Virtualisation
Virtualisation jppNote 2020 : ajout de LXC bien que cela ne soit pas strictement de la virtualisation mais plutôt de la conteneurisation, mais c'est une méthode concurrente.
Note 2017: ce groupe d'articles date un peu mais ils correspondent à une époque à laquelle la virtualisation n'était pas aussi commune qu'aujourd'hui. Je me sers toujours de Xen (4.14 et surtout de KVM) pour tous mes essais et tests, ce site est d'ailleurs hébergé dans une machine KVM.
Ce livre est destiné à regrouper des contributions sur XEN et KVM +++, leur paramétrages, usage et quelques trucs ...
Le premier article explique mon installation de XEN, presque la première ...
Une bonne présentation de XEN : https::/wiki.xenproject.org/xen_project_beginners_guide
Ou encore : https://www.xenproject.org/users/getting-started.html
Pour KVM : https://www.linux-kvm.org
Pour VirtualBOX : https://www.virtualbox.org/wiki/Documentation
Pour LXC : https://linuxcontainers.org/lxc/introduction
XEN ou KVM
XEN ou KVM jppXen ou Kvm faut-il choisir ?
Et bien non, on n'est pas obligé de choisir définitivement car il est tout à fait possible de faire exécuter la même image de disque (ou partition physique) avec l'un ou l'autre.
J'ai une machine dual boot (Debian sans Xen ou Debian avec Xen) et pour certains tests (tests avec Shinken à venir) j'ai pu sans aucun problème démarrer la MV dédiée à Shinken avec KVM.
La machine avait été créée avec Xen et j'ai constitué un petit script permettant de démarrer la machine sans Xen.
Voici le fichier de description de la machine Xen :
| name='com-shinken' memory=400 vcpus=1 uuid='613e5903-ae21-237f-1754-dde60e2896a5' on_crash='destroy' on_poweroff='destroy' on_reboot='restart' localtime=0 builder='hvm' extid=0 device_model="/usr/lib/xen/bin/qemu-dm" kernel='/usr/lib/xen/boot/hvmloader' boot='c' disk=[ 'phy:/dev/DUO/KVM_NEW_SYS,xvda,w' ] vif=['mac=00:16:3e:90:03:01,bridge=br0,model=rtl8139,type=netfront' ] usbdevice='tablet' keymap='fr' |
Puis le script de lancement de la même image sous Kvm :
| #!/bin/bash HDA=/dev/DUO/KVM_NEW_SYS NOM=kvm-shinken RAM=400M OPTION=' ' # clavier FR OPTION=' -k fr ' DEMON=' -daemonize ' SNAPSHOT=' -snapshot ' SNAPSHOT=' ' # Affectation interface réseau (appel àscript perso) ./qemu-ifup br0 tap1 RESEAU=' -net nic,macaddr=00:16:3e:90:03:01 -net tap,ifname=tap1,script=no, downscript=no ' kvm $DEMON $SNAPSHOT -hda $HDA -hdb $HDB -boot c -name $NOM -m $RAM $OPTION $RESEAU |
Et c'est tout, je peux faire tourner la machine "Shinken" à partir de n'importe lequel des deux disques de boot de ma machine principale, l'un démarre avec XEN, l'autre sans.
XEN
XEN jppNote 2016: ce groupe d'articles date un peu mais ils correspondent à une époque à laquelle la virtualisation n'était pas aussi commune qu'aujourd'hui. Je me sers toujours de Xen (4.6 maintenant et un peu de KVM aussi) pour tous mes essais et tests.
Ce livre est destiné à regrouper tous les articles sur XEN, son paramétrage, son usage, des trucs ...
Le premier article explique mon installation XEN, une des premières ... pensez, la virtualisation en 2009 !
Linux : serveur de machines virtuelles
Linux : serveur de machines virtuelles jppAyant eu besoin d'installer plusieurs systèmes différents pour des tests je me suis tourné vers la solution des machines virtuelles.
Etant un fervent partisan des logiciels libres j'ai choisi XEN voir la définition sur : fr.wikipedia.org/wiki/XEN
Le site officiel de Xen : www.xen.org
J'ai reçu, au cours d'un salon, un DVD Suse (SLES 11) permettant d'installer un tel serveur, j'ai donc decidé d'utiliser ce système pour ma dernière acquisition, us système AMD 64 bits dual core.
Je suis pourtant un fervent partisan de Debian, mais ayant eu à utiliser SUSE pour des installations professionnelles j'ai décidé de l'utiliser ici.
Le système est constitué ainsi :
- carte mère ASUS
- Processeur AMD Athlon(tm) 64 X2 Dual Core Processor 4400+
- 8Go de RAM (4 * 2Go)
- Disques : 2 * 250 Go de récupération + 2 * 1To tout neufs le tout en SATA2
J'ai décidé d'utiliser le RAID 1 logiciel sur tous les disques afin de sécuriser l'engin.
Les deux disques de 250 Go (sda et sdb) supportent donc :
- Une partition "swap" chacun (sda1 et sdb2)
- Une partition "boot" en ext2 chacun (sda2 et sdb2) (l'une est une copie de l'autre)
- Une partition "système" en ext3 montée en RAID1 (sda3 + sdb3) de 16Go (md1)
- Une partition comprenant le reste du disque utilisée en RAID1 (sda4 + sdb4) et gérée par LVM
Les deux disques de 1To ont été divisés en deux partitions
- une partition (sdc1 ett sdd1) de réserve de 8Go pour pouvoir y mettre un autre système
- une partition montée en RAID1 (sdc2 + sdd2) de 980Go gérée en LVM (md0)
Toutes ces opérations ont été faites lors de l'installation avec l'installeur standard de SUSE qui est très agréable à utiliser et permet toutes les fantaisies dans la création des partitions.
J'ai ensuite réalisé une installation standard de poste de travail en y ajoutant la gestion des machines virtuelles.
La version installée de XEN était la 3.3.1 que je ne connaissais pas encore (j'ai utilisé professionnellement la 3.0, la 3.1 et la 3.2). Des machines que j'avais créées en 3.1 ont été démarrées sans problème après :
- Définition d'un disque de stockage système (vive LVM) de 16Go
- Recopie de la sauvegarde de la machine roginale réalisée par "dd" du disque système et "gzip" du résultat pour pouvoir le transporter facilement.
- Paramétrage de mon serveur DHCP pour attribuer une adresse fixe à cette nouvelle machine grâce à la MAC Address.
- Mise en place du fichier paramètres d'origine de la MV
- Mise à jour de ce fichier (nom du disque et des interfaces réseau et MAC Address)
- Lancement de la machine ... ça boote.
- Accès réseau OK
La machine fonctionne parfaitement, elle peut accéder à internet, on peut se connecter normalement sur ce nouveau système.
Aujourd'hui j'ai une dizaine de machines virtuelles installées dont plusieurs peuvent fonctionner ensemble tant que je ne dépasse pas la mémoire disponible !
En effet chaque MV se voit attribuer un quota de mémoire et lorsqu'il ne reste plus de mémoire disponible XEN refuse sagement de lancer une nouvelle machine.
Les VM c'est le pied.
Dernières nouvelles : le système passe sur SSD
Paramètres définissant une machine virtuelle
Paramètres définissant une machine virtuelle jppLa déclaration d'une machine virtuelle se réduit à quelques paramètres permettant à XEN de créer l'environnement de cette machine. Il existe différentes manières d'écrire ces fichiers de configuration (y compris un mode XML), mais les éléments à paramétrer sont toujours les mêmes. En plus je préfère la syntaxe la plus simple en fichier texte "légèrement" structuré par l'usage des parenthèses carrées [ et ] pour les éléments multiples tels que disques ou interfaces réseau.
Le paramétrage concerne les éléments typiques de toute machine qu'elle soit physique ou virtuelle :
Nom de la machine (NAME) :
C'est le nom de la machine tel que vous l'utiliserez pour "discuter" avec l'hyperviseur, exemple :
- name='amdx2-deb65'
Ce nom doit bien entendu être unique ...
Identifiant (UUID):
Chaque MV doit disposer d'un identifiant différent des autres. L'identifiant est construit sous un format complexe afin d'éliminer les possibilités de doublon. Le programme "uuid" génère très bien ces identifiants.
Un exemple :
uuid='9e8c403f-bd93-75f7-1754-dde60e2803d9'
CPU (VCPUS):
Une nouvelle MV doit disposer d'au moins un CPU ! Mais elle peut en disposer d'autant que la machine physique servant de support peut lui en offrir.
Le seul paramètre direct est donc le nombre de VCPU (CU Virtuels) attribués à cette machine, par exemple :
- vcpus=1
Mémoire (MEMORY) :
C'est la quantité de mémoire attribuée à cette machine lors de son démarrage, la valeur est exprimée en MégaOctets, exemple :
- memory=1024
Comportement stop/start :
Ce groupe comporte trois paramètres viennent contrôler le comportement de la machine lors des arrêts et redémarrage, les valeurs indiquées sont des standards:
- on_crash='destroy'
- on_poweroff='destroy'
- on_reboot='restart'
Je ne change jamais ces valeurs qui conviennent parfaitement pour les cas "normaux".
Contrôle de l'horloge :
Ce paramètre contrôle le comportement de l'horloge, j'ai toujours vu la valeur "0".
- localtime=0
Mode d'émulation :
Ceci permet une émulation totale ou partielle. L'émulation partielle suppose des systèmes dont le noyau est prévu pour être "virtualisé" et est très coopérant, notamment au niveau des périphériques.
- builder='hvm'
Fournisseur des périphériques :
C'est le nom du module d'émulation qui sera utilisé pour présenter à la MV un "hardware" cohérent.
- device_model="/usr/lib/xen/bin/qemu-dm"
Bootloader chargé du lancement du système.
C'est le programme qui "lance" le système contenu sur le disque de la machine.
- kernel='/usr/lib/xen/boot/hvmloader'
Ici les paramètres sont destinés à une émulation totale (hardware virtual machine) pour utiliser un système virtualisé quelconque.
Mode de boot.
Selon la valeur (en direct de MSDOS) "c" provoque un boot depuis le "disque dur virtuel", la valeur "d" provoque un boot depuis le lecteur de CD virtuel.
- boot='c'
Après la création initiale d'une nouvelle machine (pour laquelle on a mis "d") depuis le CD, il fat remettre cette valeur à "c" avant de rebooter la machine.
Définition des disques dur virtuels.
on définit dans ce groupe "disk" le lien entre le périphérique physique et la manière dont il est présenté au nouveau
système.disk=[ 'phy:/dev/HUGE_1/MV4,hda,w' ]
Ici il s'agit dune partition "phy"sique qui sera présentée comme disque "hda" au système avec droit d'écriture ("w").
Une image ISO sera présentée comme :
- 'file:/STOCKAGE/ISOS/debian-500-amd64-DVD-1.iso,hdd:cdrom,r'
Le lecteur de CD physique de la machine support sera présenté (en lecture seule ("r"), comme c'est normal pour un CDROM) sous la forme :
- 'phy:/dev/hdb,hdc:cdrom,r'
Carte(s) réseau :
Plusieurs syntaxes existent (on peut même fournir l'adresse IP), je préfère celle-ci qui me permet d'utiliser mon mécanisme standard de DHCP.
On doit ici fournir adresse MAC, nom du "bridge" géré par le domaine 0, le modèle de périphérique à émuler. Il y a ici deux interfaces réseau :
Et puis quelques autres paramètres que je ne touche jamais et que je vous livre "en vrac" :
- vnc=1
- vncunused=1
- apic=0
- acpi=1
- pae=1
- serial='pty'
- keymap='fr'
Ces valeurs me conviennent et je ne me hasarde pas à les changer.
D'autres paramètres existent permettant de définir la priorité de la machine mais je préfère démarrer les machines avec la priorité standard et la modifier ensuite à l'aide des commandes "xm".
Exemple de définition d'une machine (Debian 5.0 bien que cela ne soit pas visible dans la définition) :
ostype='other'
name='amdx2-deb67'
memory=1024
vcpus=1
uuid='8e8c485f-a093-75a5-f753-afe71e2803e9'
on_crash='destroy'
on_poweroff='destroy'
on_reboot='restart'
localtime=0
builder='hvm'
extid=0
device_model="/usr/lib/xen/bin/qemu-dm"
kernel='/usr/lib/xen/boot/hvmloader'
boot='c'
disk=[ 'phy:/dev/SYSTEM/DEB67,hda,w',
# 'file:/STOCKAGE/ISOS/debian-503-amd64-netinst.iso,hdd:cdrom,r',
]
vif=['mac=00:16:3e:30:02:01,bridge=eth0,model=rtl8139,type=ioemu',
'mac=00:16:3e:40:02:02,bridge=eth1,model=rtl8139,type=ioemu',
]
vnc=1
vncunused=1
apic=0
acpi=1
pae=1
serial='pty'
keymap='fr'Ce petit article sans prétentions devrait démystifier la création de machines virtuelles.
XEN : mon réseau
XEN : mon réseau jppIl existe plusieurs manières de configurer le réseau dans un serveur XEN afin que les Machines Virtuelles (MV) disposent chacune d'un accès réseau.
Les différents modes sont :
- NAT
- Bridge
- Route
Le plus simple pour moi est le mode "Bridge" car chaque MV dispose de sa propre adresse IP et de tous les ports disponibles sans aucun paramétrage spécifique au niveau du domaine-0. Dans mon cas où toutes les machines sont des machines de test bien à l'abri derrière un pare-feu sur la machine "pont" de mon réseau cela ne me pose pas de problèmes de sécurité.
La situation pourrait être très différente sur des machines accessibles directement depuis Internet ou surtout dans le cas de machines de production où la sécurité est primordiale. Par ailleurs dans ce cas là les ports utilisés sont peu nombreux et la gestion du routage entre les machines n'est pas trop évolutive.
En effet je n'aimerais pas toucher à un script iptables compliqué sur des machines de production ..... au risque de bloquer l'accès à des ressources critiques.
J'ai donc choisi le mode "Bridge" qui répond à mes besoins.
Paramétrage du mode "Bridge".
- Au niveau du paramétrage de XEN.
Il s'agit de mettre en place les bons paramètres dans le fichier "xend-config.sxp".
- (network-script L-NT )
c'est le script utilisé par le démon xend au démarrage pour initialiser le(s) bridge(s) - (vif-script vif-bridge)
c'est le script utilisé par xend à la création de chaque interface de chaque MV
Comme je dispose de deux interfaces réseau j'utilise un petit script perso qui initialise les deux ponts d'un seul coup en appelant le script "standard" de Suse :
#!/bin/bash
# L-nt : Start XEN bridge
MKBRIDGE ()
{
"$dir/network-bridge" "$@" vifnum=1 bridge=eth1 netdev=eth1
sleep 1
"$dir/network-bridge" "$@" vifnum=0 bridge=eth0 netdev=eth0
brctl show
echo '.'
echo ' '
}
MKBRIDGE $1 $2 Les deux ponts sont activé et les MV peuvent se "brancher" et accéder aux réseaux.
Le script standard OpenSuse ne traite qu'un interface il faut donc passer par un script intermédiaire.
Par ailleurs le démarrage du script par le démon est effectué à un mauvais moment dans la séquence d'init et cela provoque des ennuis divers, je lance donc ce script complètement en fin de la séquence de boot ou "à la main" lorsque j'effectue des manips.
Dernières nouvelles :
Avec OpenSuse 11.2 le réseau est d'office installé en "pont" il ne reste rien à faire ... et cela marche sans problèmes.
Le "pont" est créé automatiquement lors de l'installation et est utilisé même dans les modes non "Xen".
Les performances réseau ne semblent pas en souffrir si ce n'est que la gestion du MTU fonctionne mal. Il est impossible de mettre un MTU à 4000 en automatique. Il est inutile de configure le MTU à 4000 avec les outils graphiques, cela n'a aucun effet. Même en remplissant les fichiers de configuration "à la main" avec la bonne valeur, on constate qu'après un reboot le MTU est retombé à 1500. J'aime bien avoir l'interface utilisant le iSCSI avec un MTU plus élevé.
Attention la version 11.2 n'est pas encore finalisée et peut présenter quelques inconvénients voir l'article sur le SSD
XEN : passage de 3.3.1 à 3.4.1
XEN : passage de 3.3.1 à 3.4.1 jppArès avoir utilisé du XEN 3.0 puis 3.2 j'ai upgradé mon installation en OpenSuse 11.1 ( http://www.opensuse.org ) et Xen 3.3.1, puis j'ai trouvé dans OpenSuse factory une version 3.4.1 que j'ai tout de suite voulu essayer ...
Comme j'ai du utiliser des "rpm" chargés un par un j'ai essuyé les problèmes de dépendances que j'ai résolu comme autrefois ... à la main.
On charge un RPM, on le teste et on cherche le RPM xxx de la version yyy qui est demandé, cela dure un petit moment mais on y arrive à l'aide de RPMFIND.NET qui est toujours le dernier recours pour les RPM récalcitrants.
Enfin j'y suis arrivé avec :
libeggdbus-1-0-0.5-1.12.x86_64.rpm
libpolkit0-0.94-2.3.x86_64.rpm
libpolkit-gtk-1-0-0.94-2.1.x86_64.rpm
libpolkit-qt0-0.9.2-3.1.x86_64.rpm
libreadline6-6.0-17.1.x86_64.rpm
libselinux1-2.0.80-4.6.x86_64.rpm
libuuid1-2.16-3.1.x86_64.rpm
libvirt-0.7.1-13.1.x86_64.rpm
libvirt-python-0.7.1-13.1.x86_64.rpm
parted-1.9.0-1.12.x86_64.rpm
polkit-0.94-2.3.x86_64.rpm
virt-manager-0.8.0-10.1.x86_64.rpm
xen-3.4.1_19718_04-23.1.x86_64.rpm
xen-doc-pdf-3.4.1_19718_04-23.1.x86_64.rpm
xen-libs-3.4.1_19718_04-23.1.x86_64.rpm
xen-tools-3.4.1_19718_04-23.1.x86_64.rpm
Et j'ai pu installer mon nouveau XEN 3.4.1 !
