1,4,7,10; 2,5,8,11 et 3.6.9.12 ...
Le maître/maître ... mais c'est très simple !
A partir de là, tout ce qui se passe dans un des deux serveurs est reproduit sur l'autre.
Si vous recopiez vos données par export (d'un autre système) + import dans le groupe maître/maître (vidé de préférence) cela fonctionne bien. Il faut, là encore, bien synchroniser vos deux serveurs avant le début de l'import des données.
L'import dans l'un des serveurs sera reproduit fidèlement dans le second.
A ce propos, si vous utilisez des "events" ils seront en état "ENABLED" dans le serveur dans lequel a été réalisé l'import et en l'état "SLAVE_DISABLED" dans l'autre. Ainsi pas de risque de déclenchement de deux traitements en parallèle.
Maitre / esclave : petits inconvénients
Maitre / esclave : petits inconvénients jppVous trouverez vite quelques inconvénients à cette réplication car certains ordres SQL ne fonctionnent pas (ou plus).
Par exemple "create table as select * from ... where AA = '3' ", bien commode pourtant, vous jettera à la figure un message :
ERROR 1786 (HY000): CREATE TABLE ... SELECT is forbidden when @@GLOBAL.ENFORCE_GTID_CONSISTENCY = 1.
En effet cette construction est un concentré de deux ordres SQL : CREATE TABLE + INSERT et comme il s'agit d'une seule transaction elle n'aura qu'un "Transaction ID" et le slave recevra deux ordres différents le CREATE et l'INSERT avec un même TID, or un bon esclave n'exécute pas deux fois le même ID de transaction, il ferait le CREATE mais pas l'INSERT !
C'est un peu stupide, mais on arrive à s'y faire.
D'autres inconvénients existent lors d'un mélange de tables MyISAM et InnoDB car InnoDB supporte les transactions mais pas MyISAM d'où d'autres messages parfois sybillins, mais je pense que vous n'avez plus de tables MyIsam ! C'est si facile de les convertir ...
C'est peut-être un bon motif pour abandonner le MyISAM au profit de InnoDB pour vivre dans un monde transactionnel et maître/esclave sans erreurs superflues et sans "CREATE TABLE ... AS SELECT" (sniff).
Ah, aussi, on ne peut pas créer de tables temporaires dans une transaction, il faut les créer en dehors de tout contexte transactionnel pour que cela se passe bien.
Il semble d'ailleurs que le problème du "CREATE AS SELECT" soit résolu dans les dernières versions en choisissant bien le bon mode pour le binlog_mode.
Mysql-community-server personnalisé
Mysql-community-server personnalisé jppJ'ai voulu installer la version 5.7 de Mysql depuis le repository de Mysql en chargeant depuis le site le paquet "Ubuntu / Debian (Architecture Independent), DEB" qui installe notament un fichier "mysql.list" dans /etc/apt/sources-list.d, ensuite on utilise les outils standard Debian : aptitude, apt-get ou synaptic.
Remarque : j'ai inhibé le repository "mysql-tools-preview"
Un "apt-get update" plus loin les choses sont disponibles et on peut installer "mysql-community-client" et "mysql-community-server" version 5.7.16
J'ai voulu réaliser une installation non "standard" en positionnant les fonctionnalités principales de la base de données sur des systèmes de fichiers différents notamment pour la partie "log" et pour la partie "données" afin d'optimiser le fonctionnement.
La machine est munie de :
- CPU CoreI3 4330
- RAM 16G
- 3 disques SSD
Selon le schéma suivant :
Un système de fichier racine
Un système de fichier /DATA/DATA1 pour les données
Un système de fichier /LOG/LOG1 pour les logs y compris les "logbin".
J'ai configuré le fichier /etc/mysql/mysql.conf.d/mysqld.cnf de la façon suivante :
| [mysqld] pid-file = /run/mysqld/mysqld.pid socket = /run/mysqld/mysqld.sock # By default we only accept connections from localhost bind-address = 0.0.0.0 # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 ### Deplacement des répertoires datadir = /DATA/DATA1/mysql tmpdir = /LOG/LOG1/mysql_tmp log_bin = /LOG/LOG1/mysql/server-bin general_log_file = /LOG/LOG1/mysql/general.log slow-query-log-file = /LOG/LOG1/mysql/slow_query.log server_id = 11 log_error = /LOG/LOG1/mysql/error.log secure-file-priv = /DATA/DATA1/mysql-files slave_load_tmpdir = /LOG/LOG1/mysql_tmp ### configuration InnoDB |
....
Nettoyez toute trace de l'installation imposée lors du démarrage (/var/lib/mysql, /var/log/mysql).
Vérifiez bien que tous vos répertoires "mysql" ont bien le user et le groupe "mysql" :
| cd /DATA//DATA1 ls -al drwxr-xr-x 6 root root 4096 nov. 18 20:00 . drwxr-xr-x 4 root root 4096 nov. 14 23:27 .. drwx------ 2 root root 16384 nov. 12 22:24 lost+found drwxr-xr-x 5 mysql mysql 4096 nov. 18 20:26 mysql drwx------ 2 mysql mysql 4096 nov. 18 20:02 mysql-files cd /LOG/LOG1 drwxr-xr-x 6 root root 4096 nov. 17 23:22 . drwxr-xr-x 4 root root 4096 nov. 15 00:21 .. drwx------ 2 root root 16384 nov. 15 00:21 lost+found drwxr-xr-x 2 mysql mysql 4096 nov. 18 20:04 mysql drwx------ 2 mysql mysql 4096 nov. 18 20:22 mysql-files drwxr-xr-x 2 mysql mysql 4096 nov. 18 20:25 mysql_tmp |
Il faut maintenant attaquer la partie "systemd" et la corriger pour éluder un script (horrible) rempli de valeurs "en dur" qui viendrait perturber la belle ordonnance de nos paramètres.
Ce script (/usr/share/mysql/mysql-systemd-start) est à ignorer purement et simplement et à remplacer par un petit script destiné uniquement à initialiser correctement le répertoire "mysqld" dans /run (et pas /var/run qui n'est qu'un lien vers /run) ce script hyper simple (je l'ai appelé "init-mysql") il est fourni à titre d'exemple :
| #!/bin/bash MYSQLRUN=/run/mysqld if [ ! -d ${MYSQLRUN} ] then mkdir ${MYSQLRUN} chown mysql:mysql ${MYSQLRUN} fi |
Ce n'est vraiment pas grand chose !
Attention ce script est exécuté par le user "mysql", le mettre dans /usr/bin par exemple pour qu'il soit accessible sans difficultés.
Modifier le script "systemd" de lancement du service (/lib/systemd/system/mysql.service) pour en extirper la référence à l'horrible "mysql-systemd-start" :
Partie du script "systemd" modifié :
| [Service] User=mysql Group=mysql Type=forking PermissionsStartOnly=true PIDFile=/run/mysqld/mysqld.pid ExecStartPre=/usr/bin/init_mysql ExecStart=/usr/sbin/mysqld --daemonize --pid-file=/run/mysqld/mysqld.pid TimeoutSec=60 LimitNOFILE = 5000 Restart=on-abort RestartPreventExitStatus=1 RuntimeDirectory=mysqld RuntimeDirectoryMode=755 Ne pas oublier ensuite "systemctl daemon-reload" avant de relancer le service. Aller modifier le fichier /etc/mysql/conf.d/mysql.cnf (utilisé par le client mysql) pour y indiquer le nom du fichier "socket" : [mysql] socket = /run/mysqld/mysqld.sock |
On doit encore réaliser un petit truc bizarre, créer un lien entre :
/etc/mysql/mysql.conf.d/mysqld.cnf et /etc/my.cnf ???
On peut alors, enfin, lancer une installation "personnalisée" de l'ensemble en utilisant le paramètre "--initialize--insecure" de mysqld, adieu "mysql_install_db" on ne te regrettera pas trop.
mysqld --initialize-insecure
qui crée le user "root" sans mot de passe, il suffira d'en mettre un rapidement avec la commande "set password ..." pour rester correct, la commande se termine rapidement, SSD oblige.
