Mesures, monitoring
Mesures, monitoring jppLa sécurité des machines Linux (et des autres bien sûr) est un élément important qui ne doit jamais être négligé.
La sécurité ne s'improvise pas, cette préoccupation doit être présente en permanence à l'esprit du responsable/propriétaire d'une machine que ce soit un serveur « professionnel » ou une machine « amateur » connectée à Internet.
Premiers éléments les « logiciels »
Une machine est accessible par deux « entrées » principales :
- les services offerts
- les actions des utilisateurs
Chacun de ces éléments présente des risques spécifiques.
Les services offerts :
Tout service présente deux types de risque :
- Risque lié au logiciel lui même, peut-il « planter » en créant des dommages.
- Risque de « bug » dans le service permettant à une personne mal intentionnée d'exécuter des actions dommageables.
Toutefois dans la pratique ces deux risques peuvent être confondus. La première question
à se poser doit être : ce service est-il utile ? Tout logiciel peut présenter des risques, il faut donc s'assurer de la réputation d'un logiciel avant de l'installer :
- Le logiciel est-il activement maintenu ?
- Existe-t-il une liste des bugs connus ? Est-elle tenue à jour ?
- Existe-t-il une communauté ? Est-elle active (forum, mailing list) ?
- Les nouvelles versions et les correctifs sont-ils distribuées rapidement ?
- L'installation est-elle facilitée par une documentation ? Est-elle automatisée ?
- Quels sont les éléments de sécurité à prendre en compte lors de l'installation. Bien penser à ce problème car il existe encore des sites exploitant un serveur Apache utilisant le compte « root » !
Bien sûr cette recherche est un peu superflue pour certains logiciels très connus tels Apache ou PostgreSql.
Il est toujours bon de limiter au plus juste les services actifs sur une machine.
De même un « bon » paramétrage de chacun des logiciels peut apporter un peu plus de sécurité. Il est par exemple sécurisant d'interdire le login « root » par ssh.
Les actions des utilisateurs :
Tout utilisateur peut faire des erreurs, il faut donc limiter les « dégats » que chacun peut causer. Un premier niveau de sécurité est d'utiliser des logiciels « sûrs », un deuxième niveau est de ne permettre à chacun que les actions qu'il est autorisé à faire et les objets auxquels il peut accéder. La sécurité « standard » de Unix/Linux assurée par les utilisateurs et groupes permet déjà de limiter les dégâts. Un logiciel malicieux n'a (en principe) que les droits de celui qui l'utilise, vous ne travaillez jamais en « root » bien sûr ?
Accès au système :
On en arrive à la partie « mot de passe » qui est le dernier filtre pour les utilisateurs autorisés. Des « bons » mots de passe sont difficiles à instaurer car la résistance est forte et peu de personnes arrivent à se souvenir de mots de passe trop compliqués (qui peut se souvenir de plusieurs mots de passe tels que «#Zmqp4G5=q1&2 » ) qui en plus changent périodiquement ? Le risque de stockage des mots de passe sur des supports peu confidentiels (le petit papier collé à coté de l'écran) est important... Il est très difficile de trouver un « bon » compromis.
Il faut toutefois sensibiliser les utilisateurs à l'importance d'utiliser des mots de passe non significatifs suffisamment longs pour ne pas être trouvés facilement en « brute force ».
Ne pas oublier que une grande partie des ennuis provient de sources « intérieures » ( #80%?).
Internet :
L'accès à Internet est une belle chose, mais c'est aussi une porte ouverte sur le ( vilain? ) monde extérieur. Ici il ne faut pas appliquer le principe «tout le monde il est beau, tout le monde il est gentil ». Il vaut mieux appliquer le principe contraire et n'ouvrir que les accès nécessaires, un « bon » firewall ne gêne pas les accès légitimes mais interdit tous les autres.
Traduit en règles « IPTABLES » cela veut dire que les politiques par défaut doivent impérativement être « DROP » et que les autorisations d'entrée (règles INPUT), de transit (règles FORWARD), et même de sortie (règles OUTPUT) sont accordées en connaissance de cause.
Pour certains ports (par exemple ssh) on peut s'amuser à utiliser un logiciel tel que « knock » qui permet d'insérer dynamiquement une règle autorisant l'accès à un port spécifique (SSH par exemple) depuis l'adresse d'appel pour une durée courte (30 secondes c'est pas mal), cela évite d'avoir une liste imposante de « failed password » dans les logs de la machine puisque le port ssh est filtré à l'entrée.
Un petit outil permettant une analyse rapide du log du firewall se réalise rapidement à grand coups de « grep » si l'on a soigné les messages de log (-j LOG –log-prefix 'un_message_descriptif').
Une surveillance des ports ouverts peut être un plus (j'aime bien « lsof -Pn | grep TCP » ), un logiciel spécifique peut être utilisé (voir par exemple « TIGER »).
Système :
Éléments physiques :
Pour des machines professionnelles la machine elle même doit être sécurisée physiquement car une bonne manière de dérober des données est de « piquer » un disque, si on ne peut pas ouvrir le boîtier c'est beaucoup moins discret car il faut emporter le boîtier (cela est aussi valable pour les postes « clients » ou privés).
Pour les serveurs l'accès physique aux machines doit être limité au maximum et le boot sur un support externe doit être impossible (difficile !), par exemple avec un mot de passe BIOS, de même le montage de supports externes (qui a dit clef USB?) doit être interdit (on peut s'amuser avec les règles « UDEV »). En effet si l'on peut effectuer une copie d'une partition (ou répertoire) sur un support externe la confidentialité des données est illusoire.
Sécurité et confidentialité des données :
Un premier niveau de confidentialité doit être assuré par les droits d'accès (utilisateurs et groupes sous Unix/Linux) mais cela n'est pas forcément facile à gérer. Se rappeler quand même qu'un utilisateur peut appartenir à plusieurs groupes.
On peut assurer la confidentialité des données par l'utilisation d'un encodage (cryptage). Cela peut être fait au niveau d'un document mais aussi d'une partition cryptée, mais cela impose quelques contraintes, notamment au niveau des performances.
Le RAID c'est pas mal pour la sécurité physique (bien que j'ai vu des disques RAID détruits et inaccessibles) mais cela n'offre aucune sécurité contre la destruction ou la perte de données.
Sauvegardes :
Les sauvegardes sont une partie importante de la sécurité des données car elles permettent de récupérer des données détruites (volontairement ou non). Une base de données sur une partition «vérolée » n'est en général récupérable qu'à partir des sauvegardes et des logs (mis bien sûr en sécurité sur un autre support ou même sur une machine différente). Le prix des disques ayant beaucoup baissé la copie de données sur un autre support (ou même une autre machine si l'on en dispose) offre une sauvegarde rapide et fiable. De nombreux logiciels peuvent être utilisés pour remplir cette fonction (« RSYNC », « AMANDA » et divers logiciels de backup). Pour AMANDA voir l'article suivant.
Il vaut mieux pour gérer cela sans difficultés « ranger » ses données selon leur importance et/ou leur type dans des répertoires spécifiques faciles à identifier.
Je connais quelqu'un qui a perdu plusieurs années de photos numérique lors du crash d'un disque, avis aux amateurs de photos.
Éléments logiques :
Dans un ordinateur le « nerf de la guerre » c'est les programmes, il faut donc les protéger et les surveiller, un programme modifié ou ajouté peut être dangereux (voir utilisation de « TRIPWIRE » (pour la version libre), « AIDE » par exemple pour remplir cette fonction bien que leur paramétrage soit parfois délicat, le moins connu OSSEC, bien que à moitié libre peut aussi être considéré).
Il faut, au minimum, surveiller les répertoires « bin », « sbin » , « lib » , une surveillance de « etc » n'est pas un luxe car certains paramètres et scripts (vous avez dit /etc/init.d ou /etc/hosts.allow ?) peuvent être critiques.
La mise à jour des programmes doit être effectuée par des personnes qualifiées et disposant des droits adéquats (personne ne travaille en permanence comme « root » n'est-ce pas ?).
Si possible les actions doivent être tracées (« sudo » c'est pas mal pour cela).
Si le système et les logiciels doivent être tenus à jour, sur une machine professionnelle il vaut mieux réaliser des tests auparavant afin de s'assurer des incompatibilités éventuelles. Je me souviens d'une société ayant installé sans tests et automatiquement une mise à jour du système qui a bloqué son principal logiciel de gestion … avec un coût non négligeable.
Une surveillance des logs système est intéressante (et indispensable dans un environnement professionnel), elle peut être aidée par l'utilisation de logiciels spécifiques (voir par exemple « LOGCHECK » qui dégrossit bien les choses, encore faut-il parcourir les mails qu'il vous envoie et effectuer les actions correctives nécessaires).
Un petit ajout à logcheck :
- Ajouter le fichier « auth.log » dans « /etc/logcheck/logcheck.logfiles »
- Créer un fichier « passwd » dans « /etc/logcheck/violations.d » qui ne contient que le mot « password », cela générera dans les rapports une partie spécifique sur les accès au système.
S'il y a beaucoup d'accès légitimes remplacer « password » par « Failed password » pour limiter la taille de la liste.
Un autre aspect de la sécurité/sureté est lié à la supervision des machines, il s'agit là de la sécurité de fonctionnement visant à limiter la durée des incidents en repérant rapidement le service fautif. Un crtain nombre d'outils existent dans le monde OpenSource dont le plus connu est probablement NAGIOS. Un nouveau concurrent "SHINKEN" très "Nagios Like" arrive et je vais tenter de le tester.
Et le petit dernier (testé) COLLECTD qui vous permet de mesurer les performances de vos matériels et logiciels sous forme de classiques graphes RRD, mais la palette des mesures est assez époustouflante.
Pour les outils liés au réseau voir "Securite".
Collectd
Collectd jppCOLLECTD est un logiciel qui permet de réaliser la collecte en continu d'informations sur le fonctionnement de vos machines.
Sous Debian l'installation est, comme d'habitude, très simple :
apt-get install collectd
L'ensemble se met immédiatement en route et commence son boulot de collecte.
Voyons voir maintenant comment on accède aux données, il existe un accès WEB (au moins dans le paquet Debian) présentant le graphes RRD pour lesquels COLLECTD enregistre les données. Il suffit de disposer d'un serveur WEB sur la machine et, pour Apache de créer le fichier "collectd.conf" dans le répertoire /etc/apache2/conf.d et d'y inclure :
| <IfModule mod_cgi.c> ScriptAlias /collectd /var/www/collectd/collection.cgi <Directory "/var/www/collectd"> Options Indexes +FollowSymLinks +ExecCGI Order allow,deny Allow from 192.168.2 </Directory> </IfModule> |
Il vous manquera probablement le module Perl "RRDs.pm" qu'il vous faudra installer, oui mais dans quel paquet est ce fichu module :
grep RRDs.pm Contents-amd64
usr/lib/perl5/RRDs.pm perl/librrds-perl
usr/share/perl5/Log/Log4perl/Appender/RRDs.pm perl/liblog-log4perl
Il faut donc installer le paquet librrds.perl :
apt-get install librrds-perl
remettra tout en ordre.
Il faudra ensuite créer un répertoire "collectd" dans "/var/www" et copier dans ce répertoire le script "collection.cgi" que vous trouverez dans "/usr/share/doc/collectd-core/examples".