A première vue, rien d'extraordinaire, les machines se lancent et tournent plutôt bien. Le fonctionnement est stable avec 4 ou 5 MV en route, le fonctionnement global et la performance sont très corrects.
Seule ombre au tableau le gestionnaire graphique "virt-manager" a perdu un certain nombre de gadgets d'affichage, on disposait de l'usage CPU avec un graphe, de la taille mémoire, du combre de CPU attribués à chaque machine, c'est fini on ne peut plus tout avoir simultanément. Ce n'est pas très grave mais c'était bien de tout voir d'un coup d'oeil.
Les VM c'est le pied.
XEN : test 3.4.2
XEN : test 3.4.2 jppAprès l'utilisation des versions 3.2, 3.3, 3.4.1 j'ai décidé de tester la dernière mouture la 3.4.2.
Cette version est censée corriger quelques bugs présents dans la 3.4.1, bugs que je n'ai pas rencontrés personnellement.
Par ailleurs le support de la variation de la fréquence des CPU en fonction de la charge système est censé être "meilleur". Aucune fonctionnalité nouvelle n'est annoncée dans cette version que semble être uniquement une 3.4.1 stabilisée.
La version étant "toute neuve" j'ai téléchargé directement le paquet source : http://www.xen.org/products/xen_source.html
La compilation s'effectue sans problèmes après l'installation des dépendances nécessaires :
- GCC v3.4 or later, j'ai utilisé le 4.4.1
- GNU Make
- GNU Binutils
- Development install of zlib (e.g., zlib-dev)
- Development install of Python v2.3 or later (e.g., python-dev)
- Development install of curses (e.g., libncurses-dev)
- Development install of openssl (e.g., openssl-dev)
- Development install of x11 (e.g. xorg-x11-dev)
- bridge-utils package (/sbin/brctl)
- iproute package (/sbin/ip)
- hotplug or udev
L'installation s'effectue très simplement par recopie du binaire "gzifié" ( xen-3.4.2/dist/install/boot/xen-3.4.2.gz) dans le répertoire /boot et par paramétrage de grub.
Aucune dépendance spécifique par rapport aux outils (QEMU, libvirt ...) n'étant indiquée je me suis lancé directement dans l'exécution.
Les différentes machines que j'ai testées se sont lancées sans erreurs et ont fonctionné tout à fait normalement :
- Windows XP (32 bits)
- Windows 2000 (32 bits)
- Windows 2003 (32 bits)
- Linux Debian en 32 et 64 bits
- Linux Suse 10/SP2
Je continue les tests pour donner un peu plus d'impressions sur cette version.
Comme la version OpenSuse 11.2 vient de sortir en beta je vais reformater le système, mettre la partie système sur SSD et installer OpenSuse 11.2.
Voir l'article : sur le SSD
XEN : installation 3.4.2 sur Debian "instable"
XEN : installation 3.4.2 sur Debian "instable" jppDepuis que je dispose d'une belle machine tout neuve j'ai eu l'envie de tester XEN. Mon installation Deian étant fondée sur la distribution "unstable" je suis donc resté dans la ligne en essayant d'installer la dernière version de XEN la 3.4.2.
L'installation se fait à grands coups de "apt-get" ou "aptitude" selon les goûts de chacun. Les paquets à installer sont :
- xen-hypervisor-3.4-amd64 3.4.2-2
- xenstore-utils 3.4.2-2
- xen-tools 4.1.1
- xen-utils-3.4 3.4.2-2
- xen-utils-common 3.4.2-2
auxquels il faut ajouter
- xen-utils-unstable 3.3 ?
Le volume à télécharger est assez faible # 15Mo.
L'installation se passe sans problèmes; merci aptitude.
Il faut ensuite se mettre à la recherche d'un noyau "xénifié" pour gérer le domaine 0.
La seule image Debian que j'ai trouvée en X86_64 est le 2.6.26-2-xen-amd64 dans la branche "stable" avec son inséparable paquet de modules.
Ce noyau convient en principe pour le domaine 0 et pour les domaines Utilisateurs.
Après moult essais ce noyau ne fonctionne pas sur mon matériel et se bloque presque au début avant les accès aux disques.
Le passage par la case compilation est obligatoire. En principe les dernières versions de noyau sont aptes à gérer le domaine 0 à condition de définir le bon paramétrage.
Après une petite recherche j'ai trouvé un noyau 2.6.31 modifié pour supporter le domaine 0 sur http://x17.eu/xen/
où plusieurs noyaux sont disponibles, j'ai choisi le suivant :
linux-2.6.31.4-xen-r4.aka.suse-xenified-2.6.31.3-1.1.src.rpm-rebased.patches.by.andrew.lyon.tar.gz
qui me plaisait bien car très récent et réalisé par un gourou connu.
Le fichier ".config" que j'ai utilisé est en téléchargement en bas de cette page, il suffira de le renommer en ".config".
Il faut ensuite ajouter le lancement de XEN et du noyau fraîchement compilé dans le fichier grub.cfg aucune opération ne le fait automatiquement.
Il y a une petite bizarrerie dans la configuration : il faut mettre deux fois (???) certains paramètres ce qui ne semble pas évident et peut dépendre de la version de GRUB utilisée (1.97 pour moi). Pour simplifier je donne ci dessous la partie adéquate du "grub.cfg" :
menuentry "Debian XEN GNU/Linux" {
insmod ext2
set root=(hd0,1)
search --no-floppy --fs-uuid --set 116c3b30-4586-4f25-b7c1-c0d5c5a5b003
multiboot /xen.gz /xen.gz noreboot dom0_mem=1536M
module /vmlinuz-xen /vmlinuz-xen root=/dev/md0 ro noquiet
module /initrd-xen
}
Avec tout cela le système se lance et XEN es activé mais lorsque je tente la création d'une machine virtuelle il y a un problème :
Error: HVM guest support is unavailable: is VT/AMD-V supported by your CPU and enabled in your BIOS?
Simple oubli ... il suffit de rebooter en passant par le BIOS pour activer cette option.
Cette fois-ci on va pouvoir y aller :
- créer une Machine virtuelle avec un fichier de config "emprunté" et une image disque récupérée.
- xm new k2000-....
Unexpected error: <type 'exceptions.ImportError'>
Please report to xen-devel@lists.xensource.com
Traceback (most recent call last):
File "/usr/lib/xen-3.4/bin/xm", line 8, in <module>
main.main(sys.argv)
File "/usr/lib/xen-3.4/lib/python/xen/xm/main.py", line 2997, in main
_, rc = _run_cmd(cmd, cmd_name, args)
File "/usr/lib/xen-3.4/lib/python/xen/xm/main.py", line 3021, in _run_cmd
return True, cmd(args)
File "<string>", line 1, in <lambda>
File "/usr/lib/xen-3.4/lib/python/xen/xm/main.py", line 1366, in xm_importcommand
cmd = __import__(command, globals(), locals(), 'xen.xm')
File "/usr/lib/xen-3.4/lib/python/xen/xm/new.py", line 26, in <module>
from xen.xm.xenapi_create import *
File "/usr/lib/xen-3.4/lib/python/xen/xm/xenapi_create.py", line 23, in <module>
from xml.parsers.xmlproc import xmlproc, xmlval, xmldtd
ImportError: No module named xmlproc
xm create --> erreur : from xml.parsers.xmlproc import xmlproc, xmlval, xmldtd
Les dépendances de Debian sont pourtant en général bonnes ... on cherche un paquet "python-xml" ... qui existe bel et bien au milieu d'un très grand nombre de paquets python. Tiens il faudra que je me mette sérieusement à Python.
aptitude install python-xml
Et cela repart :
xm new k2000-xp1
Using config file "./k2000-xp1".
Ouuuiiii, cette fois-ci c'est bon, la MV est créée, on va pouvoir jouer. Je lance le NS5200 (j'y ai stocké l'image disque que l'on m'a prêtée) et ...
Je crée une nouvelle machine avec un fichier param récupéré avec l'image et légèrement modifié pour l'adapter (réseau et image disque) :
xm new mach_test
C'est OK !Il y a encore un petit problème la machine virtuelle ne se lance pas, la consultation du fichier de lancement (/var/log/xen/qemu-dm.....) montre que "qemu-dm" reçoit un paramètre qu'il n'est pas capable d'interpréter. Le paramètre concerné est "-videoram 16", ja construit vite fait un petit script shell "qemu-dm" qui "filtre" les paramètres, élimine le paramètre "videoram" et appelle le programme original renommé en "qemu-dm.real":
#!/bin/bash
OPTS=` echo $* | sed 's/-videoram .//' `
/usr/lib/xen-unstable/bin/qemu-dm.real $OPTS
Par ailleurs je constate que les fchiers de XEN sont un peu "en pagaille" dans les répertoires :
- xen
- xen-3.4
- xen-common
- xen-default
- xen-tools
- xen-unstable
Un peu de rangement ne ferait pas de mal et certains modules sont présents (et différents) dans plusieurs répertoires. Je renomme certains répertoires de "xen-unstable" pour donner la priorité aux modules de "xen-3.4").
Je lance le gestionnaire "virt-manager" mais la machine nouvellement créée n'apparait pas dans la liste ... tan pis je la lance à la main :
xm start mach_test
La machine apparaît dans virt_manager, j'ouvre l'écran et tout semble se dérouler correctement jusqu'au passage en mode graphique où l'écran est parfaitement illisible.
Je lance une connexion SSH vers la machine, c'est OK, la machine tourne normalement. Il me suffit de lancer le serveur VNC pour pouvoir me connecter en mode graphique.
C'est vraiment dommage que virt-manager ne donne pas accès directement au mode graphique, probablement un problème lié à "videoram".
Je tente de lancer une image Windows XP, le démarrage est OK, l'affichage est bon dans la phase de démarrage mais dès que l'écran de login doit s'afficher l'écran se brouille. La machine est parfaitement accessible et fonctionnelle en utilisant le mode Terminal Server avec "rdesktop".
Le fonctionnement est parfaitement souple, la souris réponds plutôt mieux qu'avec les versions antérieures de XEN.
"Virt-manager" ne montre pas les machines qui ne sont pas lancées et je ne trouve aucun paramétrage à ce sujet dans les préférences, il est donc impossible de lancer les machins depuis l'interface graphique puisqu'elles n'y deviennent visibles qu'après leur lancement.
Il me faut me mettre à la recherche d'une version convenable de "qemu-dm" et attendre la prochaine version de "virt-manager".
Dans un prochain article on va tester les possibilités de sauvegarde et de restauration de machines et peut-être même la migration de machines d'un serveur à un autre.
Mais en conclusion l'installation de XEN depuis la version Debian "instable" nécessite un travail assez important avant d'arriver à quelque-chose d'utilisable. Il me faut chercher un "qemu-dm" un peu plus récent (?) qui admette le paramètre videoram pour, peut-être, pouvoir profiter des écrans graphiques "en direct" depuis la console. Quand à "virt_manager" il n'affiche pas les machines inactives et les statistiques IO et réseau bien que présentes dans le paramétrage n'affichent pas de valeurs lorsqu'elles sont activées.
D'autres fonctions ne marchent pas par exemple un "xm save" suivi d'un "xm restore" déclenche une erreur irrécupérable. Si le restore ne fonctionne pas il en sera de même de la fonction "xm migrate".
Devant ces ennuis je vais tester la version complète fourni par Xensource mais cela sera un autre article.
Voir l'autre article
J'ai appris depuis que les mainteneurs de Xen pour Debian ont limité leurs activités à autoriser Debian comme domaine hébergé et abandonné la possibilité d'utiliser Debian en "Domaine-0" car cela nécessite la maintenance du paquet "qemu-dm" qui semble a priori fort délicate.
L'intégration dand le noyau officiel de la gestion d'un "Domaine-0" est en cours mais devrait durer encore assez longtemps car les modifications sont assez "intrusives" peut-être pour le noyau 2.6.40 ?
XEN : installation 3.4 "unstable" de Xensource
XEN : installation 3.4 "unstable" de Xensource jppAprès une tentative avortée et afin de tester l'installation de la dernière version de XEN sur ma belle machine ( voir l'article ) je me dirige vers une génération complète à partir des sources de Xensource.
- pour récupérer les sources il faut installer "Mercurial" ( apt-get install mercurial ).
- installer quelques dépendances nécessaires :
apt-get install bcc gettext python-dev libsdl1.2-dev libgpmg1-dev
Il y a peut-être d'autres dépendances mais elles devaient déjà être installées sur mon système ... - Se mettre dans un répertoire tranquille et lancer la récupération des sources par :
hg clone http://xenbits.xensource.com/xen-3.4-testing.hg - On peut ensuite lancer la compilation par les classiques
make world
make install
Remarque un noyau Linux 2.6.18 est chargé et compilé (il vous faudra fournir le paramétrage de ce noyau) dans la foulée, ayant un noyau beaucoup plus récent j'ignorerai celui là.
Le processus est très long car il y beaucoup de sources à compiler, l'installation par contre est très rapide.
Si vous voulez utiliser le noyau 2.6.18 il faudra générer un "initrd" ( "update-initramfs -c -v -k 2.6.18" pour Debian et dérivés).
Je note au passage que la version de XEN est la 3.4.3.
Le paramétrage de Grub est identique à celui du précédent essai :
| menuentry "Debian GNU/Linux, with Linux xen" { insmod ext2 set root=(hd0,1) search --no-floppy --fs-uuid --set 116c3b30-4586-4f25-b7c1-c0d5c5a5b003 multiboot /xen.gz /xen.gz noreboot dom0_mem=1536M module /vmlinuz-xen /vmlinuz-xen root=/dev/md0 ro noquiet module /initrd-xen /initrd-xen } |
Bien noter le "doublement" des informations sur les noms des fichiers ( /xen.gz, /vmlinuz-xen et /initrd.xen ) !
Si vous avez un "Grub" plus ancien, par exemple celui de la OpenSuse 11.2 le schéma est plus simple (plus intuitif surtout !) :
| title Xen -- openSUSE 11.2 - 2.6.31.5-0.1-xpatch XEN 3.4.2 root (hd0,0) kernel /boot/xen-3.4.2.gz dom0_mem=2048M module /boot/vmlinuz-2.6.31.5-0.1-xpatch root=/dev/disk/by-label/ROOT splash=silent noresume showopts vga=0x345 module /boot/initrd-2.6.31.5-0.1-xpatch |
On reboote dans l'angoisse pour vérifier et ... celà marche du premier coup.
Je tente fébrilement de démarrer une VM, c'est parfait. L'écran du système est parfait dans la fenêtre de "virt-manager" (celui fourni par Debian).
Je tente me connecter sur 1 VM et lance des applications ensuite un :
xm save VM fichier
qui se termine assez rapidement avec un arrêt normal de la machine virtuelle après la mise en pause. Vite une tentative de restauration :
xm restore fichier
qui après quelques dizaines de secondes ré-ouvre l'écran pile sur les applications ouvertes précédemment. La fonction save/restore est donc parfaite.
Pour les prochains tests il me faudra accéder à une autre machine tournant avec un XEN relativement récent, un petit prêt/transfert de machine est à l'étude pour pouvoir réaliser ces tests.
Xen : noyaux Suse
Xen : noyaux Suse jppSuse est toujours à la pointe du progrès (OpenSuse) pour les noyaux "xenifiés", on peut ainsi tester les dernières versions des noyaux et bénéficier de toutes les améliorations.
J'ai ainsi testé les noyaux 2.6.33.6 et 2.6.34-rc4-4 en version "xenifiée" avec le "xen" 3.4 de OpenSuse (version 1_19718_04-2.1).
Ces deux noyaux sont parfaitement stables et toutes les machines virtuelles se lancent et fonctionnent sans problèmes. La stabilité de X est également bonne (je n'ai pas eu de plantages inexpliqués sous X, mais quelques ralentissements bizarres, avec Xorg à 100% de CPU, lors de défilement dans Firefox ou de changement d'écran), ce qui permet quand même l'accès direct par "virt-manager" aux écrans graphiques des machines virtuelles.
Petite différence :
le répertoire "/proc/xen" ne semble plus aussi important mais contient toujours les fichiers habituels, mais le répertoire "/sys/hypervisor" est bien plus fourni, c'est probablement l'avenir.
Il va falloir maintenant passer à XEN 4 pour être tout à fait "dans la course".
Rappel :
- Machine avec Processeur "AMD Athlon(tm) 64 X2 Dual Core Processor 4400"
- RAM : 8Go Disques : système sur
- SSD OCZ Agility 32Go (pas encore "trimmé", mais qui a gardé sa vitesse)
- 2 * 1To en RAID 1 2 * 160Go en RAID 1
Où récupérer ces trucs : sur le repository OpenSuse (OpenSuse 11.3 beta),.
Attention ce ne sont pas des versions "stables".
Je viens d'y voir un 2.6.34.6 (fini le -rc) à tester très prochainement et une version de Xen 4.0 toute fraîche d'aujourd'hui 7 mai 2010.
Je vais probablement finir par passer en 4.0, je n'ai pas tenu longtemps ...