Cette commande a rempli les répertoires prévus /DATA/DATA1/mysql de ce qui se trouve dans /var/lib/mysql habituellement.
Tout semble prêt on lance la commande fatidique :
service mysql start
qui rend la main rapidement (tout est sur des SSD), on vérifie un peu si tout va bien :
| ps -ef | grep mysqld mysql 2733 1 2 22:52 ? 00:00:00 /usr/sbin/mysqld --daemonize --pid-file=/run/mysqld/mysqld.pid |
puis :
| ls -al /run/mysqld drwxr-xr-x 2 mysql mysql 100 nov. 18 22:52 . drwxr-xr-x 23 root root 860 nov. 18 22:52 .. -rw-r----- 1 mysql mysql 5 nov. 18 22:52 mysqld.pid srwxrwxrwx 1 mysql mysql 0 nov. 18 22:52 mysqld.sock -rw------- 1 mysql mysql 5 nov. 18 22:52 mysqld.sock.lock |
Tout à l'air parfait on lance le client mysql :
| mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.7.16-log MySQL Community Server (GPL)Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> |
Ouaaaah tout baigne, vite mettons un mot de passe à ce vieux "root" :
use mysql;
mysql> set password for 'root'@'localhost' = PASSWORD('Un_BeAu_#_PaSsWoRd_ToUt%Neuf?');
\q
Et on teste notre mot de passe :
|
mysql --user=root -p mysql>\q |
C'est fini, on dispose d'une base toute neuve en version 5.7.16. Montée sur des systèmes de fichiers SSD cela devrait être assez rapide !
A bientôt pour quelques tests.
Mysql : Maitre/esclave avec proxy
Mysql : Maitre/esclave avec proxy jppMettre l'esclave au boulot ! Pour réaliser cet exploit il faut utiliser un "proxy intelligent" capable de distinguer les ordres en lecture seule (SELECT) et les autres (le SELECT ... FOR UPDATE) est un piège.
Le proxy que j'ai choisi de tester s'appelle "ProxySql", nom très original s'il en est, mais il fonctionne fort bien et est assez simple à manipuler.
Le paquet est téléchargeable (V1.2.1 au moment de ces tests) à :
https://github.com/sysown/proxysql/releases/download/v1.2.1/proxysql_1.2.1-debi…
La liste complète des téléchargements est accessible à l'URL:
https://github.com/sysown/proxysql/releases/
L'installation se fait sans mystère par :
dpkg -i proxysql_1.2.1-debian8_amd64.deb
Un script d'init est installé ainsi qu'un fichier de configuration /etc/proxysql.cnf, un répertoire /var/lib/proxysql est créé, de la doc /usr/share/doc ... Tout a l'air présent !
Le service n'est pas démarré par défaut, après un "service proxysql initial" (pour la première fois) le service est lancé et écoute sur les ports 6032 et 6033 (paramètres par défaut).
Ce paramètre "initial" permet d'initialiser la base de données interne de proxysql.
Si vous n'avez pas personnalisé un minimum votre fichier "proxysql.cnf" vous pouvez le modifier et repasser un petit coup de "initial". Au passage renommer rapidement ce fichier sinon au prochain démarrage il sera réutilisé !
Proxysql utilise syslog et vous trouverez ses messages dans /var/log/daemon.log
Par la suite on n'aura plus besoin de repasser le paramètre "initial", sauf pour réparer une "grosse bêtise".
Testons maintenant la connexion à Proxysql (user/mot de passe fixés dans proxysql.cnf) :
| mysql -u admin -p -h 127.0.0.1 -P 6032 Enter password: admin Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.5.30 (ProxySQL Admin Module) Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> |
Cela a un petit air connu ...
Remarque : la connexion par défaut est sur la base "main" :
| mysql> show databases; +-----+---------+-------------------------------+ | seq | name | file | +-----+---------+-------------------------------+ | 0 | main | | | 2 | disk | /var/lib/proxysql/proxysql.db | | 3 | stats | | | 4 | monitor | | +-----+---------+-------------------------------+ 4 rows in set (0,00 sec) mysql> use main; show tables; +--------------------------------------+ | tables | +--------------------------------------+ | global_variables | | mysql_collations | | mysql_query_rules | | mysql_replication_hostgroups | | mysql_servers | | mysql_users | | runtime_global_variables | | runtime_mysql_query_rules | | runtime_mysql_replication_hostgroups | | runtime_mysql_servers | | runtime_scheduler | | scheduler | +--------------------------------------+ mysql> use disk; show tables; +--------------------------------------+ | tables | +--------------------------------------+ | global_variables | | mysql_collations | | mysql_query_rules | | mysql_replication_hostgroups | | mysql_servers | | mysql_users | | runtime_global_variables | | runtime_mysql_query_rules | | runtime_mysql_replication_hostgroups | | runtime_mysql_servers | | runtime_scheduler | | scheduler | +--------------------------------------+ \q |
Tiens ? Les mêmes tables sont présentes dans les bases "disk" et "main".
On peut "regarder" le contenu des tables par des ordres "SELECT", ajouter des choses par "INSERT", modifier par "UPDATE", et faire des "DELETE". La plupart des commandes de Mysql fonctionnent (sauf "desc" ?).
Pour faire des modifications "rollbackables" il faut les faire au sein d'une transaction explicite (begin transaction;), le rollback sera ainsi possible.
Le proxy dispose de deux règles par défaut "Select for update" et "select" qui envoyent respectivement sur les "hostgroups" 0 et 1, traditionnellement le "0" est le maître (celui qui peut effectuer des modifications de la base) et le groupe 1 celui des esclaves en lecture seule.
On se dépêche de changer le user "admin:admin" en autre chose de plus sécurisé :
update global_variables set variable_value = 'new_admin:admin_new' where variable_name = 'admin-admin_credentials';
Attention aux '-' , ":" et aux '_' !!!
Vous avez certainement remarqué les noms des tables doublés entre :
global_variables
runtime_global_variables
.....
Après une modif dans les tables "sans préfixe" il faut les recopier dans les tables "runtime" puis les sauvegarder sur disque pour rendre les modifications permanentes.
On peut ainsi préparer une nouvelle config dans les tables "sans préfixe" qui ne sont pas actives puis la basculer sur les tables "runtime" ce qui les rend actives.
Cela se fait à l'aide de commandes "LOAD" et "SAVE".
Dans notre cas de modfification de l'accès administrateur il faut :
Le reporter dans le "runtime"
LOAD MYSQL VARIABLES TO RUNTIME;
et les sauvegarder pour la postérité :
SAVE MYSQL VARIABLES TO DISK;
Dès que vous avez changé le user/mot de passe administrateur vous pouvez (devez) :
- Détruire (ou renommer) le fichier /etc/proxysql.cnf
- Redémarrer le service proxysql
Votre nouveau user/mot de passe sera alors actif.
Pour les tests le hostgroup 0 est une VM Mysql "master", le hostgroup 1 est une VM Mysql "slave" de la première qui ne recevra que les ordres "SELECT" purs exempts de toute clause "FOR UPDATE".