Un petit coup de "service apache2 restart" et c'est OK la page Web est accessible.
La liste de plugins installés par défaut est déjà impressionnante :
- cpu, tous les indicateurs souhaitée
- df, mesure de l'espace disque
- disk, IO/s, octets/s
- entropy
- interface, erreurs et débit réseau
- irq
- load, les fameux chiffres sur 1, 5 et 15 minutes
- memory, utilisation de la mémoire par cache, buffers, programmes
- processes, en nombre
- users, là aussi en nombre
D'autres plugins sont disponibles pour suivre énormément de logiciels, mais comme ils nécessitent une certaine dose de paramétrage ils ne sont pas installés en standard.
COLLECTD : plugin DNS
COLLECTD : plugin DNS jppComme example d'installation, ou plutôt d'activation de l'un des plugins fournis voici la procédure de mise en route du plugin DNS.
Ce plugin permet, comme son nom l'indique, de suivre l'activité d'un serveur DNS en nombre de requêtes et en nombre d'octets.
Les fichiers de configuration se trouvent dans /etc, c'est la norme, répartis dans un fichier principal : "collectd.conf" et quelques fichiers "annexes" appelés par "Include" depuis le fichier principal.
On peut aussi activer un répertoire de fichiers complémentaires. Le fichier "collection.conf" a un autre rôle.
Un petit extrait du fichier "collectd.conf" :
#LoadPlugin curl_json #LoadPlugin curl_xml #LoadPlugin dbi LoadPlugin df LoadPlugin disk #LoadPlugin dns #LoadPlugin email LoadPlugin entropy #LoadPlugin exec #LoadPlugin filecount |
Il suffit de dé-commenter la ligne, ici "LoadPlugin dns" pour activer le plugin. Il faut aussi aller voir un peu plus loin dans le fichier le paramétrage de ce module :
| #<Plugin dns> # Interface "eth0" # IgnoreSource "192.168.0.1" # SelectNumericQueryTypes false #</Plugin> |
Là aussi il suffit d'enlever quelques "#" pour activer le paramétrage, et, en plus c'est directement adapté à mon petit réseau, le résultat : 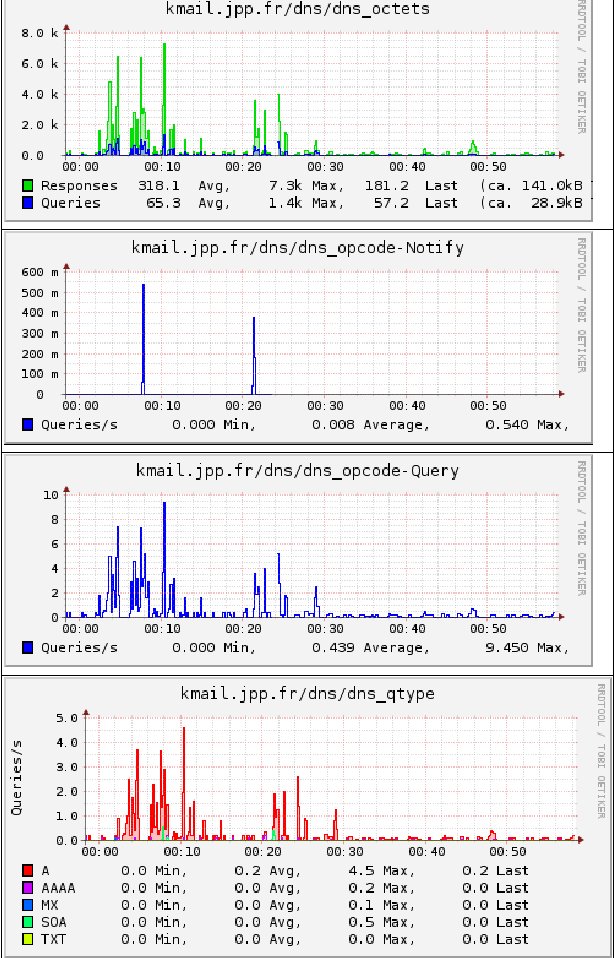
COLLECTD : quelques graphiques
COLLECTD : quelques graphiques jppJe vous présente ici quelques graphiques journaliers issus de COLLECTD, pour les graphes mensuels attendre un peu.
Le CPU 0 : 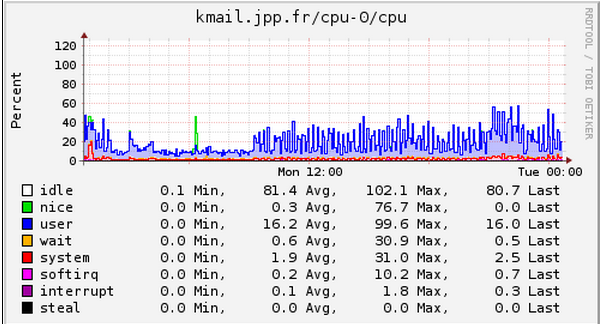
La mémoire au même moment : 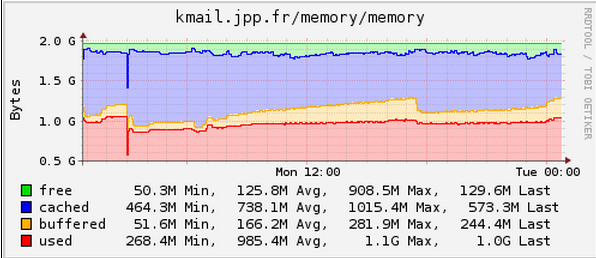
Le trafic réseau sur l'interface vers Internet : 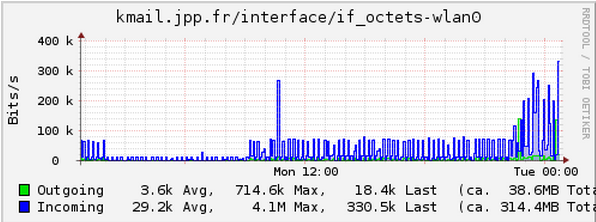
Le trafic DNS en octets : 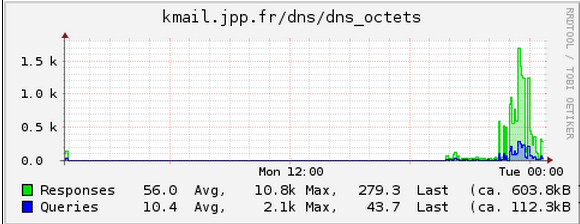
On voit bien ici l'activité le soir sur Internet.
Et pour finir l'activité d'un disque en octets : 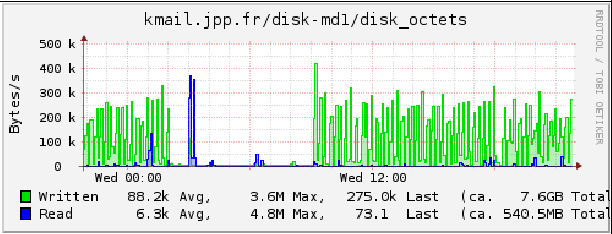
COLLECTD : centralisation des données
COLLECTD : centralisation des données jppSi vous surveillez plusieurs machines il est tentant de "centraliser" les données et l'interface web sur une seule machine.
Oui, Collectd le permet, il suffit d'activer et de paramétrer le plugin "network" sur la machine centralisatrice et sur les "clients".
Sur le "serveur" :
- Activer le plugin "network"
- Paramétrer le plugin "network" et remplir "correctement" le paramètre "Hostname"
| Plugin network> # server setup: Listen "192.168.2.2" "25826" ReportStats True SecurityLevel None MaxPacketSize 1512 </Plugin |
- Rédémarrer Collectd
Sur les clients :
- Activer le plugin "network"
- Remplir "correctement" le paramètre "Hostname"
| <Plugin network> # # client setup: Server "192.168.2.2" "25826" SecurityLevel None TimeToLive 128 </Plugin> |
Après redémarrage du service sur les postes clients tout doit être OK et de nouveaux répertoires apparaissent dans /var/lib/collectd/rrd.
Il existe des possibilités d'encodage et de sécurité au niveau de cette liaison, ici on s'est contenté de "SecurityLevel None".
Au niveau de l'interface WEB, j'ai installé "collectd-web" plus joli et fonctionnel que le script CGI fourni d'origine, toutes les machines apparaissent directement.
Ci dessous le paramétrage de collectd-web pour un serveur Apache :
|
<Directory /var/www/collectd-web> <Directory /var/www/collectd-web/cgi-bin> |
COLLECTD : interface web
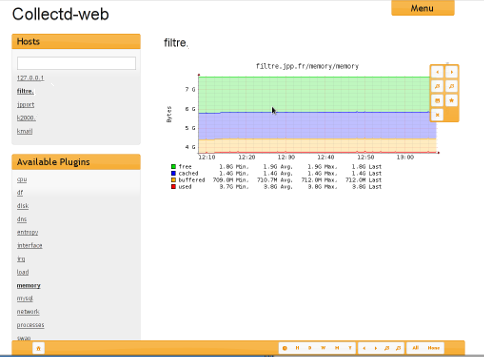
COLLECTD : interface web jppL'interface "collectd-web" permet une consultation aisée des données enregistrées sur votre serveur centralisé. Des gadgets permettent de régler la période de temps affichée, de la décaler dans le temps pour examiner plus précisément une période passée.
Cet interface est simple à installer et assez agréable à utiliser.
Ci dessous un exemple d'affichage :
Shinken
Shinken jppNote 2017 : le projet a continué à évoluer et est actuellement en version 2.4.3, je l'utilise pour mes modestes besoins couplé à Thruk et Omeganoc.
Note fin 2017 : Omeganoc a "disparu" --> ( j'ai "perdu" cette page ! ) passage à InfluxDB/Grafana. 
Note 2022 : J'utilise toujours Shinken et je l'utilise aussi en mode professionnel pour la surveillance des performances de quelques bases de données Mysql/MariaDB.
C'est un projet récent qui se veut très compatible avec son aîné NAGIOS dont il permet de récupérer la plupart des fichiers de configuration, il permet aussi de se servir des nombreux "plugins" de Nagios pour réaliser les "basses besognes" de contrôle et se charger de la partie "noble" : ordonnancer les contrôles, interpréter les résultats, les stocker. SHINKEN ne s'occupe pas de la partie "affichage" des résultats et délègue cette tâche à d'autres outils dont deux sont fournis dans le "kit" d'installation. Quand on connaît la complexité des fichiers de paramétrage (au moins si on veut quelque structuration) c'est un gros plus.
Shinken est écrit en Python qui devient de plus en plus un standard dans l'écriture de logiciels pointus ne nécessitant pas une recherche de la performance absolue bien que Python ait l'air de bien se défendre de ce coté. Le logiciel, contrairement à NAGIOS, est écrit sous forme modulaire, plusieurs "modules" coopèrent pour réaliser l'ensemble des tâches.
Les modules de même type peuvent être définis en plusieurs exemplaires et disposés sur des machines physiquement différentes sous les ordres d'un "grand ordonnateur" qui distribue les tâches et permet de centraliser les résultats.
Cette architecture ouvre de grandes perspectives pour des environnements complexes avec plusieurs sites et un grand nombre de "cibles" potentielles à surveiller. Cela peut aussi permettre d'établir des systèmes tolérants aux pannes touchant l'un des modules. Je vais tester ce logiciel un peu en profondeur pour voir son fonctionnement et les avantages qu'il présente par rapport à son aîné.