XEN : migration de machines en live
XEN : migration de machines en live jppAvec l'installation de la dernière version de Xen, sur une nouvelle machine, l'envie m'est venue de tester la migration d'une Machine Virtuelle d'un serveur à l'autre.
Pour réaliser cette opération il faut :
- Deux serveurs de MV !
- Des installations de XEN "compatibles" (avec les mêmes chemins d'accès aux différentes fonctionnalités de XEN)
- Un espace de stockage partagé
note : le chemin d'accès aux "disques virtuels" doit être identique sur les deux systèmes, si le disque de la machine est accédé par "/REP/XEN.img" ce chemin doit être identique pour les deux serveurs. - Assez de mémoire libre sur le deuxième système pour "accueillir" une machine virtuelle supplémentaire.
- Une liaison réseau pour le tout, si elle est rapide (1 Gb) celà n'est que mieux
- Que les fonctions " xm save " et " xm restore " fonctionnent correctement sur chacune des deux machines.
- Que les processeurs soient compatibles, ici pas de problème tout est en AMD 64 bits.
- Pour les deux serveurs de MV un "simple" emprunt me permet de remplir ce pré-requis.
- Pour les installations compatibles cela semble OK car l'implantation de la machine "prêtée" (OpenSuse 11.2) est strictement standard, l'autre machine, installée avec les sources de Xensource est au standard.
- L'espace de stockage partagé est fourni par le NS5200 sur un "folder" ouvert en NFS, les deux machines ont été autorisées sur la boîte miracle.
- La liaison réseau est fournie par un petit hub 1 Gigabit D-LINK à 8 ports modèle DGS-1008d.
- Les fonctions " xm save" et " xm restore " ont été testées séparément sur les deux machines et marchent à merveille.
Il faut configurer les deux XEN pour permettre la migration, il faut pour cela modifier le fichier de configuration "/etc/xen/xend-config.sxp" :
- (xend-relocation-server yes)
- (xend-relocation-hosts-allow '192.168.2.20') ou (xend-relocation-hosts-allow '') pour des tests.
- (xend-relocation-port 8002)
Une fois la belle machine prêtée branchée, configurée et connectée au réseau (petite mise à jour de l'adresse de la carte nécessaire) les tests peuvent commencer.
Il faut d'abord assurer l'accès au NS5200 en NFS à la nouvelle machine, les structures de stockages devant être identiques il suffit de créer un nouveau point de montage à le racine du nouveau serveur.
Pour la commodité le serveur ancien (AMD dualcore) sera appelé serveur B, l'autre (AMD quadcore) sera appelé serveur A.
Un petit script permettra de ne pas retaper plusieurs fois la même commande d'accès au serveur NFS.
#!/bin/bash
NS5200='192.168.3.101'
mount -t nfs $NS5200:/raid0/data/Sauvegardes /THECUS_NFS -o rw
Une machine de test est lancée sur le serveur A, l'exemple utilisé est une machine WIndows XP dont le fichier de configuration est présenté en fichier attaché.
La machine est accédée par le logiciel " rdesktop ".
La suite des opérations est très simple :
- Connecter le montage NFS sur les deux machines
- Lancer la machine virtuelle XP sur le serveur A
- Se connecter à la machine XP à l'aide de "rdesktop"
- Ouvrir une application (OpenOffice) dans la machine XP
- Lancer la migration de serveur A vers serveur B
- Vérifier dans l'écran "rdesktop" que l'application est bien fonctionnelle sur la MV
Le script de connexion NFS est lancé sur les deux serveurs
Lancer la machine sur le serveur A : xm start com-xp1
Lancer la connexion à la MV : rdesktop -B -P -x -l -g 1024x768 com-xp1
Lancer OpenOffice et ouvrir un document.
Cà marche !
<Image 1 > : la MV est bien active sur le serveur A et invisible sur le serveur B. 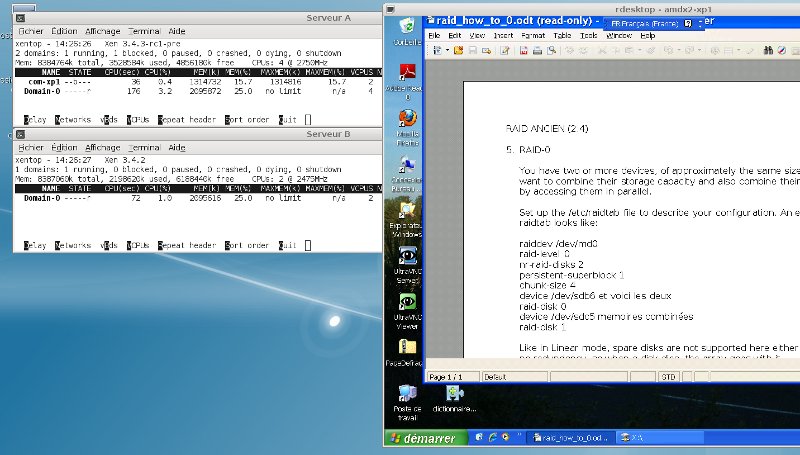
Lancer la migration : xm migrate com-xp1 192.168.3.10
La machine apparaît sur le " xm top " du serveur A et passe en " migrating " sur le " xm top " de serveur B, après environ 20 secondes la machine disparait du serveur A et après une quinzaine de secondes supplémentaires la machine XP est de nouveau parfaitement exploitable dans l'écran rdesktop.
La vitesse de transfert de la mémoire (par le réseau) est d'environ 80 MO/s ce qui explique assez bien le temps de migration pour une taille mémoire de 1536 Mo.
<image 2> La machine est bien affectée au serveur B. 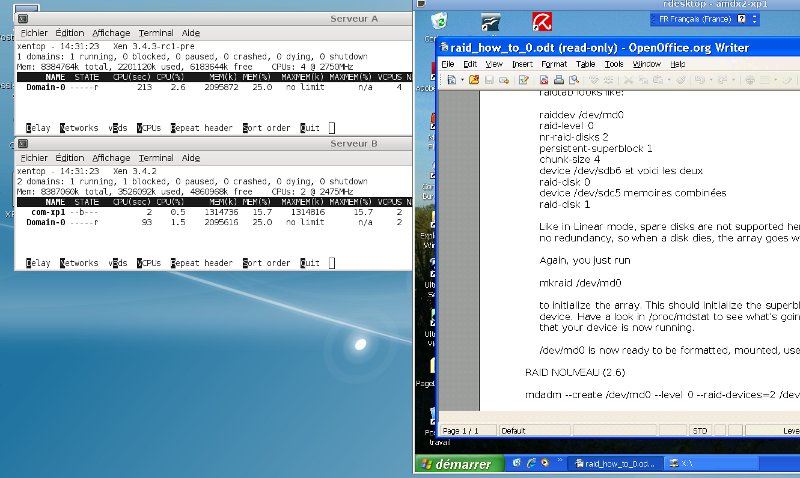
C'est quasiment magique !
Je vais regretter de perdre le deuxième serveur, mais arrêtons de rêver !
XEN : 4.0 sur Debian
XEN : 4.0 sur Debian jppCet article est destiné à présenter "mon" passage à XEN 4.0 depuis la compilation des sources.
J'ai déjà compilé XEN 3.4.3 et quelques noyaux, la plupart des utilitaires et autres "includes" nécessaires sont donc déjà présents dans ma machine.
Il faut, au moins disposer de :
- libssl-dev
- zlib-dev
- bin86
- bcc
- elks-libc
- python2.6-dev
- python-xml pour xml_proc
Après la récupération des sources depuis le site xensource et installation dans un répertoire propre il faut lancer la compilation, comme je dispose de noyaux Linux récents je ne compile pas le noyau standard de XEN.
Il suffit donc de lancer les commandes
make xen 2>&1 | tee XEN.LOG
make tools 2>&1 | tee TOOLS.LOG
pour compiler le tout et garder trace de l'événement.
La commande "make tools" déclenche automatiquement le chargement des sources de la version correspondante "xenifiée" de QEMU.
La vérification avant compilation des "tools" montre :
Checking check_crypto_lib: OK
Checking check_curl: unused, OK
Checking check_openssl_devel: OK
Checking check_python: OK
Checking check_python_devel: OK
Checking check_uuid_devel: OK
Checking check_x11_devel: OK
Checking check_xgettext: OK
Checking check_xml2: unused, OK
Checking check_zlib_devel: OK
Checking check_zlib_lib: OK
Cela donne une bonne indication des paquets de développement nécessaires.
make xen se passe bien, la première tentative d'installation achoppe sur l'absence d'un répertoire "check" dans l'arborescence "dist" :
./install.sh
Installing Xen from './dist/install' to '/'...
- installing for udev-based system
- modifying permissions
All done.
Checking to see whether prerequisite tools are installed...
cd: 53: can't cd to ./dist/install/../check
./install.sh: 54: ./chk: not found
All done.
Je récupère le répertoire "check" dans la verson 3.4.3 et la recopie "bêtement" ... et cela a l'air de fonctionner :
./install.sh
Installing Xen from './dist/install' to '/'...
- installing for udev-based system
- modifying permissions
All done.
Checking to see whether prerequisite tools are installed...
Xen CHECK-INSTALL lundi 26 avril 2010, 20:02:06 (UTC+0200)
Checking check_brctl: OK
Checking check_crypto_lib: OK
Checking check_curl: unused, OK
Checking check_iproute: OK
Checking check_python: OK
Checking check_python_xml: OK
Checking check_udev: /sbin/udevadm OK
Checking check_xml2: unused, OK
Checking check_zlib_lib: OK
All done.
Les nouveautés dans le répertoire "/boot" :
-rw-r--r-- 1 root root 669914 26 avril 22:50 xen-4.0.0.gz
lrwxrwxrwx 1 root root 12 26 avril 23:37 xen-4.0.gz -> xen-4.0.0.gz
lrwxrwxrwx 1 root root 12 26 avril 23:37 xen-4.gz -> xen-4.0.0.gz
On va bien vite voir si cela "boote" ! Eh non, un problème, il faut charger le package "python-profiler" pour que "xend" et compagnie se lancent normalement. Une fois ce paquet installé le boot est OK, et on peut lancer une machine virtuelle sans modifier son paramétrage.
Par contre mon "ancienne" installation (version 3.4.3) n'est plus utilisable pour diverses incompatibilités au niveau des scripts "python", le passage est donc un passage sans retour (à moins d'avoir réalisé une image de son disque système avant !).
J'ai ensuite refait les tests de migration "live" vers une machine tournant en XEN 3.4.3, la migration échoue. Un autre test :
"xm save machine fichier_sur_disque_partagé"
suivi (sur l'autre machine) d'un "xm restore fichier_sur_disque_partagé"
échoue. La compatibilité n'est donc pas évidente entre les versions 3.4 et 4, comme ce sont des versions "majeures" on ne s'en étonnera que peu.
XEN : 4.0 OpenSuse
XEN : 4.0 OpenSuse jppPas mal de paquets à charger avant de lancer le petit script ci-dessous :
#!/bin/bash
#
# Pour XEN
LISTE=" glibc-2.11.1-5.2.x86_64.rpm \
glibc-locale-2.11.1-5.2.x86_64.rpm \
libopenssl1_0_0-1.0.0-2.5.x86_64.rpm \
openssl-1.0.0-2.5.x86_64.rpm \
python-base-2.6.5-1.8.x86_64.rpm \
python-2.6.5-1.5.x86_64.rpm \
xen-4.0.0_21091_01-2.4.x86_64.rpm \
xen-libs-4.0.0_21091_01-2.4.x86_64.rpm \
xen-tools-4.0.0_21091_01-2.4.x86_64.rpm"
# Pour virt-manager
LISTEV="libxml2-2.7.7-3.2.x86_64.rpm \
libblkid1-2.17.2-1.6.x86_64.rpm \
parted-2.2-1.9.x86_64.rpm \
libvirt-python-0.8.0-1.8.x86_64.rpm \
libvirt-client-0.8.0-1.8.x86_64.rpm \
virt-utils-1.1.1-3.13.x86_64.rpm \
libvirt-0.8.0-1.8.x86_64.rpm \
virt-manager-0.8.4-2.3.x86_64.rpm "
rpm -hiv --replacefiles $LISTE
rpm -hiv --replacefiles $LISTEV
A bientôt pour les tests, à première vue tout baigne, la première machine virtuelle s'est bien lancée et tourne sans aucun problème.
Xen : Centos netinstall
Xen : Centos netinstall jppInstallation d'une machine Centos 5 avec le CD "Netinstall".
Sous XEN ou KVM c'est identique, sur une machine physique celà marche aussi !
Cette installation est tentée car j'ai vu que ce CD était très peu volumineux (environ 9Mo), ce qui semble très tentant et permet d'avoir une machine "à jour" dès l'installation, et si l'on peut mettre cela sur une vieille clé USB ...
L'image de démarrage est bien jolie
 |
et vous emmène directement sur le premier écran texte. |
Premier écran "Choose a language" : je préfère le français ...
Deuxième écran "Quel type de clavier" : déjà en français ... j'aime bien les claviers "fr-latin9" ce qui ne pose pas de problèmes.
Troisième écran "Méthode d'installation"
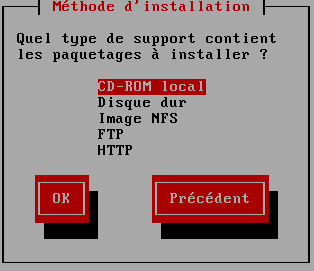 |
je vais tenter le HTTP ... |
Quatrième écran "Configuration TCP/IP"
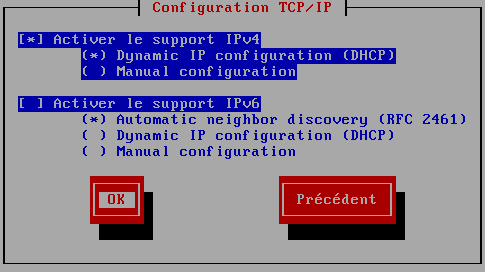 |
avec le choix IPV4 et/ou IPV6, l'un comme l'autre en IP fixe ou en dhcp. Comme j'ai préparé mon coup je sélectionne IPV4 et DHCP |
L'écran suivant permet de sélectionner le site de téléchargement
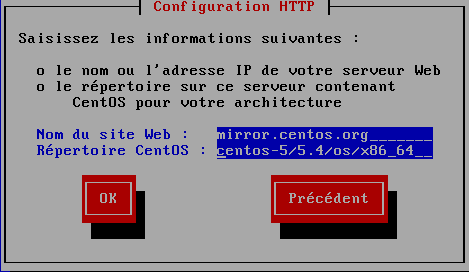 |
Le site HTTP est : "http://mirror.centos.org" le répertoire est : "centos-5/5.4/os/x86_64" A saisir sans le "http://" et sans "/" en tête de nom de répertoire. On peut aussi utiliser un miroir français en général plus rapide : mirrors.ircam.fr pub/CentOS/5.5/os/x86_64 (64 bits) ou pub/CentOS/5.5/os/i386 (32 bits) |
Après quelques instants la "Récupération" commence et après environ 3 minutes un écran graphique commence à s'ouvrir et au bout d'environ 40 secondes supplémentaires l'écran suivant s'affiche : 
Mon disque "hda" n'étant pas initialisé, l'initialisation m'est proposée gentiment et je l'accepte puisque je crains pas de perdre les données contenues !
Très vite les trois disques que j'ai préparés sont repérés et présentés.
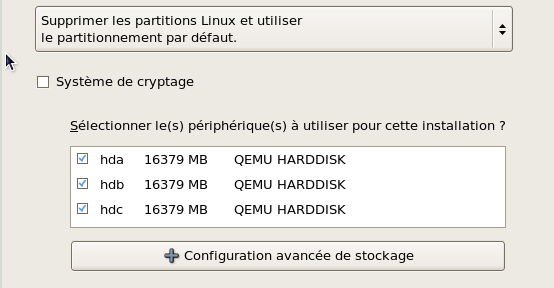 |
étant très paresseux je vais tenter le partitionnement par défaut en cochant aussi "Examiner et modifier la structure de stockage". Le bouton "+ Configuration avancée de stockage" permet même d'ajouter des cibles iSCSI directement. |
Après avoir confirmé que je veux bien partitionner les trois disques et que j'accepte de perdre toutes leurs données ... la proposition est de mettre les trois disques dans un Volume Group Unique de 48Go (mes trois disques de 16G) et deux volumes logiques: Swaq de 3G et une partition ext3 de 45G 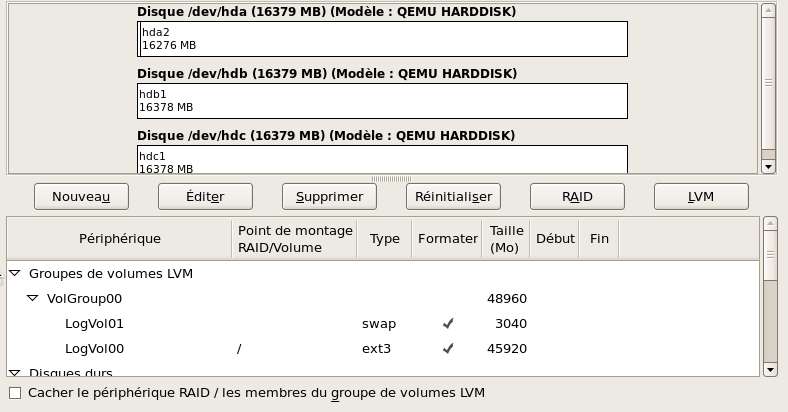
On peut sur ce même écran gérer la mise en RAID et affiner LVM.