On revient un peu en arrière et on va voir la config postée initialement dans le fichier "proxysql.cnf" pour nos serveurs Serveur1 (master) et Serveur2 (slave) :
| mysql_servers = ( { address="mysql1" , port=3306 , hostgroup=0 , max_connections=10 }, { address="mysql2" , port=3306 , hostgroup=1 , max_connections=10 } ) mysql_users: ( { username = "test" , password = "test", default_hostgroup = 0, active = 1 } ) |
Si on regarde (avec notre nouvel "admin") l'état de la table mysql_servers :
| select * main.from mysql_servers; *************************** 1. row *************************** hostgroup_id: 0 hostname: mysql1 port: 3306 status: ONLINE weight: 1 compression: 0 max_connections: 10 max_replication_lag: 0 use_ssl: 0 max_latency_ms: 0 *************************** 2. row *************************** hostgroup_id: 1 hostname: mysql2 port: 3306 status: ONLINE weight: 1 compression: 0 max_connections: 10 max_replication_lag: 0 use_ssl: 0 max_latency_ms: 0 2 rows in set (0,00 sec) |
C'est bien l'état indiqué dans le fichier original ,vérifions maintenant nos règles de répartition :
| mysql> select * from mysql_query_rules\G *************************** 1. row *************************** rule_id: 1 active: 1 username: NULL schemaname: NULL flagIN: 0 client_addr: NULL proxy_addr: NULL proxy_port: NULL digest: NULL match_digest: NULL match_pattern: ^SELECT .* FOR UPDATE$ negate_match_pattern: 0 flagOUT: NULL replace_pattern: NULL destination_hostgroup: 0 cache_ttl: NULL reconnect: NULL timeout: NULL retries: NULL delay: NULL mirror_flagOUT: NULL mirror_hostgroup: NULL error_msg: NULL log: NULL apply: 1 *************************** 2. row *************************** rule_id: 2 active: 1 username: NULL schemaname: NULL flagIN: 0 client_addr: NULL proxy_addr: NULL proxy_port: NULL digest: NULL match_digest: NULL match_pattern: ^SELECT negate_match_pattern: 0 flagOUT: NULL replace_pattern: NULL destination_hostgroup: 1 cache_ttl: NULL reconnect: NULL timeout: NULL retries: NULL delay: NULL mirror_flagOUT: NULL mirror_hostgroup: NULL error_msg: NULL log: NULL apply: 1 2 rows in set (0,00 sec) |
C'est bien ce que nous voulions installer.
Quand à notre user il semble lui aussi OK :
| select * from MYSQL_USERS\G *************************** 1. row *************************** username: test password: test active: 1 use_ssl: 0 default_hostgroup: 0 default_schema: schema_locked: 0 transaction_persistent: 0 fast_forward: 0 backend: 1 frontend: 1 max_connections: 10000 |
Tout cela a l'air bel et bon.
Site à voir :
http://severalnines.com/blog/how-proxysql-adds-failover-and-query-control-your-mysql-replication-setup
Mysql huges pages or not
Mysql huges pages or not jppAfin de mesurer l'influence des "huge pages" j'ai réalisé deux séries de tests :
- en utilisant les "huge pages", 8 Go alloués aux huge pages + paramètre "large-pages" dans la config Mysql.
- sans les utiliser, vm.nr_hugepages = 0 dans sysctl.conf, pas de paramètre "large-pages" pour Mysql.
Remarques liées à la version 5.7.16 :
Lors du chargement des données, à partir d'un dump depuis une machine 5.6.30, j'ai remarqué quelques différences de comportement entre les versions 5.7.16 et 5.6.30 :
- certaines valeurs de "datetime" donnent des erreurs à l'importation des données, par exemple "000-00-00 00:00:00", valeur utilisée par défaut en 5.6 sont refusées à l'import en 5.7. Ceci m'a obligé à "corriger" les valeurs dans les tables originales pour que les tables soient importées.
- la présence en double d'une colonne dans un ordre "select" est indiquée comme erreur : "ERROR 1060 (42S21): Duplicate column name 'CODPAYS'"
Conditions du test :
Afin de ne mesurer que l'influence de la mémoire la taille du "innodb_buffer_pool_size" a été portée à 6Go afin que l'intégralité des données se trouve en cache (total données #4Go). Le "dashboard" de mysql-workbench donne le cache rempli à 70%.
Les valeurs de "query_cache" sont à zéro pour inhiber les fonctions de cache de requêtes.
Les valeurs allouées à "max_heap_table_size" et "tmp_table_size" ont été fixées à 256M pour réaliser toutes les opérations en mémoire.
Chaque test a été précédé d'un redémarrage complet de la machine pour bien "enregistrer" la configuration des "huge pages" sans désorganiser la mémoire afin de bénéficier de performances non biaisées.
Les tests ont chaque fois été précédés de deux tours de chauffe afin de charger les buffers et effectivement après le premier tour de chauffe on ne constate plus d'IO sur le disque "DATA" et quelques IO sur le disque où sont placées les tables temporaires.
Pour simplifier les tests, les ordres qui affichent des lignes ont été "entouré de "select from ( ...... ) xx;" afin de limiter l'affichage au nombre de lignes du résultat et au temps d'exécution.
Chaque test a été lancé trois fois en respectant l'ordre 1 .. 7, 1 .. 7, 1.. 7, les chiffres du tableau (en secondes) sont le total des trois passages.
| Secondes | |||
| N0 test | Huge inhibé | Huge activé | Delta % |
| TEST 1 | 28,09 | 27,91 | -0,64% |
| TEST 2 | 5,81 | 5,75 | -1,03% |
| TEST 3 | 0,49 | 0,47 | -4,08% |
| TEST 4 | 3,10 | 3,03 | -2,26% |
| TEST 5 | 2,87 | 2,88 | 0,35% |
| TEST 6 (join + OR) | 49,37 | 49,06 | -0,63% |
| TEST 6 (union) | 46,49 | 46,25 | -0,52% |
| TEST 7 | 17,70 | 17,52 | -1,02% |
| TOTAL | 153,92 | 152,87 | -0,68% |
Commentaires :
L'amélioration, bien que visible et a peu près constante sur les tests, reste faible : #0,7% sur le total des tests, mais elle devrait être un peu plus nette sur des tailles de buffers élevées, des "buffer_pool" de plus de 100 Go sont courants sur de "vraies" bases que dépassent couramment les 400 Go.
Note 2021 : des tests réalisés avec des versions récentes de MariaDB donnent le même genre de résultats.
MySQL : utilisation tables Federated(x)
MySQL : utilisation tables Federated(x) jppLes tables "FEDERATED" sont des tables "distantes" sur un système différent.
Les tables de type "FEDERATED" permettent la communication (facile) entre deux bases MySQL (et même non-MySQL, par exemple MariaDB).
Ce plugin est relativement insensible aux versions des bases utilisées.
Remarque : pour MariaDB l'utilisation du plugin "ha_federated.so" est à déconseiller car ce plugin n'est plus maintenu ... mais remplacé par "ha_federatedx.so" qui, lui, est toujours maintenu et a un fonctionnement compatible. Même avec le plugin "federatedx" il faut ajouter "federated" dans votre fichier de configuration.
Pour MariaDB le "nec plus ultra" est d'utiliser un nouveau plugin "connect" dont je vous proposerais un test prochainement.
Un petit exemple d'utilisation de "federated" :
- Je dispose d'une machine "A" qui gère les tables utilisées par NtopNG, je ne veux pas laisser dans cette machine un trop gros volume de donnnées car NtopNG est assez consommateur d'espace et j'ai limité a 30 jours la rétention des données.
- Je voudrais disposer d'un historique plus "long" sur une machine "B" pour pouvoir m'amuser à faire des analyses à plus long terme.
La gestion du transfert des données de A vers B m'a posé quelques problèmes, car les solutions "classiques" ne sont pas faciles à gérer :
- Extraction dans une table "tampon" des données de la dernière semaine,
- Export de la table tampon par mysqldump,
- Transfert du ficher export
- Import dans une table tampon
- Intégration dans la table définitive.
Les rangs de la table principale sont identifiés par un ID en auto-incrément et il est donc aisé de repérer ceux qui manquent dans la machine "B" et c'est là que se profile l'utilisation d'une table "FEDERATED" Mysql.
En effet il suffit de déclarer dans la machine "B" une table identique à la table principale de "A" avec "engine=FEDERATED" pour accéder de "B" vers "A". La création est simple et toutes les opérations se font sur la machine "B". Il faut quand même vérifier que "monuser" a bien accès à la base "A" depuis l'adresse de "B" :
-
Créer un "serveur" :
create server xxxxxxx
foreign data wrapper mysql
options (USER 'monuser', PASSWORD 'monpassword', HOST '192.168.x.y', DATABASE 'mabaseA'); -
Créer une "table" FEDERATED (IDX = PRIMARY KEY) :
create table table_distante
( ......