Il me faut pour cela créer quelques machines virtuelles avec chacune quelques "services" permettant de disposer d'un environnement un peu "touffu". Je vais aussi établir et un paramétrage Nagios correct pour cet ensemble. Cela permettra de tester les apports de ce nouveau produit qui semble prometteur. A bientôt pour une présentation plus détaillée de la version 0.1, c'est visiblement une version expérimentale mais qui semble néanmoins fonctionnelle ...
Un petit retard à cause d'une machine en panne (carte mère HS ?) et c'est le réceptacle physique de mes machines virtuelles ...
Je viens de récupérer la version 0.3 que je vais m'empresser d'installer dès que mon petit serveur de machines virtuelles daignera re-fonctionner. J'ai la carte mère et tout ce qu'il faut pour le remettre en fonction. Ce qui manque le plus est le temps car le boulot m'occupe pas mal et j'y ai retrouvé avec plaisir le travail avec des bases INGRES, cela change un peu de ORACLE ...
Shinken : version 0.1
Shinken : version 0.1 jppTests de la version 0.1.
Le test a été réalisé en téléchargeant depuis le site une image de machine virtuelle VMWARE que j'ai du convertir en image "XEN" afin de pouvoir l'installer dans le système adéquat.
Le paramétrage mis au point pour NAGIOS et "bêtement" repris ne fonctionne pas et déclenche un bon paquet d'erreurs ... et certaines options de configuration ne sont pas implémentées (ou ne fonctionnent pas ??), par exemple l'option "cfg_dir" qui permet d'indiquer un répertoire complet à prendre en compte dans le paramétrage.
Mon modèle était construit sur cette possibilité :
- Un répertoire pour chaque type d'objet.
- Un fichier par objet (host, service, administrateur .....
J'aime bien ce style de paramétrage car on peut ainsi éviter de toucher à des paramètres "qui marchent" et si après une mise à jour quelque chose va de travers l'erreur ne peut être que dans le fichier modifié et celà facilite la gestion du paramétrage dans un système de gestion de configuration (CVS, SVN, GIT .... selon vos préférencesi)
Les tests avancent, bien que les interfaces WEB fournies ( THRUK et NINJA) ne semblent pas toujours fonctionner correctement. Notamment le statut du dernier test n'est pas toujours visible et des service stoppés restent au vert ... est-ce du aux interfaces ou à Shinken lui même ?
Mystère, il va falloir investiguer sérieusement.
Premières pistes d'investigation :
Il semble que les tests soient bien réalisés par Shinken, son fichier de status est bien mis à jour et a bien l'air de refléter le résultat des tests. Un service stoppé apparaît bien comme stoppé et s'il redémarre son statut est modifié de manière correcte.
Les deux interfaces fournis (THRUK et NINJA) ne semblent pas bien recevoir (ou interpréter) les changements.
THRUK a l'air d'avoir bien du mal à retrouver l'état des HOSTS, sauf s'ils sont KO, ils apparaissent alors en rouge. Les hosts actifs restent en état "pending" (un gris terne, pas de beau vert), l'affichage des services, lui, est impeccable. J'ai récupéré une version plus récente (0.66) mais je dois encore voir comment l'installer. Le premier essai n'a pas fonctionné et les logs me signalaient un problème avec "Catalyst". N'étant pas un grand fervent de PERL j'ai du mal à trouver le problème et je suis revenu à la version 0.62. Il lance désespérement un message "Argument "" isn't numeric in numeric gt (>) at /usr/local/shinken/Thruk-0.62/templates/status_detail.tt line 189"
NINJA lui, a du mal à récupérer les status des services ou des hosts, la colonne "Status Information" reste désespérement vide. Il faudrait là aussi que je tente de trouver une nouvelle version.
SHINKEN, j'utilise ici la version 0.1 de fin 2009 qui est la seule disponible à la date de début des tests en téléchargement sur le site.
Cette version ne semble pas bien alimenter le "plugin_status" pour les hosts actifs ce qui explique peut-être le mutisme de THRUK à leur sujet. J'ai par la suite trouvé (essais version 0.3) qu'il s'agissait en fait d'un problème de paramétrage du plugin alors que ces mêmes paramètres fonctionnent sur une machine "Nagios" d'un version assez ancienne, peut-être une mise à jour du plugin Nagios (négative dans mon cas !).
J'ai installé MYSQL-PROXY pour suivre la mise à jour de la base MYSQL utilisée par NINJA, je ne suis pas un fana du "DELETE/INSERT" qui ne simplifie pas les recherches et SHINKEN a l'air de transmettre des données correctes.
Un des avantages de SHINKEN est de pouvoir alimenter en données diverses applications externes par un système de plugins (conforme Nagios, Mysql, Oracle, ?).
Je n'ai actuellement pas beaucoup de temps (boulot !) et une machine en panne (carte mère ?) Cela ne favorise pas la recherche de la petite bête car la machine virtuelle est installée sur le zinzin en panne ... et il faut en plus que je classe mes photos de vacances ...
Tout ceci était valable pour la version 0.1, donc une version de développement, ici en fait plus une preuve de concept ou un prototype dont les bases fonctionnent montrant que les choix d'architecture sont corrects et que le choix du langage PYTHON n'est pas forcément une erreur pour ce type de produit où le "fonctionnel" est très important. Sur mon petit réseau de test (quelques machines et services), même en mettant au minimum les délais (vérification toutes les minutes environ) aucune charge perceptible sur la machine.
L'avantage du choix de PYTHON est une grande portabilité car il n'existe que peu de matériels où Python n'est pas présent.
Dès que la machine sera réparée je reprends les tests ...
Après quelques jours ...
Finalement la version 0.1 fonctionne correctement et permet de remplacer mon vieux Nagios sans aucun problème.
Mais ... la version 0.3 est disponible, je ne m'appesantirais pas plus sur cette version qui pourtant fonctionne.
Vive la version 0.3.
Shinken : version 0.3
Shinken : version 0.3 jppJ'ai d'abord essayé d'installer de manière standard la version 0.3 téléchargée depuis le site. L'installation en elle même s'est bien passée mais le lancement provoque une erreur du module ARBITER car il n'arrive pas à ouvrir le "egg" et dit : ce n'est pas un répertoire.
N'étant pas un spécialiste de Python ni versé dans les oeufs je n'ai pas pu déboguer ce problème. Il s'est avéré par la suite que la version était une version en cours d'évolution vers la version 0.4.
J'ai ensuite téléchargé l'image (VMWARE) d'une machine pré-installée. La conversion en image XEN a fort bien fonctionné.
La manipulation (http://wiki.xensource.com/xenwiki/VMDKImage) fonctionne parfaitement, après un :
qemu-img convert -f vmdk temporary_image.vmdk -O raw xen_compatible.img
on dispose d'une image Xénifiée (Xénisée ?) qui ne demande plus qu'un petit paramétrage pour démarrer.
Le premier lancement est réussi et les deux interfaces fournis (Thruk et Ninja) ont progressé en numéro de version et semblent OK.
Il faut maintenant essayer de réaliser une installation personnelle, un peu plus "standard" que tous les fichiers dans le HOME de SHINKEN, et surtout qui utilise un paramétrage un peu plus complet et qui répond à mes besoins (et possibilités, malgré la virtualisation je n'ai pas 100 serveurs !).
Après une petite remise en ordre des scripts (à mon goût) tout démarre et les tests vers mes petits "services" débutent. Les différents modules communiquent fort bien et font leur boulot très convenablement.
Un petit tour dans les interfaces graphiques, Thruk a une esthétique qui se rapproche de cette de Nagios, on est donc en pays de connaissance. Dans le cas de Ninja l'esthétique est radicalement différente mais semble offrir des fonctionnalités équivalentes.
Toutefois les "hosts" ne présentent pas de status valable, ils reflètent plus ou moins le status des services attachés. Il semble que les fonctions indépendantes de "check" liées aux hosts soient inopérantes ou désactivées, mais je n'ai encore trouvé aucun moyen de les réactiver.
Pourtant du coté du paramétrage des host il est bien indiqué une "check_command" qui, lancé à la main fonctionne normalement.
Une inspection rapide du fichier "status.dat" géré par Shinken montre que le statut des hosts ("plugin_output") n'est pas mis à jour, comment réactiver cette fonctionnalité pourtant essentielle ?
Après quelque recherches je me suis aperçu que la commande utilisée pour le "check" du host était mal paramétrée (niveau "warning" inférieur au niveau "critical" ! ). Un fois ceci réparé tout rentre dans l'ordre et tous les tests passent au vert. Par contre aucun message n'indiquait ce qui se passait réellement et cela marchait avec Nagios.
Je vais maintenant essayer une autre fonctionnalité qui est un des phares de ce logiciel : la facilité de déporter une partie des travaux sur une autre machine. Ici je vais tenter de contrôler un petit réseau complètement disjoint et constitué de 4 machines :
- Un "frontal" (Haproxy)
- Deux serveurs WEB Apache
- Un serveur de base de données Mysql alimentant les deux serveurs WEB
Le serveur frontal est le seul accessible "de l'extérieur", c'est donc lui qui va porter les éléments nécessaires et tester ainsi les possibilités des "royaumes" et de la distribution des modules.
Cette version m'a donné bien du fil à retordre car le "central" n'arrivait pas à contacter le "scheduler" distant. L'équipe de développement a été très efficace et après quelques ajustements de code tout est rentré dans l'ordre et communique avec discipline. Depuis la version 0.4 a été "libérée" et j'ai continué les tests avec celle-ci qui intègre toutes les modifications faites précédemment.
Ce n'est que le début, il faut maintenant ajuster les différents "hosts" et "services" sur ce nouveau réseau.
A suivre ...
... probablement dans un autre article car il va y avoir des tas de choses à dire.
Shinken : version 0.4
Shinken : version 0.4 jppAprès installation dans "/usr/local" la version 0.4 semble très stable. Au passage j'ai installé la version 0.72 de Thruk qui s'avère très agréable à l'usage, la nouveauté : les "realms" ou royaumes.
Comme déjà dit dans un article précédent l'esthétique de cet interface est très proche de celle de l'interface de Nagios, mais il s'avère que c'est plein de petits "plus" qui facilitent la vie.
La communication avec Shinken est impeccable, vous pouvez en quelques clics demander le rafraîchissement d'un service, d'un hôte, de tous les hôtes ...
Revenons-en à ma création de "royaume". Un royaume doit comporter 4 des 5 modules principaux : poller,broker,actionner et scheduler. La seule chose qui lui manque est un arbiter capable de gérer la description des hosts/services à surveiller.
Le paramétrage s'effectue donc principalement au niveau de l'arbiter sur la machine "centrale". Il faut indiquer à l'arbiter la création d'un "realm" et décrire les quatre modules liés à ce royaume. Il en sera de même dans les fichiers décrivant les hosts et les services.