Ce n'est pas tout à fait ce que je veux et je clique "sur "Réinitialiser". l'écran est aussitôt mis à jour et me présente chacun de mes 3 disques en "espace libre". Il est très aisé d'éditer un espace libre en cliquant le bouton "Editer" :
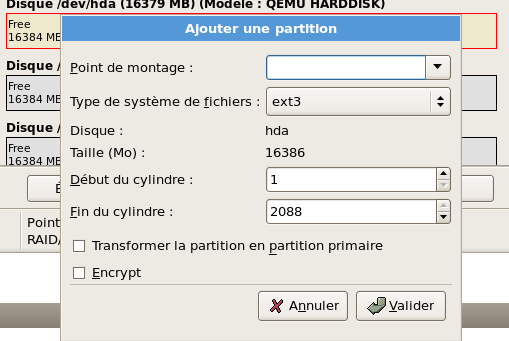 |
le disque sélectionné est même encadré de rouge, le luxe ! Je crée donc un espace de swap de 3G, une partition racine de 13G sur le premier disque et crée une partition simple sur chacun des deux autres disques (/DATA et /LOG). L'éditeur de partition est très complet et très agréable à manipuler. |
L'écran suivant permet de sélectionner le chargeur de démarrage et le disque d'installation 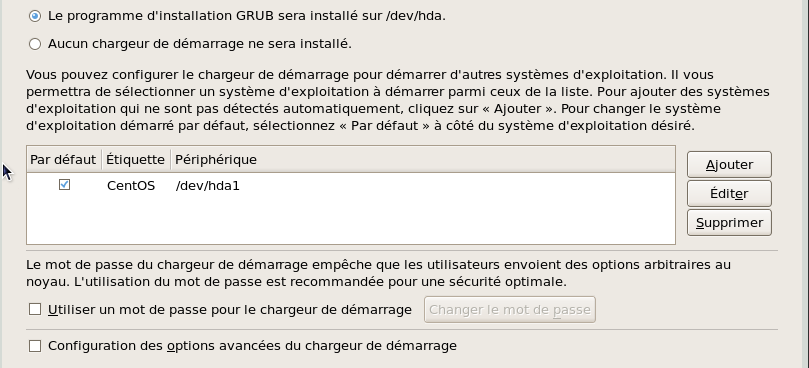
Je choisis d'installer GRUB sur /dev/hda1 par défaut, sans mot de passe ni options avancées.
L'écran suivant permet de configurer les cartes réseaux, noms d'hotes ..., je choisis de laisser le boulot à DHCP toujours sans IPV6 (tiens il faudra que je m'y mette à IPV6).
Ecran suivant : choisir son fuseau horaire (belle mappemonde), pour moi Europe/Paris est préselectionné ainsi que l'horloge système en UTC.
Ecran suivant : le mot de passe de "root" et c'est parti ...... pour la sélection des paquets à installer 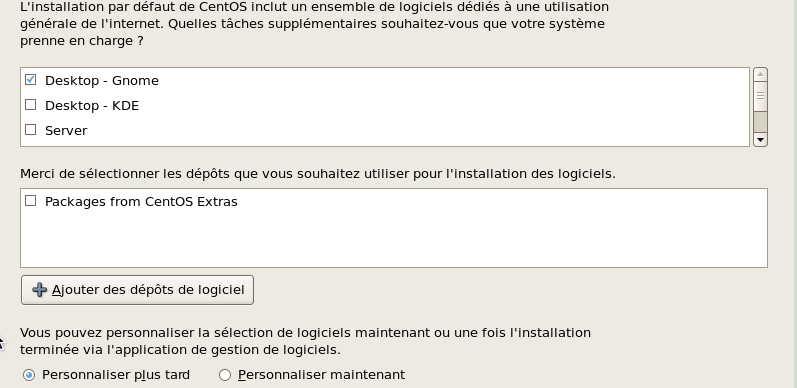
Je fais mon petit marché sans ajouter de dépot et choisis de "personnalier plus tard".
Les dépendances sont validées et il suffit de cliquer sur "Suivant" pour lancer l'installation. Une belle image s'affiche, les disques sont formatés rapidement, le "Démarrage du processus d'installation" est un peu laborieux (# 7 minutes) pendant ce temps quelque activité reseau vers des serveurs "centos".
Puis "Bienvenue dans Centos 5", l'installation commence : 
... les images changent de temps en temps pour occuper le temps et expliquent tout du rojet Centos. Le téléchargement est assez rapide (de 150 à 500 Ko/s avec des pointes à 800Ko/s) sur cette ligne qui plafonne à 850Ko/s. La durée prévue est d'environ 65 minutes, malgré la progession le remps restant reste longtemps aux environs de 60/65 minutes avant de dommencer à descendre.
L'installation choisie est assez complète et le volume à télécharger est donc assez conséquent et c'est enfin fini (environ 50 minutes)  Après mise à jour du fichier de configuration de la MV on reboote ... les trois disques sont bien là et le noyau 2.6.18 démarre et lance les étapes complémentaires de configuration :
Après mise à jour du fichier de configuration de la MV on reboote ... les trois disques sont bien là et le noyau 2.6.18 démarre et lance les étapes complémentaires de configuration :
Pare-feu : je le désactive bien que l'écran permette de gérer assez finement les ports.
SELinux : je le désactive lui aussi.
Kdump : je le laisse inactif
Date et heure : OK, je lancerai NTP plus tard.
Utilisateur ; je crée un utilisateur standard
Carte son : pas sur la machine virtuelle ...
CDROM supplémentaires : aucun
La "dévalidation" de SELinux oblige à un redémarrage qui s'effectue sans problèmes. L'écran X est lancé et Gconf me signale que le pourcentage mini de la batterie ne peut être à zéro, et ... aucun menu ne s'affiche à part les icones "Poste de travail" et "Corbeille".
Il faut : faire un clic droit sur le "mini panel" présent en haut à Gauche sur l'écran et choisir "Propriétés", on peut alors configurer un peu ce panel avec "Etendre". On peut déjà le voir, mais il ne contient toujours rien ... encore un clic droit et on peut y ajouter une "barre de menus" (ne pas oublier de la "Verrouiller") pour le rendre beaucoup plus sympathique.
On peut ensuite le personnaliser à loisir comme d'habitude.
Bizarre que rien ne soit configuré dans le "gnome-panel", probablement un bug qui devrait être vite réparé.
A chaque connexion le "Gestionnaire d'énergie" positionne une erreur : 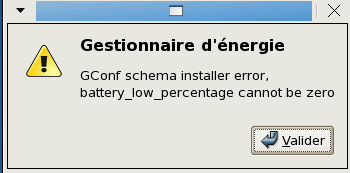
dont je n'arrive pas à me débarasser même en désactivant le gestionnaire d'énergie, bizarrement cela n'arrive pas pour le user "root".
Même après le rituel "yum update" (qui déclenche 136 mises à jour) ce bête message continue à s'afficher.
XEN : Linux + Oracle10g
XEN : Linux + Oracle10g jppUn petit tutoriel pour l'installation de Oracle 10g sur Linux.
C'est un peu ancien mais il y en a encore beaucoup, il y a même des entreprises qui n'ont pas encore migré vers Oracle 10 et restent en 9, 8 et même parfois Oracle 7 !
Le problème est ici que les dernières versions de Linux ne permettent pas l'installation (ou très difficilement) de Oracle 10g dans sa dernière version 10.2.
Ici, le choix s'est porté vers le Linux Oracle en version 4.8, il est probable qu'un Centos 4 ou un Suse 9 aurait pu convenir, mais je n'avais pas de Centos sous la main et la Suse 9 a refusé de s'installer dans la machine virtuelle prévue (blocage après la détection USB).
Celui-ci s'installe exactement comme le linux Centos55 (cf article).
La machine sur laquelle va être réalisée cette installation est constituée de :
- CPU 1
- RAM 1,5G
- Disques
- 20Go pour le système
- 32Go pour les données
- 1 adresse IP configurée "en dur", c'est important pour ne pas être ennuyé ensuite
Oracle 10 sur une OpenSuSE 11.4
Oracle 10 sur une OpenSuSE 11.4 jppOracle 10g commence à dater un peu et il peut être "délicat" de l'installer sur une distribution récente. Ce n'est pas le cas de la distribution OpenSuSE 11.4 sur laquelle Oracle 10 s'installe avec :
- les ajouts habituels aux paramètres systèmes :
/etc/sysctl.conf
kernel.shmall = 134217728
kernel.shmmax = 2147483648
kernel.semopn = 100
# semaphores: semmsl, semmns, semopm, semmni
kernel.sem = 250 32000 100 128
fs.file-max = 65536
net.ipv4.ip_local_port_range = 1024 65000
#
net.core.rmem_default = 262144
net.core.rmem_max = 262144
net.core.wmem_default = 262144
net.core.wmem_max = 262144
net.ipv4.tcp_rmem = 4096 87380 8388608
net.ipv4.tcp_wmem = 4096 65536 8388608
net.ipv4.tcp_mem = 4096 4096 4096
- une modification au fichier /etc/SuSE-release pour qu'il ressemble fortement à ceci :
openSUSE 9 (i586)
VERSION = 9
CODENAME = Celadon
L'installation doit ensuite se dérouler, comme pour moi, c'est à dire sans aucune difficulté.
XEN : Linux 4.8 + Oracle 10g
XEN : Linux 4.8 + Oracle 10g jppL'installation (en mode texte) est à peu près identique à celle de la version 5.4 présentée ici.
Attention, l'espace réservé au SWAP doit être eu moins égal à RAM * 1.5, dans mon cas RAM = 1024Mo, Swap = 2048Mo --> pré-requis largement rempli.
Une fois le système Linux installé on configure les variables système :
Ajouter dans /etc/sysctl.conf :
# add for Oracle
fs.file-max = 6815744
fs.aio-max-nr = 1048576
kernel.shmmni = 4096
kernel.shmall = 2097152
kernel.shmmax = 536870912
kernel.sem = 250 32000 100 128
net.ipv4.ip_local_port_range = 1024 65500
net.core.rmem_default = 262144
net.core.rmem_max = 4194304
net.core.wmem_default = 262144
net.core.wmem_max = 1048576
et dans /etc/security/limits.conf :
# for oracle
@dba soft nproc 2047
@dba hard nproc 16384
@dba soft nofile 65536
@dba hard nofile 131072
Mettre à jour les catalogues "yum" :
cd /etc/yum.repo.d
wget http://public-yum.oracle.com/public-yum-el4.repo
Dans le fichier "public-yum-el4.repo" mettre à jour la ligne "enabled=1" dans le paragraphe [el4_u8_base].
Lancer ensuite le rafraichissement du catalogue "yum update", attention il faut être patient, surtout si votre connexion n'est pas très rapide et plus le temps passe, plus il y a de mises à jour, aujourd'hui (Février 2011) il y a plus de mises à jour que lors du premier jet de cet article. Eh oui, je me sers de mes propres articles pour faire de nouvelles installations et j'y rajoute éventuellement un petit commentaire.
Puis charger les utilitaires indispensables tels que "vim-x11" qui fournit l'indispensable "gvim" par "yum install vim-X11".
Il faut aussi installer une version spécifique du paquet "libaio" puisqu'Oracle demande la version 0.3.96 exclusivement, celle chargée par "yum update" (version 0.3.105) n'est pas reconnue comme valide. (http://rpmfind.net). Le RPM trouvé crée un fichier "libaio.so.1" il m'a fallu créer un lien vers "libaio.so.0" ( ? ) pour que l'installeur accepte la librairie.
Le user "oracle" et le groupe "dba" sont créés.
Dans le disque monté sur "/DATA" créer un répertoire "u01" et "chown oracle:dba /DATA/u01", le fichier fstab sera agrémenté du montage de ce disque.
Le paquet "Oracle 10g" sera installé dans un coin tranquille ou rendu accessible par un montage Samba ou NFS.
On sera alors prêts pour la suite : l'installation de Oracle 10g
Ci dessous le fichier de paramétrage XEN de la machine virtuelle :
# Définition machine Linux Oracle 4.8 pour Oracle 10g
ostype='other'
name='com-ora10g'
memory=2048
vcpus=1
uuid='9b58d38c-1767-76f7-e865-3fa96ba392d2'
on_crash='destroy'
on_poweroff='destroy'
on_reboot='restart'
localtime=0
builder='hvm'
extid=0
device_model="/usr/lib/xen/bin/qemu-dm"
kernel='/usr/lib/xen/boot/hvmloader'
boot='c'
disk=[ 'phy:/dev/mapper/HUGE_1-COM_ORA10G_SYS,hdb,w',
'phy:/dev/mapper/DUO-COM_ORA10G_DATA,hdc,w',
# 'tap:aio:/MV/ORALINUX/Enterprise-R4-U8-x86_64-dvd.iso,hdd:cdrom,r'
]
vif=[ 'mac=00:16:3e:30:08:01,bridge=br0,model=rtl8139,type=ioemu',
]
vnc=1
vncunused=1
apic=0
acpi=1
pae=1
usb=1
usbdevice='tablet'
serial='pty'
XEN : Oracle 10, ajustements
XEN : Oracle 10, ajustements jppAprès le premier reboot, on tente le "dbstart" et on récupère l'infâme message :
Failed to auto-start Oracle Net Listener using /ade/vikrkuma_new/oracle/bin/tnslsnr
Il faut aller corriger le script $ORACLE_HOME/bin/dbstart et y ajouter (après la ligne 78) :
# ORACLE_HOME_LISTNER=/ade/vikrkuma_new/oracle
ORACLE_HOME_LISTNER=/home/oracle/oracle/product/10.2.0/db_1
Au prochain "dbstart" le listener démarrera correctement, sacré vikrkuma ! En plus il a signé son méfait.
Après un "bon" lancement la commande "lsnrctl service" nous renvoie la liste tant espérée :
Services Summary...
Service "PLSExtProc" has 1 instance(s).
Instance "PLSExtProc", status UNKNOWN, has 1 handler(s) for this service...
Handler(s):
"DEDICATED" established:0 refused:0
LOCAL SERVER
Service "orcl10g" has 1 instance(s).
Instance "orcl10g", status READY, has 1 handler(s) for this service...
Handler(s):
"DEDICATED" established:0 refused:0 state:ready
LOCAL SERVER
Service "orcl10gXDB" has 1 instance(s).
Instance "orcl10g", status READY, has 1 handler(s) for this service...
Handler(s):
"D000" established:0 refused:0 current:0 max:1022 state:ready
DISPATCHER <machine: com-ora10g.jpp.fr, pid: 16057>
(ADDRESS=(PROTOCOL=tcp)(HOST=com-ora10g.jpp.fr)(PORT=32815))
Service "orcl10g_XPT" has 1 instance(s).
Instance "orcl10g", status READY, has 1 handler(s) for this service...
Handler(s):
"DEDICATED" established:0 refused:0 state:ready
LOCAL SERVER
The command completed successfully
Le système est donc bien "prêt". Voyons voir ce que l'installeur nous a mis comme paramètres mémoire (sur la dbconsole) "Administration --> Memory parameters"
512MO de SGA répartis comme suit :
| SGA Component | Current Allocation (MB) |
| Shared Pool | 160 |
| Buffer Cache | 340 |
| Large Pool | 4 |
| Java Pool | 4 |
| Others | 4 |
et 192MO de PGA, cela sera très large pour nos essais.
Un petit tour dans "Administration --> All initialization parameters" pour voir un peu toute cette configuration "standard", 258 paramètres quand même.
"db_file_multiblock_read_count" est à 16, cela va très bien avec un bloc de 8K.
"db_keep_cache_size" et "db_recycle_cache_size" sont à blanc ce qui nous satiafait.
On cherche le "filesystemio_options" (à blanc par défaut) et lui met "DIRECTIO" juste pour voir.
Pour ce test pas d'archivelog, de flashback et autres complexités.
Au niveau du système je stoppe des services inutiles et modifie le fichier "/etc/inittab" pour démarrer en niveau 3, un serveur de BDD n'a pas besoin d'interface X ! Et cela économise de la mémoire.
Pour finir on reboote pour avoir "tout propre", peu après le démarrage le système occupe quand même #85Mo de mémoire.
Après le lancement de la base et de la dbconsole on est déjà à plus de 700Mo, se connecter à la console fait dépasser les 760Mo après le lancement de quelques opérations : création d'une table historique de #13 Millions de lignes par insertions multiples en modifiant les dates, la mémoire utilisée monte à 1,2G.
La dernière phase : générer 6,5 Millions de lignes en modifiant la date des 6,5 Millions de la table originale est effectuée en 63 secondes. Le tout occupe environ 640Mo sur le disque. L'insertion des mêmes 6,5 millions de rangs fraîchement générés dure #34 secondes, ça marche.
Un index composite (3 champs) est créé en 3' 45", un deuxième en 2' 55"...
Un petit tour dans "Administration --> All initialization parameters" pour voir un peu toute cette configuration "standard", 258 paramètres quand même.
"db_file_multiblock_read_count" est à 16, cela va très bien avec un bloc de 8K.
"db_keep_cache_size" et "db_recycle_cache_size" sont à blanc ce qui nous satiafait.
On cherche le "filesystemio_options" (à blanc par défaut) et lui met "DIRECTIO" juste pour voir.
Pour ce test pas d'archivelog, de flashback et autres complexités.
Au niveau du système je stoppe des services inutiles et modifie le fichier "/etc/inittab" pour démarrer en niveau 3, un serveur de BDD n'a pas besoin d'interface X ! Et cela économise de la mémoire.
Pour finir on reboote pour avoir "tout propre", peu après le démarrage le système occupe quand même #85Mo de mémoire.