KEY (IDX),
....
) engine=FEDERATED connection='xxxxxxx/table_sur_serveur_A';
Ensuite récupérer les données sur B est hyper simple :
|
select max(idx) into @IDMAX from table_sur_B; insert into table_sur_B select * from table_distante commit; |
Et en plus c'est assez rapide comme le montre la trace suivante :
|
-------------- Query OK, 1 row affected (0,03 sec) -------------- +----------+ -------------- Query OK, 532917 rows affected (7,30 sec) |
Plus de 530 000 rangs en 7,3 secondes ... c'est bien plus rapide que la manip "old style" et surtout bien plus simple !
La base distante est ici une base Mysql mais cela marche aussi avec d'autres bases ... Oracle, Postgres ... selon les modules disponibles.
Attention toutefois, un bête "select" ne passant pas par un index entraînera le transport de toute la table en local (temporaire) et peut durer assez longtemps et être très consommateur de ressources (disque et mémoire), donc éviter comme la peste les ordres n'utilisant pas correctement un index, mon exemple utilise la Primary Key et est donc très rapide.
Mariadb : Connect Engine
Mariadb : Connect Engine jppLe "vieux" plugin "federated" n'est plus maintenu, il existe une autre version "federatedx" qui fonctionne correctement sur Mysql (détails ici), je ne l'ai pas testée récemment sur MariaDB.
La méthode "IN" préconisée aujourd'hui pour MariaDB est d'utiliser le plugin "CONNECT". Celui-ci met à votre disposition un nouvel "ENGINE" qui permet la connexion à des bases distantes (de diverses saveurs), à des fichiers "plats", du Xml, du Json.
Le "CONNECT ENGINE" fait parfois partie des distributions stantard sur Linux :
- Debian/Ubuntu : apt install mariadb-plugin-connect
- RedHat/Centos/Fedora : yum install MariaDB-connect-engine
Ensuite il suffit de l'activer (avec un utilisateur qui a des droits suffisants !) :
| mysql --user=... -p prompt> INSTALL SONAME 'ha_connect'; prompt> \q |
Ensuite on pourra passer aux choses sérieuses ...
La création des tables reste classique, quelques exceptions notables :
- Pas de champ en AUTO_INCREMENT --> utiliser des séquences gérées "à la main" (MariaDB >= 10.3).
- Un champ présent dans un index doit absolument être spécifié "NOT NULL".
- Pas de champs TEXT/BLOB, ça c'est un peu dommage !
- Les clefs d'index ne doivent pas dépasser 255 caractères.
En ce qui concerne l'accès à une base Mysql/MariaDB le protocole étant standardisé il suffit d'indiquer après les définitions d'index :
| ... définition des données et index ... ) Engine=CONNECT DEFAULT CHARSET xxxxxx table_type=mysql connection='mysql://USER/PASSWORD@HOST/DATABASE/TABLE'; |
La table est crée et permet un accès direct aux données. On peut, bien sûr, utiliser un mélange de tables locales et distantes dans le même ordre SQL.
Je m'en suis notamment servi pour repérer des différences au sein d'un cluster maître/maître qui avait subi quelques manipulations hasardeuses au niveau de la définition des GTID des slaves (mélange entre gtid_slave_pos et gtid_current_pos).
Quelques tests rapides.
Les tests ont été réalisés sur deux VM identiques Debian 10 sur KVM :
2 vcpu, 2Go de RAM, une seule partition disque de 127Go sur une carte M2, MariaDB 10.3.23 paramétré avec un cache InnoDB de 1Go et 4 pool instances.
Chaque machine dispose de deux tables locales quasiment identiques, les tables notées "Z_..." sont des tables distantes, celles notées "D_..." sont des tables locales. L'espace disque est d'environ 1,7Go par table.
Mysql redémarré avant le premier test (caches vidés) :
Un test rapide de comptage sur table distante.
|
select count(*) from Z2_TABLE_DISTANTE select count(*) from Z2_TABLE_DISTANTE; |
L'effet du cache n'est ici pas énorme, même pas 10% de gain.
Test sur la même table en local :
|
select count(*) from D2_TABLE_LOCALE select count(*) from D2_TABLE_LOCALE; |
L'effet du cache est ici beaucoup plus notable ...
Autre test : jointures entre table distante et table locale :
| select count(*) from Z1_TABLE_DISTANTE Z1 join D2_TABLE_LOCALE D2 on D2.ID = Z1.ID; +----------+ | count(*) | +----------+ | 1454065 | +----------+ 1 row in set (6.093 sec) select count(*) from D1_TABLE_LOCALE Z1 join D2_TABLE_LOCALE D2 on D2.ID = Z1.ID +----------+ | count(*) | +----------+ | 1454065 | +----------+ 1 row in set (4.349 sec) |
Les performances sont ici très correctes la différence de temps d'exécution est relativement faible ce moteur est très facile à utiliser et présente des performances intéressantes.
Autre test :
Voir la différence entre le traitement d'une table "locale" et d'une table "pseudo distante" (déclarée comme une table distante mais utilisant l'adresse de la machine locale) :
|
select count(*) from Z2_TABLE_PSEUDO_DISTANTE; select count(*) from TABLE_LOCALE; | count(*) | |
La différence est assez significative, j'ai refait plusieurs essais pour éliminer l'influence du cache mais la table utilise environ 13 Go d'espace disque, le cache de 1Go ne joue que peu.
MariaDB et Galera
MariaDB et Galera jppJ'ai décidé de faire un test de la dernière version de MariaDB associée à Galera, non ce n'est pas la galère, puis y associer Maxscale.
Ceci nécessite une certaine infrastucture (ici réalisée avec des machines virtuelles KVM) :
- 1 machine pour Maxscale
3 machines pour MariaDB/Galera
Pourquoi trois machines ?
Parce que avec seulement deux machines un système plus simple est possible et qu'un système comme Galera se comporte mieux avec 3 machines car cela permet d'éviter des duels fratricides en cas d'incident sur une des machines ce que les anglicistes nomment "split brain" et je n'ai pas de traduction sensée à fournir !
Le test de Maxscale est repoussé car bien que IPV6 soit inhibé ici, le module de traitement "lecture seule" cherche un utilisateur avec une adresse "bizarre" de style "IPV6" et refuse donc la connexion.
L'accès lecture/écriture, lui, fonctionne fort bien mais je voudrais trouver l'explication de ces adresses "fantaisie" pour le module lecture-seule avant de passer à des tests complets.
Je n'ai pas réglé ce problème pseudo "IPv6", mais après une mise à jour cela ne semble plus se produire ...
Installation machines BDD
Installation machines BDD jppPréambule.
Les configurations suivantes sont adoptées, elles sont "légères" mais largement suffisantes pour nos tests :
- GALE_1 : future machine "Maxscale"
Disque 40GB
Mémoire 2048M
2 VCPU
- GALE-2, GALE-3 et GALE-4 nos trois machines bases de données :
Disque 40GB
Mémoire 4096M
2 VCPU
Le partitionnement adopté, volontairement simple, est suffisant pour des tests :
/boot 656Mo
/ 36Go
Swap 3,5Go
Les deux premières machines ont été installées "normalement" à partir d'une image ISO, les machines 3 et 4 ont été "clonées" depuis la machine 2 après l'installation de la base de données et les premiers tests de validation. "dd" est un bon ami.
Installation.
Il faut commencer par installer la définition du repository spécifique à MariaDB qui installe tout ce qu'il faut pour MariaDB, Maxscale et quelques outils complémentaires.
- Commencer par installer les outils curl, net-tools, vim ou gvim-gtk3 ...
Pour pouvoir ensuite installer, valider, suivre et mettre à jour confortablement tout ce qu'il faut pour un système "normal".
- Installer le repository MariaDB :
curl -LsS https://r.mariadb.com/downloads/mariadb_repo_setup | sudo bash
Ce script gère tout, y compris un "apt update" pour mettre à jour les listes de paquets.