Les fichiers de paramétrage sont présentés ci-dessous :
| define realm { realm_name testweb default 0 } |
D'abord le "realm" c'est la partie la plus simple, donner un nom et dire que ce n'est pas le royaume par défaut. |
| define scheduler{ scheduler_name scheduler-web address 192.168.1.120 port 7768 spare 0 weight 1 realm testweb } |
A tout seigneur, tout honneur, on commence par le maître des lieux, c'est lui qui contrôlera ce royaume pour y distribuer le boulot ... il doit être défini par un nom, une IP, un port, un poids (ici 1) le fait qu'il n'est pas un "spare" et l'appartenance au royaume "testweb". |
| define reactionner{ reactionner_name reactionner-web address 192.168.1.120 port 7769 spare 0 manage_sub_realms 0 min_workers 1 max_workers 5 polling_interval 3 realm testweb } |
Le même genre de définition nécessaire à la communication, nom; IP, port, royaume plus quelques paramètres propres :
|
| define broker{ broker_name broker-web address 192.168.1.120 port 7772 spare 0 modules Status-Dat, Simple-log, Livestatus # , ToMerlindb_Mysql manage_sub_realms 1 manage_arbiters 0 realm testweb } |
Toujours le même style de paramérage avec les paramètres spécifiques des "modules" à activer, ici je n'ai pas activé la liaison "Mysql" car la liaison est à faire avec un nouveau schéma de la base de données. Je vais essayer de voir avec les versions les plus récentes de Ninja. Pour le moment la liaison Mysql est inactivée. C'est pourtant la seule manière de centraliser les données issues du royaume. |
| define poller{ poller_name poller-web address 192.168.1.120 port 7771 manage_sub_realms 0 min_workers 2 max_workers 2 processes_by_worker 127 polling_interval 5 realm testweb } |
Encore le même paramétrage avec les spécifiques :
|
Du coté du serveur hébergeant notre "royaume" le paramétrage est beaucoup plus simple et peut être réalisé une fois pour toutes car cela se limite à un "bloc" de définitions pour chaque module. Les quatre fichiers ont d'ailleurs strictement la même syntaxe, je les ait nommes my_broker.ini, my_pollerd.ini, my_reactionnerd.ini et my_reactionnerd.ini. Le contenu est standard et corresponds à ceci :
[daemon]
#relative from this cfg file
workdir=/var/lib/shinken
pidfile=%(workdir)s/brokerd.pid
interval_poll=5
maxfd=1024
port=7772
host=0.0.0.0
user=shinken
group=shinken
idontcareaboutsecurity=no
Il faut bien sûr faire varier le fichier de "pid" et le port pour chacun des modules. Les ports sont un peu "standardisés" et il est plus simple d'utiliser toujours les mêmes :
- 7768 : scheduler
- 7769 : reactionner
- 7771 : poller
- 7772 : broker
Cela permet d'éviter de faire des "noeuds" difficiles à démonter.
Pour la description des "hôtes" il suffit d'y ajouter une ligen "realm testweb" et le tour est joué :
define host{
use generic-host
host_name xxxxxx
alias testweb_frontal
address xxxxxx
check_command check_ping!4.0,80%!10.0,80%!
realm testweb
max_check_attempts 3
notification_interval 1800
notification_period 24x7
notification_options d,u,r
register 1
}
Pour les services le standard est suffisant, ils suivent le sort de leur hôte :
define service {
use generic-HTTP
host_name xxxxxxxx
name HTTP-XXX
contact_groups virtuel
notification_interval 480
check_command check_http_auth!/index.php!user:password!
normal_check_interval 200
check_interval 10
}
Et le résultat me direz-vous ... et bien cela marche, et même fort bien dès que vous avez commencé à décrire quelques hôtes et services dans votre nouveau royaume.
Lorsque tout fonctionne vous voulez pouvoir suivre vos hosts/services en direct d'une seule et même console ... et cela marche, au moins avec THRUK, pour NINJA la version dont je dispose (fournie avec SHINKEN 0.3) ne fonctionne pas avec SHINKEN 0.4 car il faut une version plus récente et l'installation de Ninja suppose d'installer d'autres packages ... bref dans un premier temps je reste avec THRUK. Voir l'article suivant pour des précisions sur le paramétrage hosts + services et celui de Thruk.
Shinken : 0.4 + realm + Thruk
Shinken : 0.4 + realm + Thruk jppAprès avoir essuyé quelques plâtres, mais c'est normal pour une version "0.x", j'ai mis en place la version 0.4 (stable) dont les fonctions semblent stables et efficaces.
Le paramétrage réponds maintenant à mes goûts avec la possibilité de donner des répertoires de paramètres et non plus les fichiers détaillés. Il est ainsi possible d'avoir un fichier par host, un par service et on perd beaucoup moins de temps lors des ajouts car on sait où sont les erreurs : dans le dernier fichier ajouté !
Thruk est l'interface que j'ai testé car il est simple à installer depuis son Tarball, simple à paramétrer bien que le XML me donne des boutons ... et il peut très facilement "récupérer" les données depuis plusieurs fournisseurs ce qui est le cas ici avec le réseau principal (royaume par défaut) et le royaume "testweb" fraichement créé.
L'interface pousse même la bonté (beauté ?) jusqu'à fournir de petits boutons pour afficher ou non chaque royaume. On peut ainsi afficher un royaume quelconque, ou les deux, aussi bien parmi les "hosts" que parmi les services.
Il existe plusieurs "skins" pour cet interface mais je préfère pour le moment le skin par défaut défaut qui ressemble beaucoup à Nagios.
Cet interface est muni de certains perfectionnements très agréables, par exemple :
- cliquer sur quelques ligne sélectionne les hosts/services et une boîte de dialogue permet de leur appliquer un traitement commun ... check immédiat, suspension des contrôles etc.
Je vais préparer quelques belles images et une petite explication sur le paramétrage adopté ici.
D'abord des images : 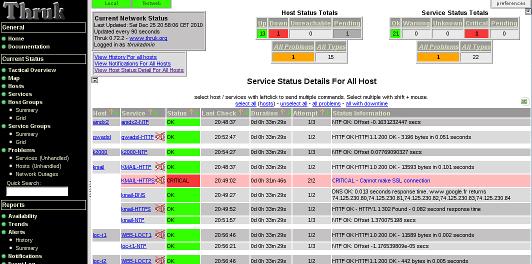
Admirez les deux "boutons" verts (en haut à gauche) qui vous permettent de sélectionner un "royaume" ou les deux.
Pour le reste l'aspect reste très "Nagios". 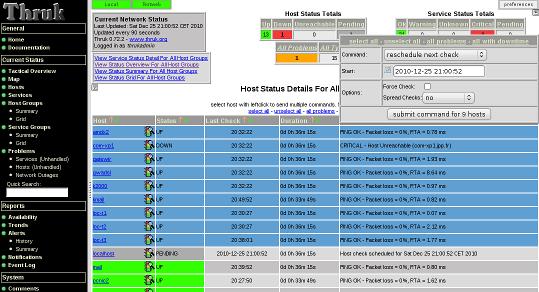
Ici j'ai sélectionné quelques "hosts" et la fenêtre d'action s'est ouverte, il est possible de réaliser les actions "standard" de Nagios "reschedule check", "enable notifications" .....
C'est beau !
Pour le paramétrage de THRUK il suffit d'ajouter un "peer" dans le fichier de configuration :
<peer>
name = Local
type = livestatus
<options>
peer = 127.0.0.1:50000
</options>
</peer>
<peer>
name = Testweb
type = livestatus
<options>
peer = 192.168.1.120:50000
</options>
</peer>
Les noms indiqués apparaîtrons dans les boutons de sélection de royaume.
Il faut bien entendu que le module "Livestatus" soit activé dans la configuration de Shinken :
define broker{
broker_name broker-1
address localhost
port 7772
spare 0
modules Status-Dat, Simple-log, Livestatus
manage_sub_realms 1
manage_arbiters 1
realm Local
}
Et le module lui même :
define module{
module_name Livestatus
module_type livestatus
host *
port 50000 ; port to listen
database_file /var/lib/shinken/livestatus.db
}
Le port peut être changé mais il ne faut pas oublier la communication avec Thruk !
Je vais maintenant essayer Ninja, mais l'installation de Merlin + Ninja + la base Mysql me semble complexe.
En bref la version 0.4 de SHINKEN semble stable et agréable à utiliser.
Shinken version 1.0.1
Shinken version 1.0.1 jppJ'ai un peu délaissé SHINKEN (Nagios "like") depuis un certain temps. Or la version 1 est sortie et j'ai vite téléchargé la version 1.0.1 depuis leur site.
Le tarball a un peu grossi et je décidé de l'installer dans une machine virtuelle "vierge". J'ai installé une Debian stable depuis une image cd CD et effectué immédiatement une mise à jour complète avec le couple magique :
apt-get update
apt-get upgrade
> Enable retention for broker scheduler and arbiter
Promesse de gascon, je n'ai pas eu le temps de faire un galop d'essai avec cette version, la suite en version 1.2.
Shinken version 1.2
Shinken version 1.2 jppIl y a déjà un certain temps j'avais testé Shinken dans différentes version de la 0.4 à la 1.0.1. C'est un bon candidat au remplacement pour la supervision de l'inévitable Nagios. La version 1.2 étant sortie j'ai eu envie de voir ce que ce logiciel était devenu car son développement semblait rapide et j'étais curieux de voir les progrès accomplis.
Afin de tester complètement j'ai démarré une nouvelle machine virtuelle (Debian 6 en 64 bits) pour un environnement performant. Les pré-requis sont assez simples, l'installeur s'occupe presque de tout !
Cet installeur permet d'installer le logiciel principal (avec tous les pré-requis) sans aucune difficulté et il semble fonctionner non seulement pour Debian mais aussi pour Redhat, Fedora et probablement CentOs.
Il permet ensuite d'installer d'autres modules tels que des plugins différents de ceux de Nagios et qui "valent le coup" :
Accès en supervision par SNMP pour les machines Unix/Linux, Accès en WMI pour Windows ...
On peut aussi installer quelques compléments tels que PNP4NAGIOS, mais chaque chose en son temps.
La philosophie du produit, fonctionnement en plusieurs tâches indépendantes, est très intéressante par la variété des configurations qui peuvent être gérées sans complication majeure.
THRUK
THRUK jppTHRUK : visualisation de l'état des systèmes supervisés par Shinken ou Nagios.
![]()
Suite à l'installation de Stretch la version précédemment installée a été rendue inopérante (voir l'installation "ancienne de THRUK").
J'ai donc installé la nouvelle version 2.14 dont les détails sont visibles ici.
Note : à la suite de la migration de Shinken/Omeganoc (changement de MV vers Debian 9) vers Shinken/Influxdb/Grafana j'ai réinstallé THRUK en version 2.18 (15/12/2017) en me servant de mon propre tuto.
Actuellement Thruk est en version 2.26-2 bien au chaud dans sa machine KVM.
THRUK : installation V2.14 sur Stretch
THRUK : installation V2.14 sur Stretch jppInstallation de ![]() sur Debian Stretch.
sur Debian Stretch.
Le passage à "Stretch" a "cassé" mon installation de Thruk, j'ai du la supprimer et la recharger.
J'en ai profité pour installer la dernière version : 2.4.12 du 5 mai 2017, 2.16.2 à ce jour (2017/10) automatiquement grâce à l'utilisation du repository de consol.labs.de.
Note juillet 2018 : aujourd'hui automatiquement en version 2.20.2, voir ici un article sur la version 2.20.
Pour les détails voir http://www.thruk.org.