Après le lancement de la base et de la dbconsole on est déjà à plus de 700Mo, se connecter à la console fait dépasser les 760Mo après le lancement de quelques opérations : création d'une table historique de #13 Millions de lignes par insertions multiples en modifiant les dates, la mémoire utilisée monte à 1,2G.
La dernière phase : générer 6,5 Millions de lignes en modifiant la date des 6,5 Millions de la table originale est effectuée en 63 secondes. Le tout occupe environ 640Mo sur le disque. L'insertion des mêmes 6,5 millions de rangs fraîchement générés dure #34 secondes, ça marche.
Un index composite (3 champs) est créé en 3' 45", un deuxième en 2' 55"..
Le calcul des statistiques sur cette table :
begin
dbms_stats.gather_schema_stats(ownname => 'test',estimate_percent => 90,
degree => 2);
end
dure #11 minutes.
XEN + Oracle 10G : mini test
XEN + Oracle 10G : mini test jppLe mini test a été réalisé selon la procédure décrite ici.
Remarque :
Cette machine est munie de disques "strippés" à priori deux fois plus rapides que les disques non strippés (voir article sur le stripping).
Calcul de la différence de dates :
select to_char( to_date(min(datec),'YYYYMMDD') - 180,'YYYYMMDD'),
min(datec), max(datec),
to_date(max(datec),'YYYYMMDD') - to_date(min(datec),'YYYYMMDD'),
count(*)
from xen_stat_v2 ;
Génération de la table temporaire :
set timing on
insert into toto
select to_char( to_date(datec,'YYYYMMDD') - DIFFERENTIEL_CALCULE ,'YYYYMMDD') as DATEC,
heurec,serveur,domnom,deltacpu,deltarx,deltatx,cpupct,
nbsecr,nbsecw
from xen_stat_v2;
Insertion des rangs calculés :
insert into xen_statv2 select * from toto
go
Après quelques itérations on arrive au volume voulu :
La table permanente a été mise en "nologging" pendant la durée des insertions et Le volume occupé par la table et ses deux index est d'environ 2200Mo.
Résultats du mini test.
- Test 1 création de deux index :
Index created.
Elapsed: 00:02:12.69
Index created.
Elapsed: 00:01:49.37
Soit un total de #242 secondes ou 5'02 ".
- Test 2 recalcul des statistiques :
set timing on
begin
dbms_stats.gather_table_stats(ownname => 'test',tabname => 'xen_stat_v2', estimate_percent => 100,
degree => 2);
end;
/
PL/SQL procedure successfully completed.
Elapsed: 00:06:14.64
Le calcul dure 6'14".
- Test 3 quelques "select" :
a) select DOMNOM,count(*) from xen_stat_v2 group by DOMNOM order by DOMNOM
go
- passe 1 : Elapsed: 00:00:12.46
- passe 2 : Elapsed: 00:00:08.97
Soit #11 secondes
b) select DOMNOM,count(*) from xen_stat_v2 group by DOMNOM order by DOMNOM
go
- passe 1 : Elapsed: 00:00:10.21
- passe 2 : Elapsed: 00:00:09.76
Soit #10 secondes
KVM : une autre virtualisation
KVM : une autre virtualisation jppComme XEN ne fonctionnait pas très bien pendant un temps sur ma distribution Debian (unstable), celle que je préfère pour tous les autres usages, (au minimum pas de X possible) j'ai décidé de tester une autre solution de virtualisation : KVM.
A l'occasion de tests sur SHINKEN j'ai récupéré une image de machine VMWARE facile à convertir en image QCOW2 utilisable par KVM.
Mais avant de lancer sa première machine KVM il faut préparer la machine (Kernel), installer quelques softs et modifier ses interfaces réseau (des "ponts" sont nécessaires).
Dans le premier article je vais détailler les pré-requis à KVM.
Remarque 2015/2016 :
La plupart des distributions intègrent aujourd'hui KVM dans leur noyaux, on n'est donc pas obligé de passer par la case "compilation du noyau", par contre il vaut mieux créer un "bridge" (ou plusieurs) au niveau réseau sur la machine hôte afin d'être très libre sur la configuration réseau des MV, ceci est précisé dans l'article sur les pré-requis.
Il faut bien-sûr installer les paquets "qemu/qemu-kvm" et "bridge-utils" dans votre système.
J'utilise KVM couramment sur les "petites" machines (Core I3) pour installer des "services", ou groupes de services, différents avec des environnements logiciels différents (Debian, Ubuntu LTS, Centos ...). La MV sur laquelle est installée ce site Web est une machine virtuelle KVM installée dans un "petit" système:
CPU : CoreI3 4130
Carte mère : MSI MS-7851/B85I
RAM : 16Go
Disques : Système sur SSD
: disques des machines KVM sur deux SSD en miroir.
Cette machine "abrite" aussi un service mail (Zimbra) et un outil de supervision (Shinken + Omeganoc).
Remarque août 2016 : cette machine a été remplacée par une carte mère Asus et un coreI5 5665C dans un mini boîtier Lian Li.. Le contenu est resté le même mais tous les services sont hébergés dans des machines virtuelles KVM.. La supervision (Shinken + Thruk + Omeganoc), Zimbra et le serveur Web hébergeant ce site ont été installés dans des machines viruelles KVM logées dans ce seul serveur physique.
Note 2022 : La machine hébergeant les principales VM a été changée, c'est maintenant un processeur "AMD Ryzen 5 3600 6-Core" avec 32Go de RAM et le suivi des performances est assuré par une MV prometheus avec des "clients" installés dans toutes les machines.
KVM : le réseau
KVM : le réseau jppLa partie réseau a été préparée sur la machine "hôte" par la création du "bridge" dans l'article précédent, il ne nous reste plus qu'à "activer" un interface qui permettra à notre Machine Virtuelle de communiquer avec l'extérieur.
Il nous faut réaliser les opérations suivantes :
- Créer un interface "tap0" (nom consacré par l'usage ?) à l'aide de "tunctl" et l'affecter à notre user.
- Activer cet interface
- L'ajouter à notre bridge "br0" (là aussi nom consacré)
Ces opérations sont enchaînées par le petit script suivant qui demande deux paramètres :
- Le numéro de switch (br0 ... n)
- Le nom de l'interface (tap0 ... n)
|
#!/bin/bash echo '1 = switch : '$switch |
Résultat, après avoir lancé le script avec en paramètres : br0 tap0 , on vérifie :
| sudo ifconfig tap0 tap0 Link encap:Ethernet HWaddr 2a:8d:39:8d:b7:62 UP BROADCAST MULTICAST MTU:1500 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:500 RX bytes:0 (0.0 B) TX bytes:0 (0.0 B) |
Notre interface réseau semble fin prête.
Pour le stopper il suffit de lancer le petit script suivant avec les mêmes paramètre "br0 tap0" pour effacer notre interface virtuel et tout remettre "à blanc" :
| #!/bin/bash switch=$1 IFNAM=$2 sudo /sbin/ifconfig $IFNAM down sudo brctl delif $switch $IFNAM |
Attention si vous voulez lancer deux MV ou plus, il faudra utiliser "tap1, tap2 ..." et pas deux fois le même ! Sinon vous vous ferez "tap"er sur les doigts.
KVM : pré-requis, installation
KVM : pré-requis, installation jppPour les tests de shinken 0.4 j'ai récupéré une image qu format VMWARE et, au lieu de la transformer en image XEN j'ai voulu tester au passage la virtualisation avec KVM.
Première opération : compiler KVM dans le noyau Linux (ici le kernel 2.6.37.rc8), et ça marche encore pour les noyaux 3.X et 4.X.
Lancer le "make menuconfig" :
┌────────────────────────────────────────────────────────────────────────┐ │
│ │ General setup ---> │ │
│ │ [*] Enable loadable module support ---> │ │
│ │ -*- Enable the block layer ---> │ │
│ │ Processor type and features ---> │ │
│ │ Power management and ACPI options ---> │ │
│ │ Bus options (PCI etc.) ---> │ │
│ │ Executable file formats / Emulations ---> │ │
│ │ [*] Networking support ---> │ │
│ │ Device Drivers ---> │ │
│ │ Firmware Drivers ---> │ │
│ │ File systems ---> │ │
│ │ Kernel hacking ---> │ │
│ │ Security options ---> │ │
│ │ -*- Cryptographic API ---> │ │
│ │ [*] Virtualization ---> │ │
│ │ Library routines ---> │ │
│ └──────────v(+)────────────────────────────────────────────────────────┘ │
Cocher la case "Virtualization" et aller dans le détail et sélectionner le type de processeur (ici c'est AMD) : ┌────────────────────────────────────────────────────────────────────────┐ │
│ │ --- Virtualization │ │
│ │ <M> Kernel-based Virtual Machine (KVM) support │ │
│ │ <M> KVM for Intel processors support │ │
│ │ < > KVM for AMD processors support │ │
│ │ <M> Host kernel accelerator for virtio net (EXPERIMENTAL) │ │
│ │ <M> PCI driver for virtio devices (EXPERIMENTAL) │ │
│ │ <M> Virtio balloon driver (EXPERIMENTAL) │ │
│ │ | |
| ├──────────────────────────────────────────────────────────────────────┤ |
Cocher les cases correspondant à votre type de processeur (AMD/INTEL), et les trois dernières aussi. Puis compilation, installation, reboot et c'est OK !
Il faut ensuite installer :
- qemu-kvm
- uml_utilities
- bridge-utils
Pour pouvoir lancer des machines virtuelles et leur fournir un accès au réseau.
apt-get pour moi, yum pour d'autres ...
Deuxième opération : création d'un "bridge".
Le bridge peut être installé en permanence, le réseau fonctionne très bien pour la machine principale si un bridge est déclaré. Sur un système Debian il faut modifier le fichier "/etc/network/interfaces" comme suit :
Avant :
auto eth0
iface eth0 inet static
address 192.168.1.XXX
netmask 255.255.255.0
network 192.168.1.0
gateway 192.168.1.xxx
broadcast 192.168.1.255
Après :
auto br0
iface br0 inet static
address 192.168.1.XXX
netmask 255.255.255.0
network 192.168.1.0
broadcast 192.168.1.255
gateway 192.168.1.xxx
bridge_ports eth0
bridge_maxwait 1
Ensuite rebooter la machine pour vérifier si tout est OK, et tester :
sudo ifconfig br0
br0 Link encap:Ethernet HWaddr 00:1b:2f:bf:11:c7
inet addr:192.168.1.XXX Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:53550 errors:0 dropped:0 overruns:0 frame:0
TX packets:85015 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:54066193 (51.5 MiB) TX bytes:17172164 (16.3 MiB)
Tout est alors prêt sur le système hôte pour lancer notre première machine virtuelle KVM ... dès que la partie réseau sera au point coté KVM.
KVM : la première machine
KVM : la première machine jppTout étant prêt nous allons pouvoir lancer notre première machine. Comme je l'ai expliqué au début de cet article j'ai récupéré une image de disque VMWARE que j'ai convertie en image adaptée à KVM (format QCOW2) par la commande miracle :
qemu-img convert shinken-vm-0.4.vmdk -O qcow2 shinken-vm-0.4.kvm
Il s'agit donc d'une "machine pré-fabriquée" où tout est déjà installé, un prochain article détaillera la construction d'une nouvelle machine.
Une fois le disque disponible on va s'occuper des paramètres nécessaires à KVM :
- Un disque on peut installer de "-hda" à "-hdd" et "-cdrom"
- De la RAM (-m ...M)
- Un nom ( -name ....)
- Un clavier français !
- Le lancement en "démon" ou pas (-daemonize)
- Une carte réseau avec son adresse MAC, couplée à notre tap0
- Le fonctionnement du disque en normal ou "snapshot" qui empêche toute modification du disque utilisé (ça peut servir !).
Lancez l'interface "TAP0" avant de lancer la MV. Le script suivant pourra vous permettre de démarrer comme moi une machine minimum avec un seul disque, mais un clavier français et le réseau :
| #!/bin/bash HDA=/RAIDHOME/soft/tmp/shinken-vm-0.4/shinken-vm-0.4.kvm NOM=kvmtest RAM=256M # clavier FR OPTION=' -k fr ' # demoniser DEMON=' ' DEMON=' -daemonize ' # pas de snapshot SNAPSHOT=' -snapshot ' SNAPSHOT=' ' RESEAU=' -net nic,macaddr=00:1d:92:ab:3f:78 -m 256 -net tap ' RESEAU=${RESEAU}' ifname=tap0,script=no,downscript=no ' kvm ${DEMON} ${SNAPSHOT} -hda ${HDA} -boot c -name ${NOM} -m ${RAM} ${OPTION} ${RESEAU} |
Et cela doit démarrer sans aucun problème, Ah, j'ai failli oublier, pour "sortir" de l'écran de votre machine KVM : Ctrl+Alt (à garder appuyé), puis aller cliquer sur la barre d'une autre fenêtre. Soyez patients, quelque fois cela "foire" un peu et il faut "titiller" légèrement la souris !
Il vous faudra reconfigurer la carte réseau de votre nouveau système afin que la carte fournie (Adresse MAC) soit reconnue au boot. Un petit tour dans "/etc/udev/rules.d" est très instructif. Supprimer les "cochonneries" dans le fichier "70-persistent-net.rules" (sur une distribution Debian, mais les autres n'ont pas l'air très différentes de ce coté) et modifier la ligne "eth0" en y indiquant votre "adresse MAC".
# This file was automatically generated by the /lib/udev/write_net_rules # program, run by the persistent-net-generator.rules rules file. # # You can modify it, as long as you keep each rule on a single # line, and change only the value of the NAME= key. # PCI device 0x10ec:0x8139 (8139cp) SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:1d:92:ab:3f:88", ATTR{dev_id}=="0x0", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0" |
Attention tout est sur une seule ligne !
Un autre petit tour dans /etc/network/interfaces pour vérifier que eth0 est bien en DHCP, si vous n'avez pas de serveur DHCP utilisez une adresse fixe à déclarer dans votre service DHCP :
# The primary network interface
allow-hotplug eth0
iface eth0 inet dhcp
Et pour moi c'est OK, si vous n'avez pas de DHCP :
allow-hotplug eth0
iface eth0 inet static
address 192.168.1.AAA
netmask 255.255.255.0
network 192.168.1.0
gateway 192.168.1.XXX
broadcast 192.168.1.255
Un petit coup de "ifdown eth0" suivi d'un "ifup eth0" devrait activer votre réseau et vous montrer que la liaison est OK :
| sudo netstat -rn Table de routage IP du noyau Destination Passerelle Genmask Indic MSS Fenêtre irtt Iface 192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0 0.0.0.0 192.168.1.XXX 0.0.0.0 UG 0 0 0 eth0 ping -c1 www.google.fr PING www.l.google.com (74.125.230.80) 56(84) bytes of data. 64 bytes from 74.125.230.80: icmp_req=1 ttl=54 time=135 ms --- www.l.google.com ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 135.909/135.909/135.909/0.000 ms |
Ca marche vraiment !
KVM mais c'est très simple !
KVM : installer une nouvelle machine virtuelle
KVM : installer une nouvelle machine virtuelle jppPour installer une nouvelle machine virtuelle KVM il faut, comme pour une machine physique disposer de :
- un disque (au moins)
- une carte mère et ses accessoires (vidéo, réseau, clavier ....)
- un boitier
- de la RAM
- un processeur
- une source d'installation, en général CD ou DVD
Les seuls éléments non virtuels dont nous allons avoir besoin sont :
- un disque, ou un morceau de disque (vive LVM)
- une source d'installation.
Tout le reste est fourni par KVM.
Le disque.
Le "disque" attribué à notre nouvelle machine peut être :
- Un fichier (à initialiser en format QCOW2 de préférence)
- Une partition sur un disque (partition physique ou LVM)
Dans mon cas j'ai tendance à utiliser des partitions créées "à la demande" grâce à LVM, je dispose (encore) de place pour caser quelques partitions de test. J'ai donc réservé 10Go d'espace sur un volume.
La source d'installation.
Il s'agit ici d'une image ISO de l'installation de Debian Squeeze, même pas besoin de la graver et d'ouvrir le lecteur.
Script d'installation.
J'aime bien les scripts car on peut répéter les opérations tant que l'on veut en frappant juste sur quelques touches au lieu de cliqueter comme un fou dans un bel interface graphique, on finit par ne plus savoir sur quoi on a cliqué .... Bon, le script :
| #!/bin/bash HDA=/dev/DUO/TEST CDROM=/RAIDHOME/soft/debian-squeeze-di-beta1-i386-CD-1.iso NOM=kvm-new RAM=256M OPTION=$OPTION' -vnc :1 ' OPTION=' ' # clavier FR OPTION=' -k fr ' # on ne demonise pas la première fois, intervertir les lignes ensuite DEMON=' -daemonize ' DEMON=' ' # pas de snapshot SNAPSHOT=' -snapshot ' SNAPSHOT=' ' RESEAU=' -net nic,macaddr=00:1d:92:ab:3f:88 -m 256 -net tap,ifname=tap1,script=no,downscript=no ' # Ligne à décommenter pour le fonctionnement normal # kvm $DEMON $SNAPSHOT -hda $HDA -boot c -name $NOM -m $RAM $OPTION $RESEAU # # Ligne à décommenter pour l'installation, la "recommenter" après kvm $DEMON $SNAPSHOT -hda $HDA -cdrom $CDROM -boot d -name $NOM -m $RAM $OPTION $RESEAU |
On retrouve la plupart des éléments du script "standard" avec une variante pour le premier boot sur l'image du CD d'installation. On retrouve en "HDA" le nom de la partition LVM présentée par le device mapper, en "CDROM" mon image ISO.