Comme les machines sont installées en Debian Bullseye on est limité aux versions 10.5 de MariaDB, 22.08 de Maxscale et Galera 3 ou 4 (on utilisera bien sûr la version 4).
- On installe ici (GALE-2) MariaDB et Galera :
apt install mariadb-client-10.5 mariadb-server-10.5 galera-4
Cela récupère un paquet de dépendances : #28Mo d'archives et promet d'occuper 213MO sur disque.
Après le fatidique "sysctl start mariadb" tout se passe bien !
Lancée sous "root" la commande "mysql" nous lance gentiment le client connecté à notre nouvelle base.
On peut alors mettre un mot de passe à l'utilisateur "root", limité à localhost et créer un compte spécifique d'administration avec une visibilité plus importante (/24 par exemple). Bien le faire avant le clonage de GALE-2 sur les deux machines suivantes.
Le système "modèle" est prêt et on peut le cloner dans les deux autres machines, il suffira de changer :
- hostname /etc/hostname
- IP /etc/network.interfaces IP statiques
et pour la base MariaDB.
- server_id /etc/mysql/mariadb.conf.d/50-server.cnf
y mettre 2,3 et 4, les numéros de nostrois braves machines.
Maintenant que nos trois machines bases de données sont prêtes on va pouvoir passer à la mise en service de Galera ce qui promet d'être plus amusant.
Avant de se lancer dans Galera proprement dit il vaut mieux "arranger un peu" la configuration de MariaDB.
Par exemple mettre les fichiers "binlog" ailleurs que dans /var/log/mariadb !
J'ai donc ici créé un répertoire /var/lib/binlogs :
mkdir /var/lib/binlogs
chown mysql: /var/lib/binlogs
et modifié en conséquence le fichier /etc/mysql/mariadb.conf.d/50-server.cnf.
Galera en route
Galera en route jppPour Galera le fichier de paramétrage est /etc/mysql/mariadb.conf.d/60-galera.cnf, voir ci-dessous mon paramétrage :
#
# * Galera-related settings
#
[galera]
# Mandatory settings
wsrep_on = ON
wsrep_provider = "/usr/lib/libgalera_smm.so"
wsrep_cluster_name = "clustertest"
#
wsrep_node_name = gale-2
wsrep-node-address = 192.168.2.153
#
wsrep_cluster_address = "gcomm://192.168.2.153,192.168.2.154,192.168.2.155"
binlog_format = row
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
# Allow server to accept connections on all interfaces.
bind-address = 0.0.0.0
# Optional settings
wsrep_slave_threads = 1
innodb_flush_log_at_trx_commit = 0
# pour restart si cluster planté
wsrep_provider_options="gcache.recover=yes"Pour le premier lancement il faut impérativement utiliser la commande suivante :
mysqld --wsrep-new-cluster
sur chacun des trois membres du cluster.
Malheureusement cette commande ne "rends pas la main" j'ai donc du passer par la suite de commandes suivantes :
mysqladmin shutdown
systemctl start mariadb
pour "rendre la main" et démarrer normalement, j'ai fait cela sur chacun des nœuds en laissant un petit temps intermédiaire pour laisser les machines se re-synchroniser.
Pour contrôle je crée une base :
CREATE DATABASE montest;
Et je vérifie qu'elle est bien créée sur les trois nœuds, youpi cette base existe bien partout ... c'est le pied.
De même la création d'une table de test est parfaitement répliquée sur les trois nœuds :
Create Table: CREATE TABLE `TT` (
`ID` bigint(20) NOT NULL AUTO_INCREMENT,
`ZONE` varchar(32) DEFAULT NULL,
PRIMARY KEY (`ID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
Vérifions maintenant l'insertion :
Sur le nœud gale-2 (nœud 1) :
insert into TT (ZONE) values ('UN');
Sur les deux autres nœuds on voit :
select * from TT;
+----+------+
| ID | ZONE |
+----+------+
| 3 | UN |
+----+------+Tiens, l'autoincrement débute à 3 ?
Voyons voir un insert sur le nœud gale-3 (nœud 2) :
insert into TT (ZONE) values ('DEUX');
L'ID généré est égal à 5.
Un insert sur le nœud gale-4 (nœud 3) :
insert into TT (ZONE) values ('TROIS');
L'ID généré est égal à 7;
Retour sur le nœud 1 qui génère un ID à 9;
En bref cela à l'air de bien fonctionner ...
On essaye un arrêt de toutes les machines machines, puis on les redémarre, et ... c'est la catastrophe, rien ne redémarre.
Il faut chercher quel était le nœud "maître" en examinant les fichiers "grastate.dat" (dans /var/lib/mysql) et chercher celui qui possède la ligne "safe_to_bootstrap: 1".
Ici c'est le nœud "gale-4" qui a été stoppé en dernier ... donc il doit pouvoir repartir car il est réputé le plus à jour. Si aucun fichier ne comporte cette mention (cas de crash simultané) il faudra en éditer un "à la main" et mettre la valeur à 0. Dans le cas précédent le noeud "gale-4" démarre normalement, les autres peuvent alors démarrer et se connecter au cluster.
Si la situation est réellement "sérieuse" (refus complet de démarrage) mettre à jour le fichier "/var/lib/mysql/grastate.dat" de la machine stoppée en dernier et y forcer la valeur 0 dans la ligne "safe_to_bootstrap:", les autres membres du cluster pourront alors être démarrés avec un simple "systemctl start mariadb".
Utilisation du paramètre "wsrep_provider_options="gcache.recover=yes" ne change rien ... par contre en utilisant la commande "galera_new_cluster" sur le nœud 4 celui-ci démarre normalement et le démarrage des deux autres est alors possible ... Ouf! Le cluster se comporte ensuite normalement et il est possible de démarrer les autres systèmes avec "systemctl start mariadb".
La commande "galera_new_cluster" ne fonctionne directement que sur la dernière machine stoppée du cluster afin d'être sûr qu'aucune donnée ne sera perdue.
Souvenez-vous de cette commande ... qui peut servir en cas d'incident grave ou pour des machines de test que l'on stoppe souvent.
Sinon il faut aller s'intéresser au fichier "/var/lib/mysql/grastate.dat" et, éventuellement (si la dernière machine stoppée est hors-service) et y passer la valeur de "safe_to_bootstrap" de 0 à 1. Mais le risque sera de perdre les dernières données traitées avant l'arrêt de la dernière machine du cluster.
Le redémarrage d'un seul des membres de notre cluster se passe fort bien et chacun des autres nœuds note que ce membre a disparu :
2022-11-01 18:01:03 0 [Note] WSREP: cleaning up e713c304-9429 (tcp://192.168.2.155:4567)
192.168.2.155 est l'adresse du membre qui s'est absenté, lorsqu'il redémarre il se signale et les deux autres membres constatent ce fait avec un message :
2022-11-01 18:03:24 0 [Note] WSREP: Member 0.0 (gale-4) synced with group.
Une fonction qui peut être utile pour signaler ce type d'événement est disponible dans le paramétrage de Galera :
wsrep_notify_cmd = 'une commande shell'
Cette commande permet de signaler les événements importants.
J'en ai installé une très simple sur le nœud GALE_2 :
#!/bin/bash
FLOG=/var/tmp/MSG.LOG
DTT=$(date +%Y/%m/%d_%H:%M:%S)
echo ${DTT}' | '$* >>${FLOG}
Lors du démarrage des machines (dans l'ordre inverse de celui dans lequel elles ont été stoppées, (le dernier membre actif doit redémarrer le premier) on obtient l'affichage suivant :
23:52:04 | --status connected
23:52:04 | --status joiner
23:52:04 | --status initializing
23:52:05 | --status initialized
23:52:05 | --status joined
23:52:05 | --status joined --uuid 28736ddb-59f8-11ed-abde-fe2234c75fO
23:52:05 | --status synced
23:53:15 | --status synced --uuid 28736ddb-59f8-11ed-abde-fe2234c75fO
23:53:15 | --status donor
23:53:15 | --status joined
23:53:15 | --status synced
23:54:42 | --status synced --uuid 28736ddb-59f8-11ed-abde-fe2234c75fO
23:54:42 | --status donor
23:54:42 | --status joined
23:54:42 | --status syncedC'est très anormal que toutes les machines soient stoppées, mais cela peut arriver, tant qu'il reste une machine en fonction les autres peuvent venir s'abonner au cluster et tout se passe bien.