D'abord récupérer les paquets "deb" sur le site https://download.thruk.org/download.html la plupart des distributions en 32 et 64 bits. Bref il y en a pour tous. Je me dirige vers Debian 9 64 bits et je tombe sur 4 paquets :
libthruk_2.14_debian9_amd64.deb 3.6M
thruk-base_2.14-2_debian9_amd64.deb 4.5M
thruk-plugin-reporting_2.14-2_debian9_amd64.deb 17.0M
thruk_2.14-2_debian9_amd64.deb 25K
Avant de les charger et de lire la doc je remarque qu'il existe des repository pour les principales distributions, pour Debian/Ubuntu une ligne à rajouter dans /etc/apt/source_list.d contenant :
"deb http://labs.consol.de/repo/stable/debian stretch main" suffit.
Puisque le créateur a pris la peine de faire des paquets Debian, autant s'en servir ...
Et en plus les mises à jour sont effectuées lors de la mise à jour standard du système, aujourd'hui (25/09/2017) passage sans douleur en 2.16.
Note décembre 2017 : après une ré-installation de Shinken pour ajouter InfluxDB/Grafana (voir ici) j'ai réainstallé Thruk directement depuis le repository de "Consol.de" sans aucune difficulté. Rappel : le port standard du "livestatus" de Shinken est le 50000.
La ligne est ajoutée dans /etc/apt/sources.list
apt-get update
Evidemment la signature des paquets n'est pas reconnue, je l'intègre avec le petit script suivant :
| #!/bin/bash CLE=$1 export CLE echo 'Cle='$CLE echo 'O/N ? ' read CHX case $CHX in o|O) ;; *) exit ;; esac echo 'Extraction clef' gpg --keyserver pgpkeys.mit.edu --recv-key $CLE ret=$? echo 'Ret='$ret gpg -a --export $CLE | apt-key add - ret=$? echo 'Ret='$ret |
La clef ne résiste pas à ce traitement et, pour vérifier, un nouvel apt-get update ne signale aucun message.
Et on charge les paquets :
apt-get install libthruk thruk-base thruk thruk-plugin-reporting
Après 26,4Mo de téléchargement l'installation se lance et s'installe sans aucune question, la fin de la trace suit :
| Setting up libthruk (2.14) ... Processing triggers for systemd (232-25) ... Processing triggers for man-db (2.7.6.1-2) ... Setting up thruk-base (2.14-2) ... thruk plugins enabled: business_process conf minemap mobile panorama statusmap Configuring apache2 vhost ... Module alias already enabled Enabling module fcgid. To activate the new configuration, you need to run: systemctl restart apache2 Considering dependency authn_core for auth_basic: Module authn_core already enabled Module auth_basic already enabled Module rewrite already enabled Enabling conf thruk_cookie_auth_vhost. To activate the new configuration, you need to run: systemctl reload apache2 Thruk have been configured for http://your-server/thruk/. The default user is 'thrukadmin' with password 'thrukadmin'. You can usually change that by 'htpasswd /etc/thruk/htpasswd thrukadmin' Setting up thruk (2.14-2) ... Setting up thruk-plugin-reporting (2.14-2) ... Processing triggers for systemd (232-25) ... |
On lance immédiatement "systemctl reload apache2" puis le browser de son choix et ... on arrive sur l'écran de connexion, thrukadmin/thrukadmin (on le changera plus tard) car on est pressé de voir la nouvelle version à l'oeuvre.
En haut à droite un menu fort sympa nous invite à modifier le mot de passe et à choisir un thème (il y en a 8) et tous ont un aspect agréable.
La première demande envoie sur la configuration de l'accès au "livestatus" :
 |
Une fois rempli, ici le livestatus de Shinken est accessible par le port 50000, un bouton "test" nous tend les bras et se marque en vert dès le clic, puis on valide les changements.
J'aime bien le thème 'classic" mais le "wakizashi" est agréable et très lisible.
Dans les "Current Status" :
"--> Tactical overview" ressemble fort à celle des versions précédentes mais ce n'est pas une critique !
"--> Map", donne toujours un beau dessin et en déplaçant la souris un petit panneau explicatif est affiché.
"--> Hosts", semblable aux derbières versions mais ce n'est pas non plus une critique, ce qui est utile n'a pas forcément besoin d'être modifié profondément.
"--> Host Groups et Service Groups" suscitent la même remarque, la nouveauté est le sous-menu "Mine Map" dans "Service Groups".
 |
"--> Problems" présente peu de modifications par rapport aux versions précédentes.
Dans les "Reports" :
"--> Availability", l'affichage "HTML" me donne une "Internal server error" alors que les autres sorties (xls, csv et json) fournissent des fichiers (xls et csv) ou un affichage (json) qui ont l'air corrects.
"--> Trends" donne le même type de résultats.
"--> Alerts" est impeccable et dispose de belles fonctions "calendrier" pour gérer les intervalles de dates.
"--> Notifications" est OK avec les mêmes possibilités au niveau des calendriers :
 |
"--> Eventlog" permet de rechercher dans les événements (alertes et checks passifs), on peut même exporter le résultat en fichier "xls" que se charge sans problème.
"--> Business Process", dommage , là je n'ai pas de données .
"--> Reporting", je n'ai pas encore inventorié toutes les possibilités de rapport ...
Au niveau "System" tout fonctionne normalement, on peut visualiser la configuration de ses hosts, groupes, services groupes, contacts ... et même les commandes.
La nouveauté dans "Config Tool" est la possibilité d'intégrer des plugins dont le plugin "reports" que je n'ai pas encore vraiment testé.
Télécharger un exemple de rapport "SLA".
Thruk nouveautés version 2.20
Thruk nouveautés version 2.20 jppAujourd'hui lors d'une mise à jour je constate qu'une mise à jour de THRUK est proposée : de 2.18 à 2-20.2.
Les paquets concernés sont : thruk, thruk-base et thruk-reporting.
Après installation il apparaît au moins une nouvelle fonctionnalité :
Création d'un Dashboard personnalisé accessible dans le menu "Panorama" que je n'avais pas encore utilisé.
Cette fonction permet de construire, facilement, une page personnalisée à partir d'éléments préfabriqués par choix dans un menu et positionnement dans la page.
On peut ainsi avoir quelques indicateurs synthétiques ou un "Minemap" détaillé parfait si vous n'avez pas trop de serveurs/services.
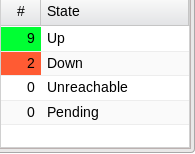
Le tableau "hosts" présente une ligne par machine avec de nombreuses possibilités de filtrage sur le statut des serveurs (UP, Down, Unreachable, Pending) ou sur d'autres caractéristiques : hostgroup, contact, parent, service, servicegroup ....

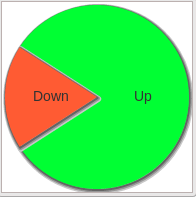
Le tableau "hosts totals" présente une synthèse de l'état des différents serveurs, "hosts graph" présente les mêmes données sous forme de camembert.
|
|
Il existe le même type de tableau pour les services, ci dessous un exemple du tableau "services" avec un filtrage sur le nom du service, ici "Load".
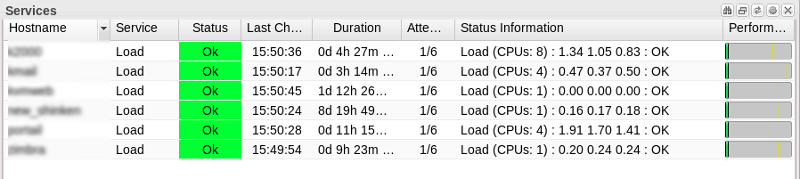
Pour tous les tableaux il est possible de choisir les colonnes affichées, d'utiliser une colonne pour trier le tableau .... la personnalisation est aisée.
J'ai un peu insisté sur cette partie nouvelle et je n'ai aperçu de modifications dans "Reporting", on peut télécharger un exemple de rapport SLA ici.
Pour les autres affichages je n'ai pas noté de différences marquantes mais tout fonctionne à merveille.
Thruk Debian Buster
Thruk Debian Buster drupadminLors du passage d'une machine utilisant Thruk en Debian 10 "Buster" j'avais complètement oublié d'ajouter le repository de "Consol labs" dans mon nouveau fichier sources-list.
La ligne à rajouter dans le fichier "sources list " :
deb http://labs.consol.de/repo/stable/debian/ buster main
Lors de l'installation j'ai eu une erreur :
(Reading database ... 205802 files and directories currently installed.)
Preparing to unpack libthruk_2.30_amd64.deb ...
Unpacking libthruk (2.30) over (2.30) ...
Preparing to unpack thruk-base_2.30-3_amd64.deb ...
cp: cannot stat '/etc/thruk/plugins/plugins-enabled/*': No such file or directory
dpkg: error processing archive thruk-base_2.30-3_amd64.deb (--install):
new thruk-base package pre-installation script subprocess returned error exit status 1
Setting up libthruk (2.30) ...
Errors were encountered while processing:
thruk-base_2.30-3_amd64.deb
J'ai trouvé une solution rapide pour régler le problème :
- Vérifier l'existence du répertoire "/etc/thruk/plugins/plugins-enabled"
- Y créer un fichier "bidon" style "README.txt"
Relancer l'opération (avec --force-install) :
dpkg -i --force-all thruk-base_2.30-3_amd64.deb
Pour moi cela a bien fonctionné et m'a installé une belle version 2.30 ! Que je vais m'empresser de tester dès demain.
PS la 2.30 : elle fonctionne fort bien ...
Omeganoc : visualiser de l'état de vos systèmes
Omeganoc : visualiser de l'état de vos systèmes jppOmeganoc est un logiciel français, cocorico, qui associé à Shinken et à ses sondes permet :
- de conserver l'historique des données de mesure
- d'afficher des tableaux de bord graphiques du plus bel effet.
Note 2017 : Malheureusement ce logiciel ne semble plus maintenu et la dernière version connue est la 0.93. Il vaut mieux aujourd'hui utiliser Grafana/InfluxDB, à voir ici.
La partie stockage utilise la base de données "whisper", analogue dans son principe au très connu RRD, qui utilise un démon spécifique nommé carbon-cache. Cette base est alimentée directement par l'intermédiaire du module "Livestatus" de Shinken et exploitée par deux outils spécifiques à Omeganoc :
- Hokuto qui gère l'interface graphique :
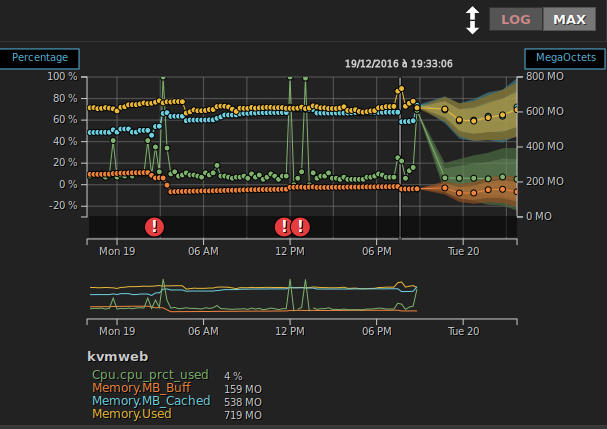
- Nanto qui gère une partie "prévisions" à partir des données stockées.