Après le lancement du script on se trouve en face d'une installation absolument "standard", la virtualisation est parfaite. Je n'ai eu qu'un seul problème car j'ai d'abord voulu installer sur une partition "ROOT" en EXT4 et l'installation s'est plantée au cours de l'installation du système de base, je n'ai pas insisté et suis revenu au bon vieil EXT3.
Note 2016 : EXT4 fonctionne maintenant fort bien !
J'ai utilisé, par précaution, l'installation en mode texte mais j'ai l'impression que l'installation doit être possible en mode graphique.
Note 2017: Le mode graphique, plus beau, fonctionne très bien.
L'ensemble de l'installation s'est déroulé à une vitesse quasiment normale, y compris le chargement des nouveautés depuis le site Debian. J'ai ensuite résisté à la tentation de rebooter avant de modifier le script pour le ramener au mode "normal" sans CD.
Après ce reboot le démarrage en mode graphique est parfait et j'accède à un écran X en mode 800x600 dont la souris n'est pas asthmatique et obéit aux sollicitations. On peut même réduire l'écran à une toute petite taille, il reste lisible car tout est réduit en proportion. Tiens cela va me permettre de mettre une image dans le style timbre-poste.
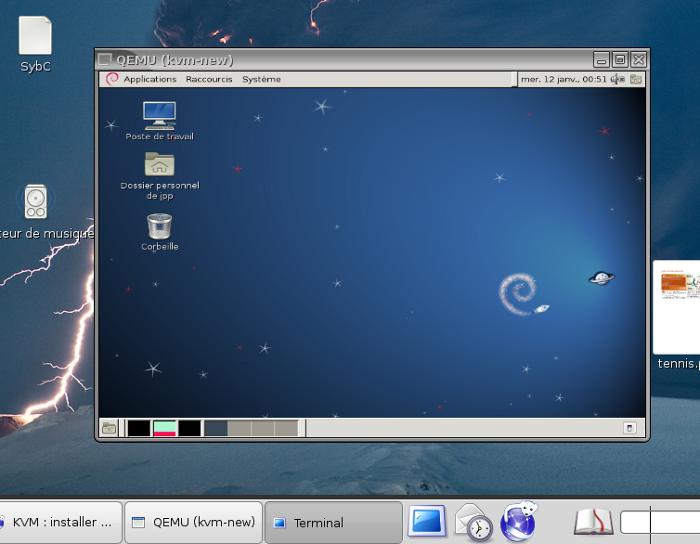 |
C'est-y pas beau ? Et en plus on peut travailler à l'aise dans la machine virtuelle, les temps de réponse sont excellents. Le boot : moins de 18 secondes entre le lancement de la commande et l'accès à l'écran de login !
KVM : Debian + Oracle XE
KVM : Debian + Oracle XE jppJ'ai eu besoin pour tester des scripts de construire rapidement une machine supportant une version 10.x de Oracle.
J'ai choisi d'utiliser KVM "pour voir" avec une installation "basique" d'une Debian 32 bits.
L'installation ne comporte aucun élément graphique, juste le système de base + un serveur SSH.
Ce système s'installe très rapidement. Pendant ce temps le téléchargement de la version Oracle "XE" a le temps de s'effectuer. Oracle ayant le bon goût de proposer un package Debian l'installation sera rapide.
Le seul pré-requis est l'installation de libaio1 :
apt-get install libaio1
qui installe très rapidement (moins de 100K) la version libaio1 (0.3.107-3)
Une fois le téléchargement du paquet "oracle-xe-universal_10.2.0.1-1.0_i386.deb" il suffit de le transférer dans la machine.
Mon disque système étant assez petit (#4Go) j'ai prévu un disque "DATA" de 8Go pour y installer Oracle. La seule "astuce" est de monter ce disque dans "/usr/lib/oracle" que l'on aura créé auparavant.
Ensuite :
| dpkg -i oracle-xe-universal_10.2.0.1-1.0_i386.deb (Reading database ... 24959 files and directories currently installed.) Preparing to replace oracle-xe-universal 10.2.0.1-1.0 (using oracle-xe-universal_10.2.0.1-1.0_i386.deb) ... Unpacking replacement oracle-xe-universal ... Setting up oracle-xe-universal (10.2.0.1-1.0) ... insserv: warning: script 'K01oracle-xe' missing LSB tags and overrides insserv: warning: script 'oracle-xe' missing LSB tags and overrides Executing Post-install steps... You must run '/etc/init.d/oracle-xe configure' as the root user to configure the database. Processing triggers for man-db ... etc/init.d/oracle-xe configure Oracle Database 10g Express Edition Configuration ------------------------------------------------- This will configure on-boot properties of Oracle Database 10g Express Edition. The following questions will determine whether the database should be starting upon system boot, the ports it will use, and the passwords that will be used for database accounts. Press <Enter> to accept the defaults. Ctrl-C will abort. Specify the HTTP port that will be used for Oracle Application Express [8080]: (Entrée) Specify a port that will be used for the database listener [1521]: J'ai répondu (Entrée) pour accepter le standard. Specify a password to be used for database accounts. Note that the same password will be used for SYS and SYSTEM. Oracle recommends the use of different passwords for each database account. This can be done after initial configuration: Confirm the password: Do you want Oracle Database 10g Express Edition to be started on boot (y/n) [y]: J'ai répondu "N" Starting Oracle Net Listener...Done Configuring Database... Starting Oracle Database 10g Express Edition Instance...Done Installation Completed Successfully. To access the Database Home Page go to "http://127.0.0.1:8080/apex" |
Ne pas oublier ensuite de lancer (en "root") : /etc/init.d/oracle-xe configure
Ma machine ne comporte pas d'interface graphique, il m'est impossible d'accéder à l'interface Web fourni (APEX), il ne me reste qu'à effectuer la mise à jour adéquate à l'aide de "sqlplus system/le_mot_de_passe"
en lançant la commande :
EXEC DBMS_XDB.SETLISTENERLOCALACCESS(FALSE);
et miracle ! Le service Web est alors accessible depuis l'extérieur de la machine.
 |
Ce petit interface est assez sympa, et bien que simple, permet de gérer convenablement une base limitée à 5Go.
L'essayer c'est l'adopter.
KVM : sauvegarde gagner du temps
KVM : sauvegarde gagner du temps jppLes machines virtuelles (ici KVM/QEMU), c'est bien mais il faut aussi les sauvegarder.
J'assure le backup des disques de mes machines virtuelles à l'aide de dd + bzip2 et j'ai constaté que la taille du backup résultant ne fait que croître au cours du temps ...
Exemple : sur une machine munie d'un disque de 32Gb le backup consommait à l'origine environ 5Gb, après quelques mois de fonctionnement la taille du backup atteint 13 Gb.
Or le système n'a que peu été modifié et a "subi" principalement les mises à jour de l'OS et l'activité normale d'une machine : écrire des logs, utiliser une base de données, faire tourner les logs (logrotate) fournir un service Web (3000/5000 pages par jour).
| Filesystem 1K-blocks Used Available Use% Mounted on udev 10240 0 10240 0% /dev tmpfs 307348 4808 302540 2% /run /dev/vda3 30971828 6780496 22594968 24% / /dev/vda1 944120 56628 822316 7% /boot |
Le filesystem "root" n'est rempli qu'à 24% mais doit finir par être désorganisé et surtout plein de secteurs qui ont été utilisés et qui ne le sont plus mais comportent des données "aléatoires" peu compressibles. Une sauvegarde par un simple "tar" serait presque moins volumineuse !
C'est alors que "zerofree" intervient, il permet de forcer des zéros dans toutes les zones inutilisées du filesystem ce qui les rend beaucoup plus apte à la compression.
La procédure que j'ai utilisée nécessite l'arrêt de la machine virtuelle car "zerofree" ne peut pas écrire sur un FS monté en lecture/écriture.
Par commodité j'ai effectué les opérations comme suit :
- stopper la VM
- attacher le disque à une VM "de travail"
- monter le disque en lecture seule sur la VM de travail, par exemple sur /mnt
mount /dev/xxx1 /mnt -o ro - lancer "zerofree"
zerofree -n /dev/xxx1 - démonter le disque
umount /mnt - stopper la VM de travail
- relancer la VM originale
On peut intercaler la sauvegarde proprement dite avant de relancer la VM originale. L'opération de "zéroification" est relativement rapide et donne de bons résultats sur les sauvegardes (Ci dessous pour une partition de #30Gb) :
Résultats :
Avant "zéro-ification"
|
Sauvegarde disque /dev/mapper/VG00-COM--WEB -rw-r--r-- 1 root root 13735399619 févr. 28 16:11 VG00-COM--WEB.dd.bz2 |
Après "zéro-ification" :
|
Sauvegarde disque /dev/mapper/VG00-COM--WEB -rw-r--r-- 1 root root 4492903322 févr. 28 17:51 VG00-COM--WEB.dd.bz2 |
Le gain d'espace est d'environ 9Gio (-66%), celui de temps est très appréciable lui aussi #25 minutes contre un peu plus d'une heure (-60%).
C'est dons une opération à renouveler régulièrement et qui ne dure pas très longtemps :
|
- Sur partition /boot 954Mio - sur partition / 30,1Gio |
La seule chose dont il faut disposer est d'une machine virtuelle avec son propre disque système sur laquelle on peut "attacher" le disque à "zéroifier".
Et un peu de temps #1Gio = 12s, #30Gio un peu plus de 5 minutes, ce qui est "rentable" à coté des 35 minutes gagnées sur la sauvegarde.
KVM : script d'init
KVM : script d'init jppPour utiliser KVM comme j'en avais envie il fallait que ces machines puissent démarrer lors de la séquence de boot de la machine hôte. Or, a priori, le lancement demande un écran ! Heureusement l'option
--nographic est là.
Cette machine virtuelle est destinée à contenir la MV qui héberge ce site, vu qu'il y a peu de machines et services à surveiller une puissance importante n'est pas nécessaire.
Le script de lancement devient alors :
|
#!/bin/bash HDA=/dev/mapper/VG00-WEB_PHP7 HDB=/dev/mapper/VG01-WEB_PHP7_SAUVE EXEC='qemu-system-x86_64 -enable-kvm -machine type=pc,accel=kvm:tcg -mem-path /dev/hugepages ' NOM=web-php7 # Creation port "Monitor" pour arrêt machine RESEAU=' -net nic,macaddr=00:16:3e:31:31:01 -net tap,ifname=tap10,script=no,downscript=no ' # Normal launch |
xxxxxxxxx
KVM : script d'init ancien
KVM : script d'init ancien jppPour utiliser KVM comme j'en avais envie il fallait que ces machines puissent démarrer lors de la séquence de boot de la machine hôte. Or, a priori, le lancement demande un écran ! Heureusement l'option --nographic est là.
La machine virtuelle est destinée à contenir une instance de Shinken (analogue au célèbre Nagios mais avec une architecture bien plus souple et évoluée), vu qu'il y a peu de machines et services à surveiller une puissance importante n'est pas nécessaire.
Le script de lancement devient alors :
|
#!/bin/bash
HDA=/dev/mapper/VG00-SHINKEN_SYS NOM=kvm-shinken
RAM=420M
# clavier FR
OPTION=' -k fr '
OPTION=$OPTION' -nographic '
DEMON=' -daemonize '
# appel script de creation de l'interface "tap"
./qemu-ifup br0 tap1
RESEAU=' -net nic,macaddr=00:16:3e:90:03:01 -net tap, \ ifname=tap1,script=no,downscript=no '
kvm $DEMON -hda $HDA -boot c -name $NOM -m $RAM $OPTION $RESEAU
|
|
#!/bin/bash
HDA=/dev/mapper/VG00-COM--WEB NOM=toto # Appel du script de création de l'interface réseau # Paramétrage réseau # On lance en background avec l'oprion -nographic |
Cette dernière version de script tourne parfaitement sur "Jessie" et "unstable".
|
#!/bin/bash
### BEGIN INIT INFO # Provides: shinken
# Required-Start: $network $remote_fs $syslog $time cron
# Default-Stop: 0 1 2 3 6
# Default-Start: 5
# Required-Stop:
# Description: shinken through KVM
### END INIT INFO
FCMD=/tmp/FCMD
case "$1" in
start)
echo 'cd /etc/kvm' >$FCMD
echo './script-noscreen ' >>$FCMD
# Lancement différé pour ne pas surcharger le démarrage de l'hote
cat $FCMD | at now +2 minutes
RETVAL=$?
rm $FCMD
;;
stop)
ssh -i /root/.ssh/la_belle_clef root@machine 'init 0 '
RETVAL=$?
# on laisse à la MV le temps de stopper
echo $0' sleeping 20 sec'
sleep 20
;;
reload|status)
echo 'Not implemented'
RETVAL=$?
;;
*)
echo $"Usage: $0 {start|stop|restart|reload|status}"
RETVAL=1
esac
exit $RETVAL
|
Script init systemd
Script init systemd jppARTICLE EN COURS DE REALISATION.
Les scripts d'init "old fashion" c'est fini, il faut passer par "systemd" pour que tout se passe bien au démarrage de la machine "support".
Afin de pouvoir automatiser totalement le start/stop des machines j'ai choisi d'utiliser les possibilités de gestion liées à qemu (installer "qemu-agent" sur les machines virtuelles) en utilisant un "socket" qui permet de transmettre des ordres tels "powerdown" depuis un script externe, ici lancé par "systemctl stop xxxxxxx".
Il nous faut d'abord créer un fichier "service" à placer dans /lib/systemd/system selon le modèle suivant :
| # Manually generated by myself [Unit] Description=Lancement VM Web # After network After=networking.target nss-lookup.target [Service] Type=forking Restart=no TimeoutSec=20s # GuessMainPID=no RemainAfterExit=yes # ExecStart=/etc/kvm_n-portail/LANCE web ExecStop=/etc/kvm_n-portail/STOPVM web [Install] WantedBy=multi-user.target |
Il faut ajouter dans le script de démarrage de la machine virtuelle mettre en place le socket de communication avec le "guest-agent':
| # Creation port "Monitor" pour arrêt machine GUEST=' -monitor unix:/tmp/monitor_web,server,nowait ' |
Ce paramètre "GUEST" est à ajouter dans la commande de lancement :
qemu-system-x86_64 -enable-kvm ...... ${GUEST}
Le script "systemd" fait appel à des scripts bash "simples" pour lancer et stopper les machines.
Script LANCE :
|
#!/bin/bash ret=0 |
Le script pour stopper une machine est bati sur le même principe, STOP :
| #!/bin/bash SOCK=/tmp/monitor ret=0 case "$1" in web) SOCK=${SOCK}'_web' if [ -S ${SOCK} ] then echo system_powerdown | socat - UNIX-CONNECT:${SOCK} sleep 10 else echo ${SOCK}' absent' ret=2 fi ;; ### n paragraphes identiques *) echo 'Aucune machine ('$1')' ret=1 ;; esac exit $ret |
That's all folks !
LXC des conteneurs légers
LXC des conteneurs légers jppLa grande mode actuelle est aux containers, après quelques essais avec Docker j'ai été déçu, ce n’est pas facile à installer, ni à utiliser et j’y ai trouvé des limitations fortes.
Au hasard de mes lectures j’ai trouvé des articles sur un logiciel connu depuis longtemps mais peu utilisé : LXC.
Cette possibilité de créer des « Machines » légères, qui, contrairement à d’autres systèmes, utilisent le noyau de la machine support. L’empreinte disque de ces « machines » est donc bien moindre et il n’y a pas grand-chose à installer sur un système normal car presque tout est déjà disponible.
Les outils LXC sont très légers et semblent performants, un ensemble de modèles (templates ?) de création de conteneurs est disponible et permet déjà de réaliser des installations faciles. L’isolation entre les containers (ou conteneurs?) semble au moins aussi bonne que celle de Docker et consorts.
J’ai donc décidé de réaliser quelques tests en commençant par l’installation d’une Debian 10 "de base" donc tout à fait standard.
Afin de ne pas être ennuyé par les problèmes réseau, et pour ne pas « casser » la config de la machine de test j’ai monté une nouvelle carte réseau agencée en mode pont (bridge pour les fanatiques) dédiée à LXC.
Les articles suivants devraient vous permettre de « démarrer » rapidement un conteneur LXC en mode privilégié, on passera ensuite au mode non-privilégié qui est quand même plus sécurisant.
LXC : quelques commandes
LXC : quelques commandes jppD’abord quelques commandes « lxc » (les principales pour commencer) :
La plupart des commandes sont constituées du préfixe « lxc- » suivi d’un suffixe qui précise l’action à exécuter, le tout est assez simple à mémoriser. Pour les autres commandes voir dans /usr/bin.
Quelques paramètres généraux utilisés par la plupart des commandes :
- -n suivi du nom de l’instance
- -o nom d’un fichier pour stocker le log de l’opération
- -P chemin vers le répertoire de stockage, si absent lxc utilise par défaut /var/lib/lxc
Les commandes principales :
- lxc-checkconfig
Avant toute choses s'assurer que votre kernel dispose bien des options nécessaires à LXC.
- lxc-create :
Création d’une nouvelle instance, les paramètres précisent le template à utiliser ( t nom_du_template). Exemple :
lxc-create -name debian-a -t debian
Le nom à indiquer est le nom du template (/usr/share/lxc/templates) sans le préfixe « lxc- ».
L’exemple indiqué crée une machine nommée « debian-a » avec le template « lxc-debian ». - lxc-start : Démarre l’instance dont le nom est donné en paramètre.