Le seul problème est que lors de la "panne" d'une machine son adresse IP ne réponds plus et les clients n'ont plus accès aux données et établir un système de haute disponibilité entre trois machines n'est pas une sinécure.
C'est là l'avantage d'utiliser Maxscale qui va, entre autres choses gérer l'accès à notre cluster. Maxscale permet de gérer des clusters disposant de plus de 3 nœuds, nous verrons cela dans un prochain chapitre ... à suivre
Maxscale : paramétrage
Maxscale : paramétrage jppCet article détaille, un peu, la mise en place de Maxscale.
Le paramétrage est relativement simple mais les dernières présentent un petit "piège" car l'adresse d'écoute par défaut est une adresse IPV6 et cela pourrait vous surprendre. Il est donc important de préciser "address=0.0.0.0" (ou une autre adresse IPV4) dans le paramétrage de Maxscale.
D'abord la définition des serveurs du cluster Galera :
# Server definitions
#
[gale-2]
type=server
address=192.168.2.153
port=3306
protocol=MariaDBBackend
#
[gale-3]
type=server
address=192.168.2.154
port=3306
protocol=MariaDBBackend
#
[gale-4]
type=server
address=192.168.2.155
port=3306
protocol=MariaDBBackendJ'ai ensuite décidé de créer deux "voies d'accès" :
- Une en lecture seule
- Une en lecture/écriture
[lect-seule]
type=service
router=readconnroute
servers=gale-4
user=util_services
password=xxxxxxxx
router_options=running
# ReadWriteSplit documentation:
# https://mariadb.com/kb/en/mariadb-maxscale-6-readwritesplit/
[ecri-lect]
type=service
router=readwritesplit
servers=gale-2,gale-3
user=util_services
password=xxxxxxxxUne fois ces deux services créés il faut leur affecter un "listener" qui permettra l'accès à nos services, nous aurons donc deux "listeners".
[Read-Only-Listener]
type=listener
service=lect-seule
protocol=MariaDBClient
port=3007
address=0.0.0.0
[Read-Write-Listener]
type=listener
service=ecri-lect
protocol=MariaDBClient
port=3006
address=0.0.0.0C'est ici qu'il faut préciser l'adresse au format IPV4 pour éviter le piège de l'IPV6 par défaut.
Enfin le dernier paragraphe pour fixer les paramètres du monitoring de nos 3 serveurs :
# This will keep MaxScale aware of the state of the servers.
# MariaDB Monitor documentation:
# https://mariadb.com/kb/en/maxscale-6-monitors/
#
[MariaDB-Monitor]
type=monitor
module=mariadbmon
servers=gale-2,gale-3,gale-4
user=xxxxxxx
password=yyyyyyyy
monitor_interval=2s
Ne pas oublier de "protéger" ce fichier par :
chown maxscale: /etc/maxscale.cnf
chmod 600 /etc/maxscale.cnf
Maxscale GUI
Maxscale GUI jppLe GUI de gestion de Maxscale.
Il est accessible sur le port 8989 de la machine selon les paramètres du fichier de configuration :
# MAXGUI
admin_host=192.168.2.152
# GUI without SSL
admin_secure_gui=falseIci j'ai inhibé le SSL ce qu'il ne faudrait pas faire en production ...
Le premier écran qui s'affiche est l'écran de surveillance (Dashboard) de notre cluster Galera première option a gauche dans le menu horizontal.

Cet écran présente l'état de notre cluster, on y voit l'état de notre cluster "Running" en vert dans la colonne "STATE" et la liste de tous les membres du cluster avec le nombre de connexions, leur état (autre colonne "STATE").
Le master a droit à la couleur verte et au statut "Master, Running", les deux autres à une mension rouge et Running, donc tout va bien. La dernière colonne indique à quel "service" chaque machine est attachée.
Un graphique, en haut de l'écran, montre la charge de chaque machine (nombre de sessions, connctions et le load).
Un menu horizontal permet d'afficher :
Les sessions courantes. Il est possible ici de "tuer" une session gênante.
Les services avec les machines concernées et les les sessions en cours.
Les listeners le nom du listener avec le port qu'ils utilisent, leur état (Running normalement !) et le nom du service.
Les filtres actifs. Les filtres permettent de réaliser des actions en fonction de l'utilisateur, par exemple de "cacher" certaines données confidentielles ....
En haut à droite de l'écran le bouton "Create New" permet de créer de nouveaux services, de nouveaux serveurs et des filtres.
Pour les filtres voir la documentation de Maxscale qui présente toutes les possibilités.
Depuis le menu principal les options suivantes :
- Visualisation : permet d'afficher notre cluster en mode graphique.

- Query-editor : permet d'exécuter des ordres SQL après s'être identifié auprès d'un service.
- Users : permet de gérer les utilisateurs de Maxscale (pas ceux du cluster).
- Logs archives : permet d'afficher le log de Maxscale.
- Settings : permet de modifier les paramètres de Maxgui, et il y en a un bon paquet ! N'y toucher que si l'on sait ce que l'on fait.
That's all folks.
Mysql/MariaDB : divers
Mysql/MariaDB : divers jppJ'ai regroupé ici plusieurs notes ou articles parfois très anciens, le premier date de 2009.
- Article Key-buffer de 2009: quelques conseils et remarques, certaines toujours applicables ... pour MyIsam.
- Article de 2013 sur le passage de Mysql 5.0 à 5.1.
- Article sur un problème de rechargement de dump après changement de version : "impossible to write to binary log"
- Article de 2016 sur le passage de 5.5 à 5.6.
- Encore un problème lors de changement de version. Mysql ne démarre pas correctement depuis
le script d'init standard.
Mysql : optimisation variable "key_buffer"
Mysql : optimisation variable "key_buffer" jppCette page de 2009 reste d'actualité (au moins pour les tables MyISAM) et les remarques et conseils peuvent s'appliquer à la variable "innodb_buffer_size" qui remplit à peu près la même fonction pour InnoDB.
Sur quelle information optimiser la valeur de ce paramètre ?
Ce paramètre est réservé aux tables "MyIsam", de plus en plus rares au profit des tables InnoDB.
KEY_BUFFER = taille réservée au buffer des index. Sa taille doit être assez importante, l'idéal est que tous les index résident en mémoire limitant ainsi les IO.
Vous pouvez calculer cette taille en évaluant la taille des index de votre base de données. L'utilisation de MySQL-Admin vous permet de suivre "en direct" l'évolution de l'utilisation de ce cache. Voir dans la section "Health", onglet "Memory Health" de MySQL-Admin. La partie "Key efficiency" vous permet de voir la partie du buffer effectivement utilisée ainsi que le "hitrate".
Le "hitrate" est le pourcentage de clés effectivement lues depuis le buffer.
Attention : Ne pas tenir compte des valeurs présentes peu après un redémarrage, il faut attendre plusieurs heures que le fonctionnement de la base se stabilise et que l'utilisation corresponde à l'utilisation moyenne normale des applications liées à cette base.
INNODB_BUFFER_POOL_SIZE = taille réservée au buffer Innodb (data + index)
Plus la valeur est élevée, meilleur est le fonctionnement de la base ... La mémoire étant bien moins rare qu'il y a quelques années on peut mettre ce qu'il faut.
Si on a assez de mémoire pour contenir la taille de la base ne pas hésiter, mais calculer au moins le volume des tables les plus accédées plus 20 ou 30%.