L'installation est assez complexe, surtout par le nombre de dépendances "inconnues". Nanto utilise "R" pour établir ses prévisions ... et nécessite, lui aussi, un certain nombre de dépendances, pas toujours évidentes.
Omeganoc : installation
Omeganoc : installation jppLe produit peut s'installer avec un classique "tar.gz" ou bien directement par "Git". Il comporte une partie "Shinken" dont je ne me suis pas servi car Shinken était déjà installé sur la machine virtuelle.
Par précaution j'ai effectué un snapshot du disque de cette MV afin de pouvoir recommencer l'installation proprement sur incident. J'ai bien fait car la liste des pré-requis est très largement insuffisante.
J'ai donc téléchargé l'archive :
http://www.omegacube.fr/downloads/omeganoc.v0.93.tar.gz (# 11Mo).
Je l'ai ensuite décompressée dans un petit répertoire bien tranquille avant d'y lancer la commande fatidique ...
Non,non, j'ai dit qu'il manquait des pré-requis, je vous ferais grâce des plantages que leur absence provoque. Il faut donc installer les paquets suivants (les autres ont déjà été chargés lors de l'installation de Shinken) :
| graphviz graphviz-dev libgraphviz-dev pkg-config python-dev libigraph0 libigraph0-dev |
C'est bon, cette fois on peut lancer le "make install" :
| # Checks that Shinken is installed /usr/bin/python /usr/bin/shinken /usr/bin/pip pip install 'graphite-query==0.11.3' Downloading/unpacking graphite-query==0.11.3 ....... |
Ca télécharge et ça compile sec pendant plusieurs minutes dans ma pauvre VM monoprocesseur, le nombre de dépendances est très important ... et cete fois il manque le paquet "igraph" avec le paquet de développement associé "apt-get install libigraph0 libigraph0-dev" et c'est reparti ... à charger et compiler plein de trucs.
Cette fois-ci cela se termine par :
| Cleaning up... useradd --user-group graphite shinken install --local vendor/livestatus OK livestatus shinken install graphite Grabbing : graphite OK graphite shinken install --local vendor/logstore-sqlite OK logstore-sqlite shinken install --local hokuto OK hokuto shinken install named-pipe Grabbing : named-pipe OK named-pipe shinken install pickle-retention-file-generic Grabbing : pickle-retention-file-generic OK pickle-retention-file-generic Installing cron routine and restarting cron service... Omeganoc have been succefully installed Add 'modules graphite, livestatus, hokuto' to your broker-master.cfg file Add modules named-pipe, PickleRetentionArbiter to your arbiter-master.cfg file Add modules logstore-sqlite to livestatus.cfg. running install running build running build_py creating build creating build/lib.linux-x86_64-2.7 creating build/lib.linux-x86_64-2.7/on_reader copying on_reader/predict.py -> build/lib.linux-x86_64-2.7/on_reader copying on_reader/livestatus.py -> build/lib.linux-x86_64-2.7/on_reader copying on_reader/mk_livestatus.py -> build/lib.linux-x86_64-2.7/on_reader copying on_reader/__init__.py -> build/lib.linux-x86_64-2.7/on_reader running install_lib creating /usr/local/lib/python2.7/dist-packages/on_reader copying build/lib.linux-x86_64-2.7/on_reader/predict.py -> /usr/local/lib/python2.7/dist-packages/on_reader copying build/lib.linux-x86_64-2.7/on_reader/livestatus.py -> /usr/local/lib/python2.7/dist-packages/on_reader copying build/lib.linux-x86_64-2.7/on_reader/mk_livestatus.py -> /usr/local/lib/python2.7/dist-packages/on_reader copying build/lib.linux-x86_64-2.7/on_reader/__init__.py -> /usr/local/lib/python2.7/dist-packages/on_reader byte-compiling /usr/local/lib/python2.7/dist-packages/on_reader/predict.py to predict.pyc byte-compiling /usr/local/lib/python2.7/dist-packages/on_reader/livestatus.py to livestatus.pyc byte-compiling /usr/local/lib/python2.7/dist-packages/on_reader/mk_livestatus.py to mk_livestatus.pyc byte-compiling /usr/local/lib/python2.7/dist-packages/on_reader/__init__.py to __init__.pyc running install_egg_info Writing /usr/local/lib/python2.7/dist-packages/datareader-0.5.egg-info Installing Hokuto cp -r hokuto/standalone/* /usr/local/hokuto cp hokuto/etc/hokuto.cfg /etc/hokuto.cfg running clean |
Cela à un petit air de fin normale, on va pouvoir essayer de lancer le logiciel ... après avoir inspecté les paramètres de "hokuto" (/etc/hokuto.cfg) et modifié la clef "secrète".
Le "Live-status" de Shinken est bien en écoute sur le port TCP 50000, cela devrait fonctionner avec les paramètres standard de "hokuto".
Le script de lancement de "hokuto" a été installé dans /etc/shinken/init.d ? Il faudra le mettre à sa place (ou mettre un lien) suivi d'un "update-rc.d .... enable".
Ma petite VM se met à swapper, je la stoppe et la redémarre avec carrément 1536Mo de mémoire et deux processeurs pour évaluer la taille optimale nécessaire.
Omeganoc : ajustements
Omeganoc : ajustements jppLa documentation est assez spartiate et comme le stockage des données est réalisé par "Graphite" et la base de données "Whisper" (semblable dans son principe à RRD), il faut configurer convenablement la rétention par défaut.
Le fichier /opt/graphite/conf/storage-schémas.conf doit impérativement être modifié car avec ces paramètres les données ne sont conservées qu'un jour. Comme je m'intéresse aux pointes de consommation j'ai forcé la méthode d'aggrégation à "max", et mis une conservation par défaut à 60 secondes pendant 30 jours, puis 180s pendant 90j et 540s pendant 365j. Cela donne :
| [default_1min_for_1day] pattern = .* retentions = 60s:30d,180s:90d,540s:365d aggregationMethod = max |
Cela donne une bonne base et il est toujours possible par la suite de modifier ces paramètres fichiers par fichiers. Il est en effet inutile de conserver minute par minute le volume disque utilisé, l'utilitaire "whisper-resize.py" permet de modifier les paramètres fichier par fichier :
FILE=mon_fichier.wsp
whisper-resize.py --aggregationMethod=max $FILE 60s:15d 180s:90d 540s:365d
Les fichiers de données sont placés dans des répertoires par "machine" dans l'arborescence "/opt/graphite/storage/whisper". Chaque plugin donne lieu à un répertoire contenant les fichiers de données, par exemple :
drwxr-xr-x 2 root root 4096 janv. 29 20:29 Cpu
drwxr-xr-x 2 root root 4096 févr. 23 23:03 D_
drwxr-xr-x 2 root root 4096 févr. 23 23:04 D_boot
drwxr-xr-x 2 root root 4096 janv. 29 20:29 __HOST__
drwxr-xr-x 2 root root 4096 janv. 29 20:29 Load
drwxr-xr-x 2 root root 4096 févr. 20 11:49 Memory
drwxr-xr-x 2 root root 4096 janv. 29 20:29 Niceth0
drwxr-xr-x 2 root root 4096 janv. 29 20:29 Smtp
drwxr-xr-x 2 root root 4096 janv. 29 20:29 TimeSync
Le répertoire "D_" (partition "/") contient ici deux fichiers :
_Pctused.wsp
Sizeused.wsp
qui contiennent le % utilisé de la partition et la taille utilisée.
Autre sujet "qui fâche", mais on s'y fait, il faut éviter comme la peste les séparateurs style "-" (tiret) dans les noms de machines ou de services ... car l'interface graphique ne les montre pas (absence de ces machines/services dans les boites de choix) ... cela devrait être corrigé dans une prochaine version.
Omeganoc : ajustements (2)
Omeganoc : ajustements (2) jppL'affichage réalisé "en direct" par Hokuto ne montre pas une chose très intéressante/amusante : il est possible de faire calculer des prévisions par le module "Nanto" qui s'affichent comme les données de mesure, presque, elles sont grisées et font de petits panaches du plus bel effet.
Nanto est réalisé en "R", ce qui m'a donné l'occasion de rentrer un peu dans ce système de calcul pour réussir à la faire tourner. Cette fonctionnalité est plus ou moins expérimentale, mais un peu "coton" à installer.
Au premier essai "Nanto" refuse de se lancer :
| File "/usr/local/nanto/service.py", line 34, in <module> from lockfile.pidlockfile import PIDLockFile ImportError: No module named pidlockfile |
Simple probleme de version entre les modules "lockfile" et "python-daemon"
Je désinstalle et réinstalle les deux dans les versions suivantes :
python-daemon 2.1.0
lockfile-0.12.2
Ensuite copier ...../omeganoc/nanto/etc/nanto.cfg dans /etc/nanto.cfg
Après cette petite cure le process "nanto" démarre, mais il lui manque des tas de choses :
ImportError: No module named rpy2.rinterface
Pas de "R" non plus !
Cela se résout par "apt-get install python-rpy2" qui charge tout ce qui semble nécessaire (entre autres les packages "R") :
| bzip2-doc cdbs gfortran gfortran-4.9 libblas-dev libbz2-dev libgfortran-4.9-dev libjpeg-dev libjpeg62-turbo-dev liblapack-dev liblzma-dev libncurses5-dev libpcre3-dev libpng12-dev libreadline-dev libreadline6-dev libtcl8.5 libtinfo-dev libtk8.5 r-base-core r-base-dev r-cran-boot r-cran-class r-cran-cluster r-cran-codetools r-cran-foreign r-cran-kernsmooth r-cran-lattice r-cran-mass r-cran-matrix r-cran-mgcv r-cran-nlme |
soit 47Mo d'archives.
Auxquels il faut ajouter "r-cran-segmented" ? et "r-cran-fimport" ? ainsi que r-cran-nnet r-cran-rpart r-cran-spatial r-cran-survival r-doc-html r-recommended ...
En modifiant le fichier de config "/etc/nanto/cfg" et en décommentant le "debug_worker" on peut déclencher un calcul immédiat et non en attendant l'horaire planifié.
J'obtient une nouvelle erreur :
| ERROR - An error occured while executing the R script "/usr/local/nanto/timewindow.r": Error in library("forecast") : there is no package called ‘forecast’ Malgré cette erreur le programme continue et calcule plein de trucs (selon le log) avec toutefois de nouveaux messages d'erreur : An exception occured while computing the timewindow predictions for component gwadsl.__HOST__.pl: global name 'save_error' is not defined |
Dans quel paquet Debian se trouve cette librairie ?
"apt-get install r-cran-fimport"
qui installe en outre :
lynx lynx-cur r-cran-fimport r-cran-timedate r-cran-timeseries
Cette installation ne fournit pas la librairie "forecast" car les messages d'erreur sont toujours présents !