- lxc-stop : Stoppe la machine dont le nom est donné en paramètre.
- lxc-attach nom de l’instance
Vous «attache » une console avec un shell sur la machine donnée en paramètre. - lxc-copy -n machine_modèle -N nouvelle machine
Avec plein d’autres options pour faire des copies éphémères, changer le répertoire de stockage de l’image ….
- lxc-freeze nom de l'instance
Permet de geler une instance dont le nom est donné en paramètre, l’instance est bloquée mais peut être débloquée par lxc-unfreeze - lxc-snapshot
Réalise un snapshot de la machine dont le nom est donné en paramètre. Cela peut être très utile en phase de création d’une nouvelle instance.
Le paramètres « -L » permet de lister les snapshots existants d’une instance.
Le paramètre « -r » permet de restaurer un snapshot. - lxc-destroy -n nom de la machine
Détruit l’instance donnée en paramètre, options « -f » pour force et « -s » pour détruire aussi les snapshots. - lxc-ls
Liste les machines existantes et leur état, l’option « -f » rend le tout plus joli et lisible.
J'ai même créé un script remplaçant qui appelle une copie de lxc-ls avec l'option "-f". - lxc-info
Affiche les informations principales de l'instance donnée en paramètre.
Pour les détails de paramétrage voir les pages « man » qui sont bien faites.
LXC : le réseau
LXC : le réseau jppLXC le réseau.
La partie réseau est gérée par « lxc-net » qui est un démon que se lance au démarrage du système.
Sa configuration n’est pas complexe mais, pour être fonctionnelle rapidement, nécessite la création d’une interface « pont » dédiée et donc la présence des "br-utils".
Ici et pour ne pas modifier une configuration réseau « qui marche » déjà avec deux ponts j’ai préféré rajouter une carte réseau dédiée dans ma machine de développement. Le seul problème que j’ai rencontré est le fait que l’interface supplémentaire s’est « intercalée » entre les deux interfaces existantes et qu’il a fallu que je modifie la config d'un des deux ponts déjà existants … "ensp3s0" est devenu "ensp4s0" dans ma config.
J’ai ajouté dans /etc/network/interfaces :
allow-hotplug enp3s0 iface br2 inet static address 192.168.3.1 netmask 255.255.255.0 network 192.168.3.0 broadcast 192.168.3.255 bridge_ports enp3s0 bridge_maxwait 1
Contenu du fichier de config de « lxc-net « dans / etc / default / lxc-net :
USE_LXC_BRIDGE="true"
LXC_BRIDGE="br2"
LXC_ADDR="192.168.3.1"
LXC_NETMASK="255.255.255.0"
LXC_NETWORK="192.168.3.0/24"
LXC_DHCP_RANGE="192.168.3.0,192.168.3.255"
LXC_DHCP_MAX="254"
LXC_DHCP_CONF_FILE=""
LXC_DOMAIN=""
En ce qui concerne le fichier de config de mon instance « debian-a » déjà créée par « lxc-create -n debian-a -t debian » j’ai ajouté à la fin du fichier /var/lib/lxc/debian-a/config :
# pour le réseau eth0
lxc.net.0.type = veth
# lxc.net.0.veth.mode = bridge
lxc.net.0.link = br2
lxc.net.0.name = eth0
lxc.net.0.ipv4.address = 192.168.3.11/24
lxc.net.0.ipv4.gateway = 192.168.3.1
lxc.net.0.flags = up
Comme lxc-net utilise dnsmasq il est nécessaire de désactiver un autre serveur DNS, ici j’ai du désactiver bind9.
D’autre part lxc-net utilise dnsmasq mais il lui transfère un paramètre indésirable (-U dnsmasq) qui déclenche chez moi une erreur de dnsmasq, il m’ a donc fallu :
renommer « dnsmasq » en « dnsmasq_real », faire un script « dnsmasq » qui contient :
#!/bin/bash
#
# Faux dnsmasq pour analyser et filtrer les paramètres reçus
#
# ------------------------------------------------------------------------------
shift
shift
/usr/sbin/dnsmasq_real $*
Afin d’éliminer les deux paramètres superflus. Une fois cette « manip » réalisée dnsmasq est bien présent comme le montre un "ps" après un reboot et l’adresse de mon pont « br2 » est bien celle attendue.
On va pouvoir passer à la suite.
LXC : test première instance
LXC : test première instance jppAssurons nous d'abord que notre instance est bien configurée :
| lxc-ls -f NAME STATE AUTOSTART GROUPS IPV4 IPV6 UNPRIVILEGED debian-a STOPPED 0 - - - false |
L’instance est bien là et stoppée, essayons de la démarrer et de nous y connecter :
| lxc-start debian-a lxc-attach debian-a root@debian-a:/# ls -al total 56 drwxr-xr-x 18 root root 4096 avril 12 14:26 . drwxr-xr-x 18 root root 4096 avril 12 14:26 .. lrwxrwxrwx 1 root root 7 avril 6 16:18 bin -> usr/bin drwxr-xr-x 2 root root 4096 févr. 1 17:09 boot drwxr-xr-x 7 root root 520 avril 12 14:26 dev drwxr-xr-x 51 root root 4096 avril 10 22:58 etc ...... drwxr-xr-x 2 root root 4096 avril 6 16:18 opt dr-xr-xr-x 301 root root 0 avril 12 14:26 proc drwx------ 3 root root 4096 avril 10 22:58 root drwxr-xr-x 11 root root 340 avril 12 14:27 run lrwxrwxrwx 1 root root 8 avril 6 16:18 sbin -> usr/sbin drwxr-xr-x 2 root root 4096 avril 6 17:00 selinux drwxr-xr-x 2 root root 4096 avril 6 16:18 srv dr-xr-xr-x 12 root root 0 avril 12 14:26 sys drwxrwxrwt 7 root root 4096 avril 12 14:27 tmp drwxr-xr-x 13 root root 4096 avril 6 16:18 usr drwxr-xr-x 11 root root 4096 avril 6 16:18 var |
Cette instance ressemble bel et bien à une machine standard, voyons pour la partie réseau :
|
root@debian-a:/# ifconfig lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 |
Là aussi tout semble correct, faisons un tout petit test (ssh sur une autre machine physique du réseau) :
|
ssh root@xxxxxxxxx Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. |
C’est OK, le réseau marche … essayons de faire la mise à jour du système puisque /etc/apt/sources/list a l’air correct :
| root@debian-a# apt-get update Get:1 http://security.debian.org stable/updates InRelease [65,4 kB] Get:2 http://deb.debian.org/debian stable InRelease [122 kB] Get:3 http://deb.debian.org/debian stable/main amd64 Packages [7 907 kB] Get:4 http://security.debian.org stable/updates/main amd64 Packages [187 kB] Get:5 http://security.debian.org stable/updates/main Translation-en [100 kB] Get:6 http://deb.debian.org/debian stable/main Translation-en [5 970 kB] Get:7 http://deb.debian.org/debian stable/main Translation-fr [2 478 kB] Fetched 16,8 MB in 3s (6 103 kB/s) Reading package lists... Done |
Tout est donc OK, cette instance semble parfaitement fonctionnelle et occupe #686Mo sur disque.
On peut s'y connecter en ssh (il faut fixer un nouveau mot se passe "root", lxc-attach vous connecte par ssh en "root) comme sur n'importe quelle autre machine :
|
ssh root@192.168.3.11 The programs included with the Debian GNU/Linux system are free software; Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent |
Mais elle n'est pas très sécurisée car elle fonctionne avec les droits "root" ce qui n'est pas forcément le plus judicieux et que d'autre part rien ne l'empêche de monopoliser l'ensemble de la mémoire, du CPU des IO ...
Si on utilise la commande "top" la mémoire disponible est celle de la machine pĥysique sous-jacente, "cat /proc/meminfo" donne bien l'intégralité de la mémoire physique.
De même "df" montre l'intégralité du disque contenant le répertoire /var/lib/lxc.
Il reste donc encore des choses à faire pour rendre les choses plus sûres et maîtrisables.
Un conteneur non privilégié
Un conteneur non privilégié jppInitialisation d'un conteneur non privilégié :
Comme la plupart des "templates" ne permettent pas de charger des images utilisables en mode non-privilégié il est recommandé d'utiliser le template "download".
Celui-ci nécessite quelques paramètres supplémentaires pour fonctionner en mode automatique. Si ces paramètres ne sont pas fourni le template vous demande les données en affichant pour chaque choix une liste des possibilités, la liste des distributions disponibles est impressionnante ...
Mais avant de créer le premier conteneur non privilégié il faut effectuer quelques mises à jour (utilisateur "testlxc" créé pour la circonstance) :
- Créer un répertoire pour stocker nos conteneurs, sinon ceux-ci seront créés dans .local/share/lxc. Ici j'ai créé un répertoire $HOME/VM/LXC, volontairement en deuxième niveau en dessous de $HOME.
- Créer le fichier /etc/lxc/lxc-usernet contenant :
# user type_de_réseau pont nombre
testlxc veth br2 10
- Créer le répertoire $HOME/.config/LXC
- Créer dans ce répertoire un fichier "lxc.conf" contenant :
lxc.lxcpath = /home/testlxc/VM/LXC
lxc.default_config = /home/testlxc/.config/lxc/default.conf
- Créer un fichier "default.conf" contenant :
lxc.apparmor.profile = generated
lxc.apparmor.allow_nesting = 1
###
lxc.idmap = u 0 296608 65536
lxc.idmap = g 0 296608 65536
Ces valeurs sont issues de :
grep testlxc /etc/subuid (pour la ligne "u")
grep testlxc /etc/subgid (pour la ligne "g")
Ouf, c'est fini pour la configuration.
Pour les tests j'ai utilisé un script (TC) avec log détaillé dans un fichier, surtout pour les premiers tests :
LOGPRI=DEBUG
TEMPLATE=download
NOM=debian-d
LOTG=" --logfile=/dev/stdout --logpriority=${LOGPRI} "
COMPL=' -- --dist debian --release buster --arch amd64 '
REP=' -P /home/testlxc/VM/LXC/'
lxc-create -n ${NOM} ${REP} -t ${TEMPLATE} ${LOG} ${COMPL} 2>&1 | tee TC.LOG
Et on exécute notre script :
./TC
No such file or directory - Failed to open tty
No such file or directory - Failed to open tty
Using image from local cache
Unpacking the rootfs
.....
You just created a Debian buster amd64 (20200419_05:24) container.
To enable SSH, run: apt install openssh-server
No default root or user password are set by LXC.
Les deux "No such file..." n'ont pas l'air de gêner ...
On va voir de qui se passe dans ce nouveau conteneur :
lxc-start debian-d
lxc-attach debian-d
root@debian-d:/# ls -al
total 68
drwxr-xr-x 21 root root 4096 Apr 19 05:29 .
drwxr-xr-x 21 root root 4096 Apr 19 05:29 ..
drwxr-xr-x 2 root root 4096 Apr 19 05:27 bin
drwxr-xr-x 2 root root 4096 Feb 1 17:09 boot
drwxr-xr-x 6 root root 500 Apr 20 11:43 dev
drwxr-xr-x 40 root root 4096 Apr 20 11:43 etc
drwxr-xr-x 2 root root 4096 Feb 1 17:09 home
drwxr-xr-x 10 root root 4096 Apr 19 05:26 lib
drwxr-xr-x 2 root root 4096 Apr 19 05:25 lib64
....
drwxr-xr-x 2 root root 4096 Apr 19 05:25 srv
dr-xr-xr-x 12 nobody nogroup 0 Apr 20 11:43 sys
drwxrwxrwt 7 root root 4096 Apr 20 11:43 tmp
drwxr-xr-x 10 root root 4096 Apr 19 05:25 usr
drwxr-xr-x 11 root root 4096 Apr 19 05:25 var
Ceci ressemble bien au contenu d'une machine réelle.
On personnalise rapidement le mot de passe de "root" afin de sécuriser un peu ce conteneur.
on en sort par "exit" puis "lxc-stop debian-d" ou par :
"systemctl poweroff" plus court !
Maintenant il reste à connecter notre machine au réseau ...
Non privilégié avec réseau
Non privilégié avec réseau jppConnecter le conteneur au réseau.
Cette action doit être réalisée conteneur stoppé.
Il faut compléter le fichier "config" de notre conteneur avec les éléments liés au réseau, on utilise ici le même pont que pour le premier conteneur (accessible en "br2") :
lxc.net.0.type = veth
lxc.net.0.link = br2
lxc.net.0.name = eth0
lxc.net.0.ipv4.address = 192.168.3.12/24
lxc.net.0.ipv4.gateway = 192.168.3.1
lxc.net.0.flags = up
On relance le tout et on regarde :
~$ lxc-start debian-d
~$ lxc-attach debian-d
root@debian-d:/# netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
0.0.0.0 192.168.3.1 0.0.0.0 UG 0 0 0 eth0
192.168.3.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
La commande "ping" ne fait pas partie de l'image (bizarre, vous avez dit bizarre?), comme c'est une commande "simple" il suffit de la copier depuis la machine "maître" qui est aussi une Debian Buster (en "root") :
cp /bin/ping /home/testlxc/VM/LXC/debian-d/rootfs/bin
Et dans le conteneur ça marche :
ping -c1 google.fr
PING google.fr (216.58.213.131) 56(84) bytes of data.
64 bytes from par21s03-in-f131.1e100.net (216.58.213.131): icmp_seq=1 ttl=52 time=5.31 ms
Il y a bien du réseau dans ce conteneur, on va y installer un serveur ssh comme proposé lors de la création du conteneur :
apt-get update --> fonctionne très bien
apt-get install openssh-server
.....
Creating config file /etc/ssh/sshd_config with new version
Creating SSH2 RSA key; this may take some time ...
2048 SHA256:jd2wgb/fFjgQZL1bXr9KHu2aK1eA8+6r0G0dx+Rro4c root@debian-d (RSA)
Creating SSH2 ECDSA key; this may take some time ...
256 SHA256:Lr1fp1Ov0PBVG+q0oOs8v5PMaBOh105kXA7rp3Ri9Wg root@debian-d (ECDSA)
Creating SSH2 ED25519 key; this may take some time ...
256 SHA256:+74AKYdcsTI+0Nz/V3YEdo1CBnPC89JY74rKhkkcGE8 root@debian-d (ED25519)
Created symlink /etc/systemd/system/sshd.service → /lib/systemd/system/ssh.service.
Created symlink /etc/systemd/system/multi-user.target.wants/ssh.service → /lib/systemd/system/ssh.service.
rescue-ssh.target is a disabled or a static unit, not starting it.
Processing triggers for systemd (241-7~deb10u3) ...
Processing triggers for libc-bin (2.28-10) ...
Tout est donc pour le mieux.
Après une petite modification dans /etc/ssh/sshd_config pour autoriser la connexion de "root" et un redémarrage du service sshd il est possible de se connecter en ssh dans notre conteneur :
ssh root@192.168.3.12
root@192.168.3.12's password:
Linux debian-d 5.6.4 #3 SMP Sat Apr 18 15:53:49 CEST 2020 x86_64
...
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
Last login: Mon Apr 20 15:57:58 2020 from 192.168.3.1
root@debian-d:~#
Comme vous pourrez le constater ce conteneur n'a pas de limites, il peut "bouffer" toute la mémoire et occuper autant de CPU qu'il lui plait, truster toutes les IO ...
Il va falloir lui donner des limites à ne pas franchir afin de laisser des possibilités pour d'autres conteneurs ...
LXC : Non privilégie et sécurisé
LXC : Non privilégie et sécurisé jppLXC : Il est nécessaire de sécuriser un peu ce conteneur en limitant ses possibilités :
- Mémoire
- Cpu
- IO, pour cela on verra un peu plus tard.
Mais ce n'est pas une mince affaire de gérer les "cgroups" à travers LXC car il existe pas mal de contraintes dont la plupart doivent être levées au niveau du système.
Les tests sont donc assez longs et j'ai du passer un temps assez long avant de rédiger la suite de cet article ... le temps de consulter pas mal de documents et de faire quelques tests.
Limiter la mémoire
Limiter la mémoire jppLimiter la mémoire utilisable par une instance LXC.
Note : la machine physique de test dispose de 16Go de RAM et de 8Go de Swap, elle fonctionne avec un kernel très récent (à l'époque) : 5.6.7, quasiment le dernier sorti à ce jour.
Sans aucune limitation l'instance LXC dispose de l'intégralité de la mémoire de la machine physique, "free mem" montre :
total used free shared buff/cache available
Mem: 16363688 17616 16281500 8184 64572 16346072
Swap: 8811516 0 8811516
On voit bien 16Go de mémoire et un swap de 8Go.
Pour limiter la mémoire utilisable par notre container on met en place les paramètres suivants :
lxc.cgroup.memory.limit_in_bytes = 128M
lxc.cgroup.memory.memsw.limit_in_bytes = 192M
Après redémarrage du conteneur "free mem" donne alors :
total used free shared buff/cache available
Mem: 131072 12332 105408 8184 13332 118740
Swap: 196608 8 196600
Ce qui correspond bien aux paramètres fixés, la commande "lxc-info" est plus bavarde et donne plus de renseignements :
lxc-info debian-d
Name: debian-d
State: RUNNING
PID: 8280
IP: 192.168.3.12
Memory use: 36.44 MiB
KMem use: 7.50 MiB
Link: veth9SRIEJ
TX bytes: 7.89 KiB
RX bytes: 12.70 KiB
Total bytes: 20.59 KiB
Au passage une petite singularité : la variable "$HOME" de root n'est pas initialisée dans le conteneur mais se trouve ici égale à "/home/testlxc" (HOME de l'utilisateur qui a lancé l'instance). J'ai du installer dans .profile "export HOME=/root" et il faut en plus utiliser un "switch" lors du lancement de lxc-attach en ajoutant :
--clear-env. Comme par miracle on se retrouve alors avec une variable HOME correcte.