INNODB_BUFFER_POOL_INSTANCES = Nombre de "sous pools"
Une valeur de 1 par Gigaoctet de POOL_SIZE est à considérer comme correcte, mais mettre une valeur proche de celle du nombre de coeurs de processeur est une option à ne pas négliger.
- Des buffers trop petits --> hitrate bas et :
- temps de réponse allongé
- IO plus élevées
- Des buffers trop grands --> mémoire gachée.
Il n'est pas la peine de mobiliser 8 Gigaoctets de mémoire si seulement 50% sont utilisés, la mémoire économisée ici peut avec profit être utilisée ailleurs, c'est le cas de la plupart des paramètres de mémoire, trop petits cela ralentit, trop grands cela utilise inutilement de la mémoire.
Si votre base est "petite" par rapport à la mémoire mettez ce qu'il faut, sur une machine spécialisée "base de données" 75/80% de la mémoire est parfait pour InnoDB.
Toutefois si l'ensemble de vos tables ne "pèse" que 30 Go il est inutile de réserver 64 Go de mémoire !
TABLE_OPEN_CACHE = nombre de tables en cache.
Une cette valeur égale au nombre de tables si cela est possible. Note : on trouve un tas de choses à ce sujet ...
Une taille peu différente du nombre de tables de la base semble en général favorable.
Un autre point à surveiller est la mémoire affectée aux tris et autres zones temporaires (TMP_TABLE_SIZE et MAX_HEAP_TABLE_SIZE). Si certaines requêtes ramènent beaucoup de lignes à trier cela nécessite de la place et, là aussi, affecter un peu de mémoire n'est pas un luxe. En général 64 à 320Mo sont suffisants, surveiller le pourcentage de tables temporaires sur disque. La valeur de READ_IO_THREADS et WRITE_IO_THREADS peut être au minimum de 2, mais sur une machine multiprocesseurs aller presque jusqu'au nombre de coeurs est une bonne pratique ...
La taille des READ, SORT et JOIN BUFFER_SIZE est à suivre et des valeurs de 2 à 16M sont en général adaptées.
Mais il faut aussi penser à l'activité de création/modification de la base et affecter un minimum de mémoire au INNO_DB_LOG_BUFFER_SIZE afin de fluidifier les écritures sur le log.
A propos de accès disques, plus ils sont rapides, mieux c'est. L'utilisation de SSD permet d'atteindre des vitesses impressionnantes et la mise en RAID 1 permet d'augmenter encore ce type de performance avec toutefois un certain risque, le RAID 10 est parfait. Voir ici l'influence de la variable INNODB_IO_CAPACITY qui permet à la base d'optimiser son fonctionnement en fonction de la vitesse des I/O, en général de 100 à 1000 pour des disques standard et > 10000 pour des SSD.
Sur des systèmes largement multi-processeurs on peut aussi jouer sur les paramètres INNODB_READ_IO_THREADS et INNODB_WRITE_IO_THREADS et les augmenter à 2,3 ... afin d'accélérer au maximum les IO, base en lecture --> forcer le nombre de READ_IO_THREADS, si beaucoup d'écritures forcer le nombre de WRITE_IO_THREADS. Toutefois si vous n'avez pas de SSD ou de multiples disque de données cela peut être très peu efficace.
Pour l'ajustement de ces valeurs suivre l'évolution des compteurs et ratios fournis par un système de suivi de performance tel que Shinken + Graphite/InfluxDB ou d'autres produits non libres, Mysql Workbench fournit aussi l'accès à beaucoup d'informations utiles.
Erreur mise à jour MariaDB
Erreur mise à jour MariaDB jppErreur mise à jour MariaDB.
Mise à jour de 10.1.23-9+deb9u1 vers 10.1.26-0+deb9u1
Lors de cette mise à jour normale par apt-get upgrade l'installation s'est "plantée" avec la trace suivante :
regarding mariadb-server-10.1_10.1.26-0+deb9u1_amd64.deb containing mariadb-server-10.1, pre-dependency problem:
mariadb-server-10.1 pre-depends on mariadb-common (>= 10.1.26-0+deb9u1)
mariadb-common latest configured version is 10.1.23-9+deb9u1.
......
update-alternatives: error: alternative path /etc/mysql/mariadb.cnf doesn't exist
Une solution :
cd /etc/mysql
ln -s ./mariadb.conf.d/50-server.cnf ./mariadb.cnf
Quand on relance l'installation du paquet "fautif" on obtient :
dpkg -i mariadb-common_10.1.26-0+deb9u1_all.deb
(Reading database ... 192496 files and directories currently installed.)
Preparing to unpack mariadb-common_10.1.26-0+deb9u1_all.deb ...
Unpacking mariadb-common (10.1.26-0+deb9u1) over (10.1.26-0+deb9u1) ...
Setting up mariadb-common (10.1.26-0+deb9u1) ...
update-alternatives: warning: forcing reinstallation of alternative /etc/mysql/mariadb.cnf because link group my.cnf is broken
Le paquet s'est bien installé, voyons voir l'installation des paquets "client" :
dpkg -i mariadb-client*deb
(Reading database ... 192496 files and directories currently installed.)
Preparing to unpack mariadb-client-10.1_10.1.26-0+deb9u1_amd64.deb ...
Unpacking mariadb-client-10.1 (10.1.26-0+deb9u1) over (10.1.26-0+deb9u1) ...
Preparing to unpack mariadb-client-core-10.1_10.1.26-0+deb9u1_amd64.deb ...
Unpacking mariadb-client-core-10.1 (10.1.26-0+deb9u1) over (10.1.26-0+deb9u1) ...
Setting up mariadb-client-core-10.1 (10.1.26-0+deb9u1) ...
Setting up mariadb-client-10.1 (10.1.26-0+deb9u1) ...
Processing triggers for man-db (2.7.6.1-2) ...
Processing triggers for menu (2.1.47+b1) ...
C'est OK et les paquets "serveur" de MariaDB s'installent eux aussi correctement et une connexion à la base s'effectue normalement.
MariaDB : tables federated
MariaDB : tables federated jppLe plugin "Federatedx" responsable de la gestion des tables "federated" est livré en standard avec MariaDB mais n'est pas activé par défaut, le paramètre "federated", si présent dans les fichiers de configuration, provoque une erreur.
Pour quelques détails sur les tables "federated" voir ici.
L'import sans précaution d'une base comprenant des tables "federated" ne donne pas les résultats escomptés, les tables sont bien créées, mais avec le type "InnoDB" ce qui n'est pas le but recherché.
En effet l'objet "serveur" auquel sont rattachées les tables "federated" ne fait pas partie de l'export.
L'activation est très simple :
Dans une console "mysql" administrateur :
INSTALL SONAME 'ha_federatedx';
Ensuite jouter dans le fichier de config :
federated
On redémarre et c'est OK.
Remarque ;
Même en cas d'export/import la création du "serveur" doit être exécutée sur la nouvelle machine avant toute tentative de création d'une table "federated" sinon celle-ci sera créée en ="InnoDB".
Script mysql_slow_log_parser.pl
Script mysql_slow_log_parser.pl jppCe script de : Nathaniel Hendler permet d'analyser finement le fameux "mysql-slow.log".
Rappel :
L'enregistrement des requêtes lentes ou des requêtes sans index se paramètre dans le fichier "my.cnf" :
# Here you can see queries with especially long duration
log_slow_queries = /var/log/mysql/mysql-slow.log
long_query_time = 2
log-queries-not-using-indexes
Ici les lignes sont décommentées afin d'activer l'enregistrement.
Attention, assez consommateur de ressources,peu conseillé sur des machines de production qui ont déjà des problèmes de temps de réponse .....
Una analyse visuelle de ce fichier peut être intéressante mais devient rapidement rébarbative, heureusement "mysql_slow_log_parser.pl" est arrivé.