Une recherche donne la possibilité que ces paquets soient disponibles grâce à l'archive : "http://cran.univ-paris1.fr/" (ou lyon1.fr), ajouter dans votre "sources.list" :
deb http://cran.univ-paris1.fr/bin/linux/debian jessie-cran3/
Le message sur la librairie "forecast" est toujours présent, il faut installer le paquet ? On lance "R" :
| R R version 3.1.1 (2014-07-10) -- "Sock it to Me" Copyright (C) 2014 The R Foundation for Statistical Computing Platform: x86_64-pc-linux-gnu (64-bit) .... Type 'demo()' for some demos, 'help()' for on-line help, or 'help.start()' for an HTML browser interface to help. Type 'q()' to quit R. install.packages("forecasting") Installing package into ‘/usr/local/lib/R/site-library’ (as ‘lib’ is unspecified) --- Please select a CRAN mirror for use in this session --- |
------ cela ouvre une fenêtre pour choisir le serveur CRAN, ici on choisit "France (Lyon 1)"
|
package ‘forecasting’ is not available (for R version 3.1.1) The downloaded source packages are in |
On ne sauvegarde pas le "workspace", On reteste le lancement de "nanto" et cette fois cela a l'air de mieux fonctionner, le service se lance et lance immédiatement le calcul. Le log ne présente plus de message d'erreur et on peut penser que le calcul est réussi !
Toutefois quelques messages d'erreur sont présents sur quelques catégories :
| 016-01-13 17:38:49,496 - root - DEBUG - [nanto:timewindow] Found 0 data points for node filtre.NetworkUsage.br0_in_octet.1452616033 2016-01-13 17:38:49,496 - root - INFO - [nanto:timewindow] Skipped time series on filtre.NetworkUsage.br0_in_octet.1452616033: not enough data (0 points) 2016-01-13 17:38:49,496 - root - WARNING - [nanto:timewindow] An exception occured while computing the timewindow predictions for component filtre.NetworkUsage.br0_in_octet.1452616033: global name 'save_error' is not defined 2016-01-13 17:38:49,496 - root - DEBUG - [nanto:timewindow] Exception details: Traceback (most recent call last): File "/usr/local/nanto/timewindow_worker.py", line 61, in internal_run success = self.__go(c, checkinterval) File "/usr/local/nanto/timewindow_worker.py", line 94, in __go save_error(target, "There is not enough data to have make accurate predictions") NameError: global name 'save_error' is not defined |
Remarque :
Cela consomme pas mal de CPU : 50 à 98% de ma VM (en monoprocesseur).
Le volume de la base de données sqlite "/var/lib/shinken/nanto.db" augmente sérieusement et dépasse 1,5 mégaoctet sur mon petit test ne comportant que 8 machines et environ 30 services.
Dans mon cas le calcul a duré de : 17:37:47 à 17:54:34 soit environ 17 minutes.
La consommation mémoire reste très raisonnable : moins de 450M hors buffers et cache, environ 896M de mémoire devraient suffire largement dans mon cas.
Test avec 1024Mo de mémoire et 2 CPU.
Remarques :
1) Nanto n'utilise qu'un seul processeur !
2) Consommation mémoire < 1024Mo y compris buffers et cache.
3) Durée du traitement :
19:21:07 à 19:37:35, 1050 secondes soit un peu plus de 17 minutes
21:37:41 à 21:53:11, 930 secondes soit un peu plus de 15 minutes.
Charger aussi "apt-get install libopenblas-base " pour augmenter les performances en multithread; cela n'est pas évident, même avec deux processeurs attribués à la MV. En fait avec 1 processeur et 1024Mo de mémoire tout se passe bien et le fichier "nanto.db" s'est stabilisé à moins de 300Ko.
Omeganoc : graphiques
Omeganoc : graphiques jppNote 2022 : ces graphiques sont presque aussi beaux que ceux de Grafana, mais Omeganoc n'est plus, paix à son âme, c'est dommage c'était un produit intéressant et agréable à utiliser.
Pour égayer un peu mes propos quelques graphiques présentés par Omeganoc, la partie "calculée" est sur la droite.
Un graphe simple de l'usage CPU sur 24 heures :
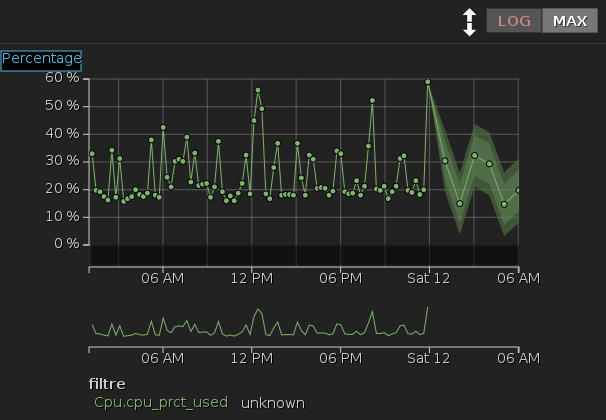 |
A noter les possibilités :
- Modifier les limites de dates affichées, dernières 24 heures, mois en cours, derniers 30 jours ... ou des zones de dates précises avec calendrier cliquable
- Afficher en linéaire ou logarithmique
- Afficher MAX/MIN/AVG
- Zoom sur une zone avec le roulette de souris
La zone hachurée à droite correspond aux prévisions calculées par Nanto.
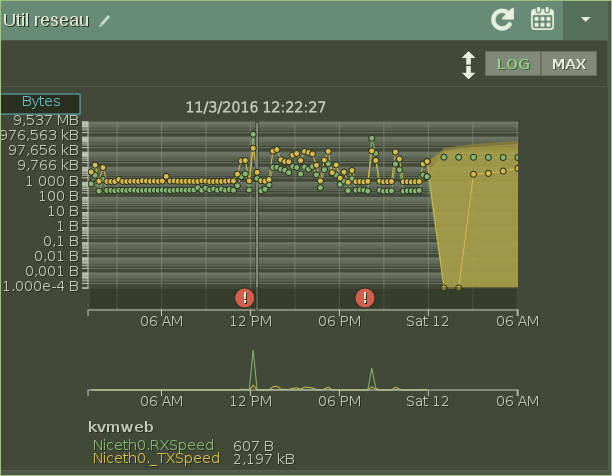
Un graphe logarithmique d'utilisation réseau :
 |
Zoom sur l'utilisation CPU/mémoire vers 12h51 :
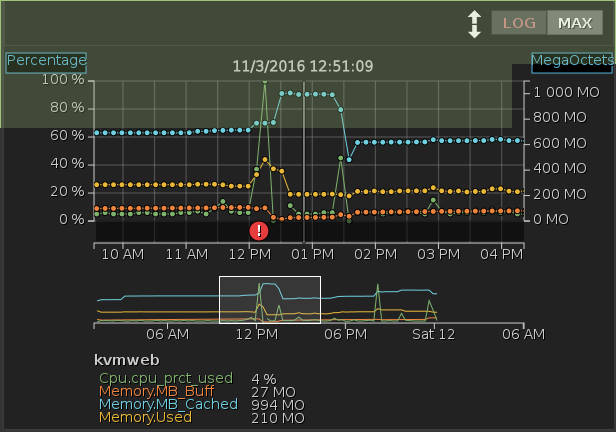 |
On peut remarques l'alerte (rond rouge) pour utilisation du CPU qu'il suffit de cliquer pour avoir plus d'informations : heure, message ...
NtopNG
NtopNG jppNtop 
C'est un logiciel assez ancien dont la maintenance et l'évolution sont suivis et continus, le projet est très actif en 2023/2024. De nouvelles versions sont présentées assez souvent et donnent toujours de nouvelles possibilités de suivi et d'analyse, la plus marquante, déjà ancienne était la première version "NG".
- La première version "NG" (1.2) est présentée ici.
- La version "NG" (2.2) est présentée ici et permet, entre autres nouveautés l'enregistrement des "flows" dans une base Mysql pour exploitation ultérieure.
- La dernière version stable début 2017 est la 2.4 présentée ici.
- Nouveauté après les vacances d'été 2017 est la 3.1 présentée ici.
- Avril 2018 la version 3.5 est présentée ici.
- Une statistique intéressante sur les ports les plus attaqués ici.
- Exploitation des données enregistrées.
- Utilisation de InfluxDB avec NtopNG pour affichage Grafana
NtopNG : version 1.2
NtopNG : version 1.2 jppNote Juin 2016 : un test d'une version plus récente (2.2) est disponible ici.
Note Octobre 2016 : notes sur la version 2.4 disponibles ici.
Note Avril 2018 : Présentation de la version 3.5 c'est lài.
Utilisateur de longue date de NTOP j'ai voulu tester cette nouvelle version 1.2 NG, comme elle n'existe pas dans les dépôts Debian standard je l'ai donc compilée depuis les sources.
Première chose : vérifier les pré-requis :
autotools-dev libtool
libgeoip1 libgeoip-dev
libsqlite3-dev libxml2-dev
redis-server
libglib2.0-dev
Si cette dernière n'est pas chargée vous aurez un message à la compilation (cf ci-dessous).
Charger le paquet (1.2.1 à ce jour) dans un répertoire tranquille :
cd MON_REPERTOIRE_SOURCES
wget http://sourceforge.net/projects/ntop/files/ntopng/ntopng-1.2.1.tgz
cd MON_REPERTOIRE_BUILD
tar -xvf ../ntopng-1.2.1.tgz
cd ntopng-1.2.1
./autogen.sh
./configure 2>&1 | tee CONFIGURE.LOG
qui vous rappelle à la fin de faire un "make geoip" qui charge les fichiers de données de localisation, on l'effectuera après la compilation.
make 2>&1 | tee MAKE.LOG
qui se termine cette première fois par une erreur :
configure: error: Please fix the library issues listed above and try again.
make[1]: Entering directory `/usr/src/PGM/BUILD/ntopng-1.2.1/third-party/rrdtool-1.4.8/src'
make[1]: *** No rule to make target `librrd_th.la'. Stop.
make[1]: Leaving directory `/usr/src/PGM/BUILD/ntopng-1.2.1/third-party/rrdtool-1.4.8/src'
make: *** [third-party/rrdtool-1.4.8/src/.libs/librrd_th.a] Error 2
En remontant un peu dans le LOG on trouve quelques warnings concernant glib2.0 :
I could not find a working copy of glib-2.0.
Check config.log for hints on why this is the case. Maybe you need to set
LDFLAGS and CPPFLAGS appropriately so that compiler and the linker can find
libglib-2.0 and its header files. If you have not installed glib-2.0,
Il semble manquer les fichiers de développement de GLIB2 -->
apt-get install libglib2.0-dev
et on relance :
make clean
./configure
make 2>&1 | tee MAKE.LOG
La compilation est assez longue sur ce brave CoreI3. Comme je n'ai pas utilisé de paramètres spécifique de répertoires l'installation se fera dans "/usr/local".
On peut constater que de nombreuses extensions tierces parties sont aussi compilées.
On lance maintenant le "make geoip" qui nous récupère sans problèmes les fichiers de localisation géographique.
Le fichier "Makefile" est très instructif, on y voit par exemple que ce paquet contient de quoi fabriquer ".deb" et ".rpm" pour installation sur d'autres machines.
On passe en "root" pour le "make install" qui s'effectue sans aucun problème.
Une étude plus détaillée des répertoires montre "packages/etc" avec deux répertoires "init" et "init.d" comprenant le script de démarrage et le répertoire "ini" la mise en place est rapide :
cd packages/etc/init.d
cp ntopng /etc/init.d
mkdir /etc/ntopng
cp ../init/ntopng.conf /etc/ntopng
update-rc.d ntopng defaults
Comme notre installation a été faite en mode "développement" (programmes dans /usr/local) il faut rectifier légèrement le script de lancement et modifier la variable NTOPNG_BINARY de "/usr/bin/ntopng" en "/usr/local/bin/ntopng".