Ajuster la mémoire
Ajuster la mémoire drupadminSi l'on veut s'intéresser aux limitations concernant le CPU (en % et en nombre de CPU) il va falloir donner à notre utilisateur quelques droits supplémentaires sur les CGROUPS.
En effet, par défaut (sur une Debian Buster), seuls les droits sur "freezer" et "memory" sont attribués aux utilisateurs il faut donc ajouter les droits sur "cpu","cpuset" et "cpuacct" pour pouvoir "jouer" avec les paramètres "cpu".
Il faut corriger un fichier de PAM qui permet d'attribuer ces droits : /etc/pam.d/common-session :
Ligne originale :
session optional pam_cgfs.so -c freezer,memory,name=systemd
Ligne corrigée :
session optional pam_cgfs.so -c freezer,memory,cpu,cpuset,cpuacct,blkio,name=systemd
Après reconnection de notre utilisateur "testlxc", vérifier quels cgroups sont "autorisés" avec :
cat /proc/self/cgroup | grep testlxc
10:cpuset:/user/testlxc/0
9:blkio:/user/testlxc/0
8:freezer:/user/testlxc/0
4:cpu,cpuacct:/user/testlxc/0
Le "grep testlxc" est à adapter en fonction de votre utilisateur et cela évite des lignes inutiles ...
Note j'ai ajouté "blkio" qui sera utilisable plus tard ...
Autre "bizarrerie" découverte lors de ce test :
La commande "df" renvoie la taille du disque physique porteur du "rootfs" et non la taille du "rootfs" lui même, on n'est pas dans une machine virtuelle !
J'ai installé Apache/Php/Opcache dans ce conteneur et j'ai quelque peu bataillé avec la mémoire partagée : il faut mettre de "bons" paramètres (kernel.shm...) :
- Dans notre conteneur
local.conf:kernel.shmmax = 34359738368
local.conf:kernel.shmall = 131072
local.conf:kernel.shmmni = 65536
- . Mais aussi dans la machine physique
local.conf:kernel.shmmax = 34359738368
local.conf:kernel.shmall = 536870912
local.conf:kernel.shmmni = 65536
afin de permettre à Opcache d'initialiser la mémoire nécessaire.
Paramètres ajustés dans le fichier "config":
# limiter mémoire
lxc.cgroup.memory.limit_in_bytes = 384M
lxc.cgroup.memory.memsw.limit_in_bytes = 640M
Les valeurs données ci-dessus sont indicatives .. mais elles ont fonctionné pour moi et Apache a pu démarrer avec Opcache.
Après ces quelques ajustements le site est accessible normalement de l'extérieur ... et les performances sont aussi bonnes que sur la machine physique.
Ajuster la mémoire
Ajuster la mémoire jppSi l'on veut s'intéresser aux limitations concernant le CPU (en % et en nombre de CPU) il va falloir donner à notre utilisateur quelques droits supplémentaires sur les CGROUPS.
En effet, par défaut (sur une Debian Buster), seuls les droits sur "freezer" et "memory" sont attribués aux utilisateurs il faut donc ajouter les droits sur "cpu","cpuset" et "cpuacct" pour pouvoir "jouer" avec les paramètres "cpu".
Il faut corriger un fichier de PAM qui permet d'attribuer ces droits : /etc/pam.d/common-session :
Ligne originale :
session optional pam_cgfs.so -c freezer,memory,name=systemd
Ligne corrigée :
session optional pam_cgfs.so -c freezer,memory,cpu,cpuset,cpuacct,blkio,name=systemd
Après reconnection de notre utilisateur "testlxc", vérifier quels cgroups sont "autorisés" avec :
cat /proc/self/cgroup | grep testlxc
10:cpuset:/user/testlxc/0
9:blkio:/user/testlxc/0
8:freezer:/user/testlxc/0
4:cpu,cpuacct:/user/testlxc/0
Le "grep testlxc" est à adapter en fonction de votre utilisateur et cela évite des lignes inutiles ...
Note j'ai ajouté "blkio" qui sera utilisable plus tard ...
Autre "bizarrerie" découverte lors de ce test :
La commande "df" renvoie la taille du disque physique porteur du "rootfs" et non la taille du "rootfs" lui même, on n'est pas dans une machine virtuelle !
J'ai installé Apache/Php/Opcache dans ce conteneur et j'ai quelque peu bataillé avec la mémoire partagée : il faut mettre de "bons" paramètres (kernel.shm...) :
- Dans notre conteneur
local.conf:kernel.shmmax = 34359738368
local.conf:kernel.shmall = 131072
local.conf:kernel.shmmni = 65536
- . Mais aussi dans la machine physique
local.conf:kernel.shmmax = 34359738368
local.conf:kernel.shmall = 536870912
local.conf:kernel.shmmni = 65536
afin de permettre à Opcache d'initialiser la mémoire nécessaire.
Paramètres ajustés dans le fichier "config":
# limiter mémoire
lxc.cgroup.memory.limit_in_bytes = 384M
lxc.cgroup.memory.memsw.limit_in_bytes = 640M
Les valeurs données ci-dessus sont indicatives .. mais elles ont fonctionné pour moi et Apache a pu démarrer avec Opcache.
Après ces quelques ajustements le site est accessible normalement de l'extérieur ... et les performances sont aussi bonnes que sur la machine physique.
Limiter les IO
Limiter les IO jppLa limitation des IO pose quelques problèmes pour les conteneurs non privilégiés, mais quelques pistes se dessinent.
Après pas mal de recherches et tests je me suis décidé à créer un conteneur MariaDB avec une limitation sur l'essentiel des caractéristiques soit les IO.
Ce container MariaDB/Mysql complétera le serveur Web de l'article précédent.
Le container est configuré avec 512M de mémoire et 768M (512M + 256M de swap) et un "disque" externe sous forme d'un répertoire contenant deux sous répertoires "data" et "binlog", le "error.log" restera dans le /var/log/mysql du conteneur. Il faut donc quelque peu corriger le fichier de configuration de MariaDB pour ne pas mettre les données dans /var/lib/mysql ou /var/log/mysql.
J'ai voulu utiliser le paramétrage "blkio.weight" mais celui-ci nécessite de disposer au niveau du système du scheduler d'IO CFQ qui n'est plus disponible dans les noyaux récents ???
De toutes les façons aucun fichier contenant "weight" n'est visible dans la hiérarchie des cgroups, vérification :
cd /sys/fs/cgroup
find ./ -name '*weight*'
ne ramène rien,
donc aucun "Cgroup" avec "weight" n'existe ... Le paramètre "weight" (10 .. 1000) qui est censé définir la répartition entre les IO de différents conteneurs semble inutilisable.
Les seuls paramètres sur lesquels on peut agir sont ceux définissant la vitesse max autorisée :
. blkio.throttle.read_bps_device
. blkio.throttle.read_iops_device
. blkio.throttle.write_bps_device
. blkio.throttle.write_iops_device
On peut donc limiter les IO en IOPS ou en octets pas seconde, c'est déjà pas mal ... Mais quelle est la syntaxe exacte pour lxc ?
La syntaxe (évidente, si l'on a déjà pratiqué LXC) ne fonctionne malheureusement que pour les conteneurs privilégiés :
lxc.cgroup.blkio.throttle.read_bps_device = 8:0 50
8:0 car il s'agit pour moi du disque /dev/sda, on peut voir les valeurs avec :
ls -al /dev/sda
brw-rw---- 1 root disk 8, 0 mai 5 18:07 /dev/sda
J'ai trouvé ceci après un examen des logs de la commande "lxc-start" en mode "DEBUG" qui signale des "denied" depuis le programme "cgfsng.c". Pour autoriser les commandes "blkio.throttle...device" en mode non-privilégié il faut, encore, aller modifier le fichier /etc/pam.d/common-session et ajouter une autorisation. Cette ligne devient alors :
session optional pam_cgfs.so -c freezer,memory,cpu,cpuset,cpuacct,blkio,cgfsng,name=systemd
Et après avoir avoir fermé et ré-ouvert la session de mon utilisateur "testlxc" le conteneur démarre avec les limites suivantes :
# limiter IO
lxc.cgroup.blkio.throttle.read_bps_device = 8:0 50000
lxc.cgroup.blkio.throttle.write_iops_device = 8:0 50000
et les bonnes valeurs sont inscrites dans les fichiers correspondants.
Contrôle :
cd /sys/fs/cgroup/blkio/user/testlxc/0/lxc/debian-e
cat *device
8:0 50
8:0 50
La limite à 50000 est volontairement extrêmement faible pour voir une instance sérieusement ralentie.
C'est le cas,
- à 50000 le démarrage et l'arrêt du conteneur sont très ralentis, des accès à la base MariaDB sont très poussifs voire interminables ...
- Au delà de 500000 les choses s'améliorent très sérieusement, démarrage rapide, accès à la base MariaDB rapides ...
Il semble par ailleurs que la limitation soit effective sur les accès "physiques" au disque mais ne touche pas les accès à des données dans les caches. C'est visible en "droppant les caches" sur le système physique, un simple "ls -al" demande du temps la première fois mais est instantané par la suite.
En résumé la limitation joue au niveau des IO "physiques" mais ne bride pas le conteneur pour les accès depuis le cache ce qui garantit un certain niveau de performance tout en permettant de mieux maîtriser la concurrence entre conteneurs pour les accès physiques.
Tests sur limitation IO
Tests sur limitation IO jppRien ne vaut quelques exemples chiffrés pour mieux voir l'influence d'un paramètre.
Les comptages sont effectués sur 3 tables de #30800 rangs, la table (1) utilise 24Mo, la table (2) 29MO, la table (3) environ 16Mo et la table (4) de 976000 rangs et 5 partitions de #130Mo. Le chargement des tables a été fait avec une vitesse de 2MO/s
Le filesystem est installé sur un RAID de disques HDD "classiques".
Mariadb est réglé avec :
query_cache_type = 0
query_cache_limit = 0
query_cache_size = 0
innodb_buffer_pool_dump_at_shutdown = 0
innodb_buffer_pool_load_at_startup = 0
Pour chaque valeur de lxc.cgroup.blkio.throttle.read_bps_device les tests ont été effectués avec des comptages simples (select count(*)) sur les différentes tables. La deuxième série de chaque test a été effectuée après :
- "echo 3 > /proc/sys/vm/drop_caches" sur la machine physique
- systemctl restart mariadb
afin de limiter l'influence des caches du système et de MariaDB.
Les tests ont été effectués pour des valeurs de "blkio.throttle... bps_device" de 100 000 à 100 000 000 et sont résumés dans les tableaux suivants :
| 100 000 BPS | ||
| 1 | 19,384 | |
| 2 | Infini ... | |
| 3 | non testé | |
| 4 | non testé | |
Avec cette valeur très faible le fonctionnement n'est pas possible, tout est beaucoup trop lent.
| 200 000 BPS | ||
| 1 | 46,618 | 44,958 |
| 2 | 102,426 | 102,560 |
| 3 | 41,208 | 41,288 |
| 4 | 283,057 | 282,193 |
| 500 000 BPS | ||
| 1 | 14,614 | 12,223 |
| 2 | 41,132 | 42,069 |
| 3 | 16,441 | 16,605 |
| 4 | 113,378 | 112,617 |
| 1 000 000 BPS | ||
| 1 | 0,519 | 0,518 |
| 2 | 20,586 | 20,586 |
| 3 | 8,209 | 8,209 |
| 4 | 57,419 | 56,300 |
| 2 500 000 BPS | ||
| 1 | 0,212 | 0,211 |
| 2 | 8,196 | 8,200 |
| 3 | 3,303 | 3,300 |
| 4 | 22,505 | 22,505 |
| 5 000 000 BPS | ||
| 1 | 0,151 | 0,153 |
| 2 | 6,096 | 6,099 |
| 3 | 1,999 | 1,998 |
| 4 | 11,364 | 11,312 |
| 10 000 000 BPS | ||
| 1 | 0,119 | 0,116 |
| 2 | 4,091 | 4,098 |
| 3 | 1,599 | 1,598 |
| 4 | 11,315 | 12,512 |
| 25 000 000 BPS | ||
| 1 | 0,043 | 0,042 |
| 2 | 0,799 | 0,782 |
| 3 | 0,300 | 0,299 |
| 4 | 3,006 | 2,917 |
| 100 000 000 BPS | ||
| 1 | 0,041 | 0,040 |
| 2 | 0,219 | 0,215 |
| 3 | 0,095 | 0,096 |
| 4 | 2,841 | 2,941 |
Pour référence même test sur la machine de référence (CoreI5 a 3,5GHz avec 16GO de RAM) avec un réglage de MariaDB beaucoup plus "offensif" (innodb_buffer_cache 4096Mo ... et disques SSD) :
| REFERENCE | |
| 1 | 0,020 |
| 2 | 0,160 |
| 3 | 0,060 |
| 4 | 0,250 |
A partir de 5 millions BPS on trouve un fonctionnement exploitable.
LXC : test site web
LXC : test site web jppUtiliser LXC avec Apache + MariaDB.
Sur mes deux conteneurs LXC 1 et 2 j'ai installé ce qui suit :
1) Apache2 + Opcache (448Mo RAM/ 640Mo RAM+SWAP), sur le CPU 3.
Installation d'une copie du site ...
Configuration du site pour Apache en HTTPS, y compris une installation des clefs SSL du site réel, cela me signalera une erreur lors de l'accès puisque le nom de site est modifié.
Reconfiguration de l'accès à la base de données vers ma deuxième instance de machine LXC dédiée à MariaDB.
2) Mariadb (512Mo RAM / 768Mo RAM+SWAP) sur le CPU 2
Installation d'une copie de la base du site et création d'un user adéquat.
Après quelques ajustements l'accès au site est correct (sauf erreur SSL signalée comme prévu), mais on peut passer outre et cela n'influence pas le système de test adopté.
La machine dédiée au site "KVM" est, elle aussi, limitée aux CPU 2 et 3 (même machine) et possède 1536 Mo de RAM + 2Go de swap.
Premier test :
L'accès est apparemment aussi rapide que sur la version standard du site qui est installée dans une machine virtuelle KVM (Apache et MariaDB) avec 1536Go de mémoire et deux processeurs.
Tests comparés chiffrés.
Les tests ont été réalisés avec le programme "siege" paramétré comme suit :
- 7 users en parallèle
- Durée de 3 minutes
- Fichier de l'ensemble des pages du site extrait du fichier "sitemap.xml"
- Prise des mesures CPU sur la machine physique avec "sar" et quelques scripts de mise en forme, les graphes sont réalisés avec OpenOffice sur les données "sar" mises en forme par les scripts.
Les tests ont été réalisés deux fois pour chaque "site" :
- Premier test juste après démarrage
- Deuxième test peu après
Quelques résultats tirés de ces tests.
| Machine « KVM » | Machine « LXC » | |||||
| TEST 1 : après démarrage des machines | ||||||
| Transactions: | 38450 | hits | 67415 | hits | ||
| Availability: | 100.00 % | 100.00 % | ||||
| Elapsed | time: | 179.95 | time: | 179.69 | secs | |
| Data | transferred: | 537.99 | transferred: | 941.41 | MB | |
| Response | time: | 0.03 | time: | 0.02 | secs | |
| Transaction | rate: | 213.67 | rate: | 375.17 | trans/sec | |
| Throughput: | 2.99 | MB/sec | 5.24 | MB/sec | ||
| Concurrency: | 6.91 | 6.92 | ||||
| Successful | transactions: | 36335 | transactions: | 63621 | ||
| Failed | transactions: | 0 | transactions: | 0 | ||
| Longest | transaction: | 1.52 | transaction: | 2.98 | ||
| Shortest | transaction: | 0.00 | transaction: | 0.00 | ||
| TEST2 : à la suite du 1 | ||||||
| Transactions: | 53626 | hits | 68353 | hits | ||
| Availability: | 100.00 | % | 100.00 | % | ||
| Elapsed | time: | 179.21 | time: | 179.76 | secs | |
| Data | transferred: | 749.06 | transferred: | 954.27 | MB | |
| Response | time: | 0.02 | time: | 0.02 | secs | |
| Transaction | rate: | 299.24 | rate: | 380.25 | trans/sec | |
| Throughput: | 4.18 | MB/sec | 5.31 | MB/sec | ||
| Concurrency: | 6.85 | 6.92 | ||||
| Successful | transactions: | 50610 | transactions: | 64540 | ||
| Failed | transactions: | 0 | transactions: | 0 | ||
| Longest | transaction: | 2.19 | transaction: | 1.20 | ||
| Shortest | transaction: | 0.00 | transaction: | 0.00 | ||
J'aussi mesuré la consommation CPU lors de ces tests, et voici quelques graphes de consommation.
On peut remarquer une consommation du CPU 1 parfaitement parallèle à celle du CPU 2 qui est celui consacré à la base de données, après les lectures initiales la base fonctionne sur les caches, il s'agit donc probablement de la charge due aux IO initiales de la base de données.
Le CPU "Apache" est proche de 100%, celui de la base de données stagne à moins de 20% après un plateau à 40%.
Les deux CPU sont proches de 100% (mesure faite sur la machine physique).
On constate un "rendement" meilleur du site "LXC" dont la consommation CPU totale est inférieure et le débit assez nettement supérieur.