Ce petit script Perl effectue un regroupement des "queries" coûteux en fournissant pour chaque query identifié :
- le nombre d'occurences
- le temps total utilisé et le temps moyen
- le nombre de rangs analysés
- un "modèle" du query, dépourvu des variables
- un exemple de query avec les valeurs des variables
Ces résultats sont une mine d'or pour les développeurs car tous les ordres SQL critiques (criticables) apparaissent en clair avec même un exemple à soumettre à "EXPLAIN".
L'utilisation de ce module aide à repérer :
- les index manquants ou non judicieux
- les requêtes mal faites ...
Le comptage de chaque type de requête permet de se pencher d'abord sur les plus critiques (les plus nombreuses/coûteuses).
En bref un très bon outil que l'on peut trouver facilement sur Internet.
Mariadb 10.1.23 vers 10.1.26
Mariadb 10.1.23 vers 10.1.26 jppJ'ai rencontré un problème bizarre lors d'une mise à jour de MariaDB.
La mise à jour se passe mal et l'installation du paquet "mariadb-server-10.1_10.1.26-0+deb9u1_amd64.deb" échoue avec le message :
E: mariadb-server-10.1: subprocess installed post-installation script returned error exit status 2
En examinant les logs on trouve un message :
[ERROR] /usr/sbin/mysqld: unknown option '--federated'
[ERROR] Aborting
Si on commente dans le fichier "50-server.cnf" la ligne "federated" le démarrage se passe bien.
Il faut alors terminer la mise à jour "ratée" ...
On peut alors dé-commenter la ligne "federated" et relancer MariaDB.
Et cela fonctionne.
En effet le plugin "federated" a été déclaré obsolete et doit être remplacé par "ha_federatedx" ou il faut utiliser mariadb-connect ou FederatedX.
MariaDB : Renommer une partition
MariaDB : Renommer une partition jppLe partitionnement c'est parfois très commode et cela permet de débarrasser une base opérationnelle de données "anciennes" qui sont mieux placées dans des archives.
C'est ce qui a été fait chez un client où les données d'opération sont reportées dans des tables d'archives dès qu'elles sont jugées inutiles aux opérations courantes, elles restent ainsi disponibles pour des statistiques, des études commerciales et ...
Toutefois au bout de quelques mois elles sont utilisées de plus en plus rarement et leur présence n'est plus justifiée dans la base opérationnelle.
Le partitionnement par semaine/mois permet de se débarrasser facilement et rapidement de ces données par un simple "ALTER TABLE TRUNCATE PARTITION XXXXX" qui supprime l'intégralité du contenu en quelques instants au lieu d'heures à défiler des ordres "DELETE.
Or lors de la création d'une de ces tables d'archives une petite erreur de frappe s'est glissée, le nom des partitions comporte une référence directe au numéro de mois. Les partitions sont donc nommées de P01 à P12, un processus automatique supprime les partitions du mois N avec un ordre de troncature de la partition "PN", la faute de frappe concernait la partition "P11" malheureusement orthographiée "P21" ce qui aurait provoqué le plantage du processus d'archivage/purge lorsqu'il aurait voulu traiter la partitions P11 associée au mois 11.
Mais quel ordre SQL permet de faire cela ? Eh bien non il n'y a pas d'ordre dédié au renommage de partitions ... il faut utiliser la réorganisation de partitions avec l'ordre suivant :
|
ALTER TABLE TABLE_IDIOTE_ARCHIVES REORGANIZE PARTITION P21 INTO ( PARTITION P11 VALUES in (11) ); |
Et le tour est joué en ... quelques temps, car ici la partition contient plus de 50 millions de rangs et occupe environ 8Go, mais cela s'est bien exécuté en un temps raisonnable :
|
Query OK, 52893529 rows affected (9 min 27.36 sec) Records: 52893529 Duplicates: 0 Warnings: 0 |
Oui, c'est une belle base avec une activité certaine dont voici quelques chiffres tirés de la fin d'un "SHOW ENGINE INNODB STATUS" :
|
Number of rows inserted 7201350564, updated 16196473370, deleted 3242922826, read 14571828912181 528.20 inserts/s, 2777.79 updates/s, 205.45 deletes/s, 2109444.41 reads/s |
Mot de passe root perdu
Mot de passe root perdu jppVous avez perdu le mot de passe "root" de votre belle installation de MariaDB !
Note 2021 : Cela ne fonctionne plus avec les versions récentes de MariaDB car la table mysql.user n'est plus qu'une vue vers une structure plus complexe, il faut obligatoirement passer par un "init_file" pour re-créer un mot de passe "root". Ce fichier "init_file" peut être exécuté au démarrage de MariaDB, avant le démarrage complet, et permet d'exécuter des commandes en passant outre à la vérification des droits. A ne pas laisser entre toutes les mains ... et à bien supprimer du fichier de paramétrage après usage !
Pas de panique la procédure suivante vous sortira de l'embarras (à condition de stopper votre base quelques instants ce qui peut ne pas être évident pour une base de production ... mais pour celles la vous avez soigneusement sauvegardé les mots de passe dans un gestionnaire spécialisé).
- Stopper MariaDB
- En root lancer lé commande suivante :
mysqld_safe --skip-grant-tables --skip-networking &
Ici aucun accès ne sera possible aux commandes "classiques" "SET PASSWORD..." ou "ALTER USER ..." il faut mettre à jour directement la table "mysql.user" :
mysql -u root
UPDATE mysql.user SET authentication_string = PASSWORD('nouveau_mot_de_passe')
where user = 'root'
and host = 'localhost';
commit;
\q
Il suffira alors de stopper (gentiment) notre "mysqld_safe" avec la commande :
mysqladmin -u root shutdown
Puis de relancer MariaDB avec systemctl et se retrouver dans un état normal.
Ceci fonctionne parfaitement avec un MariaDB 10.3
Outils de gestion bases de données
Outils de gestion bases de données jppCe chapitre est destiné à présenter des outils destinés à la gestion bases de données.
Le premier de ceux-ci sera "Dbeaver" qui permet un accès graphique aux bases de données ... à peu près toutes les bases sont couvertes, même Clickhouse, mini présentation ide ce produit ci après.
Dbeaver
Dbeaver jppDbeaver : accéder aux bases de données.
Note 2024 : le développement est continu avec souvent de nouvelles versions.
Ce logiciel, construit sur Eclipse, est assez agréable à utiliser et donne accès à quasiment toutes les bases de données, je l'ai utilisé avec Mysql, Postgres, Sql Server, Sybase, Oracle ... ClickHouse et j'en passe.
Il existe en deux versions : gratuite et entreprise.
La version entreprise offre évidemment plus de possibilités mais je ne l'ai pas essayée et permet l'accès à des sources de données encore plus variées : Nosql, MongoDB, Couchbase, Influxdb, Cassandra, Redis ...
L'aspect général est assez agréable et à peu près identique pour les différentes saveurs de bases :
(image début).
Le paramétrage de l'accès aux bases est efficace :
(page_definir_connection)
L'accès au contenu des tables est aisé, l'éditeur SQL est efficace. Les zones affichées sont modifiables champ par champ dans une petite fenêtre annexe et on peut modifier n'importe quel champ, il suffit de ne pas oublier de cliquer "commit" pour enregistrer.
(lister_contenu_une_table)
Si vous oubliez le commit, l'action suivante déclenche l'apparition d'une boite de dialogue pour "commiter" ou annuler l'action.
En bref cet outil est assez commode et s'installe sans mystère sur n'importe quelle distribution. Il permet d'oublier "MysqlWorkbench" et surtout d'utiliser le même outil, avec le même type de réactions, pour différentes bases de données.
Je m'en sers notamment pour MariaDB/Mysql, SqlServer ou encore Postgres.
Les mises à jour sont fréquentes et toute anomalie signalée est rapidement corrigée avec un suivi par mail.
Les tarifs sont assez corrects pour la version Entreprise qui offre beaucoup plus de possibilités avec des souscriptions de 1 mois ($19) à 2 ans ($359).
En bref : un outil utile, simple et agréable à utiliser et qui fonctionne sans problème avec toutes les bases connues ... ce qui évite d'encombrer son disque dur d'un palanquée de logiciels différents.