Ne pas "oublier" de créer le fichier "ntopng.start" dans /etc/ntopng :
touch /etc/ntopng/ntopng.start
Il faut ajouter quelques "broquilles" a "/etc/ntopng/ntopng.conf" :
--user=ntopng
User qui sera utilisé, c'est important pour les droits sur le répertoire "data" et le fichier "PID".
-G=/var/lib/ntopng/ntopng.pid
Avec un seul tiret ! Celui-ci fixe le nom du fichier "pid", utilisé pour stopper le démon, mais attention le fichier est ouvert par le user "nobody" qui, au moins sur une Debian, n'a pas de droits sur /run (ou /var/run).
Avec un user personnalisé et un répertoire propre aucun problème.
--local-networks "192.168.1.0/24"
Pour fixer le ou les réseaux locaux (liste entre " séparée par des virgules)
--interface eth0
--interface eth1
Pour fixer les interfaces à utiliser (une ligne par interface), ici je laisse tomber l'interface "lo".
--data-dir /var/lib/ntopng
Un répertoire à créer avec droits lecture/écriture pour le user choisi : Ntop stocke ici les fichiers nécessaires y compris les RRD, il faut prévoir un peu d'espace disque.
--packet-filter="ip and not proto ipv6 and not ether host ff:ff:ff:ff:ff:ff and not net (224.0.0.0/8 or 239.0.0.0/8)"
Pour éliminer beaucoup de trafic "inintéressant", je n'ai pas IPV6 et les broadcast prennent de la place.
--http-port 3001
Si le port standard de 3000 vous déplaît.
--daemon
A ne pas louper ....
Avant de lancer le démon il faut encore :
- Créer le user ntopng
- Créer le répertoire /var/lib/ntopng et rendre "ntopng" propriétaire : chown ntopng:ntopng /var/lib/ntopng
- Cataloguer le démon : update-rc.d ntopng default
- Lancer le démon : service ntopng start
On peut ensuite se connecter sur localhost:3001 avec les mots de passe par défaut admin/admin, comme c'est original !
Depuis cet interface on peut créer d'autres utilisateurs et modifier le mot de passe par défaut de "admin".
L'interface est très riche et dispose de nombreuses fonctions, la génération d'alertes est parfois gênante ... et je n'ai pas encore testé les fonctions LUA.
NtopNG : version 2.2
NtopNG : version 2.2 jppNote Août 2016 : il existe une version plus récente, (2.4) voir ici l'article correspondant.
Note Avril 2018 : voir ici les détails sur la version 3.5.
Cette nouvelle version permet entre autres choses l'historisation des flux dans une base Mysql.
Les tests ont été réalisés dans une Machine Virtuelle fraîchement créée afin de mieux cerner les pré-requis.
J'ai d'abord installé un ensemble de compilation (make ... gcc-4.9), et Vim mon editeur préféré.
Ah, au passage mettez votre utilisateur "standard" dans la liste des "sudoers" avec la maximum de droits (on est sur une MV de tests), cela servira plus tard.
Pour les pré-requis il suffit de :
build-essential git libglib2.0 libxml2-dev libpcap-dev
libtool libtool-bin rrdtool librrd-dev
autoconf automake autogen
redis-server wget libsqlite3-dev libhiredis-dev libgeoip-dev
libcurl4-openssl-dev libpango1.0-dev libcairo2-dev libpng12-dev
libmysqlclient-dev ethtool
Un "apt-get toute_cette_liste" est à lancer ... qui installe plein de trucs supplémentaires (#72Mo à télécharger).
Il faut aussi un serveur de base de données Mysql ou MariaDB, pour faire bonne mesure un "apt-get mysql-server-5.5 mysql-client-5.5" installe le gestionnaire de BDD.
Petite remarque, l'installation de Mysql signale une valeur "deprecated" :
Using unique option prefix key_buffer instead of key_buffer_size is deprecated and will be removed in a future release. Please use the full name instead.
Autant modifier ce paramètre tout de suite dans la config : remplacer "key_buffer" par "key_buffer_size".
Après cette petite parenthèse on peut, en continuant la lecture du "README.compilation" se lancer dans la compilation du logiciel.
A partir d'ici abandonner le user "root" et utiliser le user avec droits "sudo", "sudo" pourra être utilisé lorsque le besoin s'en fait sentir, mais "sudo" est de toute façon utilisé au cours de certains scripts.
D'abord, récupérer les sources (c'est un gros paquet de plus de 90Mo), à la date d'écriture de cet article c'est la version 2.2 :
wget https://sourceforge.net/projects/ntop/files/ntopng/ntopng-2.2.tar.gz/download -O ntopng-2.2.tar.gz
La version installée est, en fait, une version 2.3 :
ntopng --version
v.2.3.160619 [Community Edition]
On le détare ensuite dans un répertoire tranquille et on est (presque) prêts.
Le répertoire "doc" contient plein de fichiers README dont l'un contient tous les pré-requis à la compilation et au fonctionnement de Ntopng, cela semble être le pied!
===========================================
cd le_repertoire_ntopng
./autogen.sh
./configure
Beaucoup de choses se passent et à la fin on vous rappelle de lancer : "make geoip" pour mettre à jour la base géographique. Je m'empresse de lancer cette commande avant toute chose et cela charge les bases "Lite" de Maxmind pour IPV4 et IPV6.
On peut enfin lancer le "make" en gardant les traces :
make 2>&1 | tee LOG.MAKE
La compilation est assez longue, mais elle compile plusieurs applications :
detectxsslib
hiredis
json-c
lsqlite3
LuaJIT-2.0.3
mongoose
patricia
rrdtool-1.4.8
snmp
zeromq-4.1.3
On est ainsi certain d'utiliser des versions spécifiques nécessaires au bon fonctionnement du logiciel.
L'option "install" de make vous recommande de créer un package à installer et fournit les outils nécessaires :
Make sure you have already run 'make geoip' to also install geoip dat files
While we provide you an install make target, we encourage you
to create a package and install that
rpm - do :
make build-rpm
deb - do :
cd packages/ubuntu
./configure
make
J'essaye le paquet Debian/Ubuntu
Le "./configure" a créé un fichier README qui conseille d'installer quelques paquets complémentaires "apt-get install debhelper fakeroot dpkg-sig" qui dans mon cas n'installe que "dpkg-sig libconfig-file-perl".
Je m'empresse de lancer le "make"
make 2>&1 | tee MAKE.LOG
qui démarre très fort en utilisant "sudo", la package est créé et à la fin, la signature échoue car aucune signature GPG n'est disponible. A part cette erreur le paquet semble OK et un contrôle du paquet donne un résultat correct :
dpkg -I ntopng_2.3.160619-757_i386.deb
new debian package, version 2.0.
size 4648220 bytes: control archive=12748 bytes.
47 bytes, 1 lines conffiles
309 bytes, 10 lines control
30016 bytes, 357 lines md5sums
667 bytes, 38 lines * postinst #!/bin/sh
101 bytes, 9 lines * postrm #!/bin/sh
664 bytes, 35 lines * preinst #!/bin/sh
387 bytes, 16 lines * prerm #!/bin/sh
Package: ntopng
Version: 2.3.160619-757
Architecture: i386
Maintainer: Luca Deri <deri@ntop.org>
Installed-Size: 19479
Depends: libsqlite3-0, libgeoip1, redis-server, librrd4, logrotate, libcurl3
Recommends: ntopng-data, pfring-dkms
Section: free
Priority: optional
Description: Web-based traffic monitoring.
Il est maintenant temps d'essayer ce paquet :
dpkg -i ntopng_2.3.160619-757_i386.deb
Sélection du paquet ntopng précédemment désélectionné.
(Lecture de la base de données... 138081 fichiers et répertoires déjà installés.)
Préparation du dépaquetage de ntopng_2.3.160619-757_i386.deb ...
Dépaquetage de ntopng (2.3.160619-757) ...
Paramétrage de ntopng (2.3.160619-757) ...
Rebuilding ld cache...
Adding the ntopng startup script
Making the /etc/ntopng directory...
Traitement des actions différées (« triggers ») pour systemd (215-17+deb8u4) ...
Traitement des actions différées (« triggers ») pour man-db (2.7.0.2-5) ...
Traitement des actions différées (« triggers ») pour libc-bin (2.19-18+deb8u4) ...
C'est tout ? Pas d'installation de base de données .... ni rien ?
Un script d'init a été installé, donnons lui un petit coup de "service ntopng start" ... le service se lance et crée un fichier minimal de config "ntopng.conf" de 1 ligne dans /etc/ntopng :
-G=/var/tmp/ntopng.pid
Le programme est bien lancé et attends sur le port 3000, voyons donc ce qui se passe sur ce port --> Iceweasel, pardon Firefox, sur le port 3000.
Un écran de login tout à fait semblable à celui de la version précédente ... un admin/admin (user/mot de passe par défaut) plus loin l'écran des "top flow talkers" s'affiche, tout a l'air de fonctionner, l'aspect général est semblable à celui de NtopNG 1.2.
En allant voir les préférences je trouve bien trace d'une base Mysql et d'une durée d'historisation, mais pas de couple user/password ? Un certain nombre de paramètres utiles pour les fichiers RRD afin de na pas épuiser son espace disque tout en gardant le détail voulu.
En examinant les logs (fichier "messages") quelques lignes concernent Ntopng :
ntopng: [NetworkInterface.cpp:950] WARNING: If you have TSO/GRO enabled, please disable it
ntopng: [NetworkInterface.cpp:952] WARNING: Use: sudo ethtool -K eth0 gro off gso off tso off
Je m'empresse de lancer la commande citée :
ethtool -K eth0 gro off gso off tso off
et de redémarrer Ntopng.
Au niveau de Mysql, aucune base n'a été créée et je n'ai pas trouvé les scripts de création ni les paramètres correspondants.
Pour utiliser Mysql il faut lancer Ntopng avec une option '-F mysql paramètres" et pour cela aucune il suffit de modifier le fichier de config en y ajoutant une ligne :
Les paramètres sont sous la forme :
mysql;<host>;<dbname>;<table name>;<user>;<pw>
soit pour moi :
-F=mysql;localhost;ntopng;ntopng;userntop;passntop
Les tables seront donc dans une base "ntopng" (à créer) et aurons pour préfixe "ntopng" et Ntopng se connectera avec "userntop/passntop".
Les tables sont ici :
- ntopngV4_0 pour les IP V4 "externes"
ntopngV4_1 pour les IP V4 "locales", ici 127.0.0.1 sans autre paramétrage - ntopngV6_0 pour les IPV6 "externes"
- ntopng_V6_1 pour les IPV6 "locales"
Ces tables comportent toutes les infos nécessaires, adresses,ports,nombre de paquets, nombre d'octets transférés, date de début et de fin (unix "epoch" format) une partie "INFO" dont le contenu est très intéressant car il contient, par exemple, le contenu de la demande dans le cas des appels à un DNS. Pour la partie "Json" je n'ai pas analysé le contenu exact.
Voir en annexe quelques scripts sql simples pour commencer.
Attention, la taille de la base peut rapidement devenir conséquente selon l'activité, un délai de conservation est d'ailleurs prévu dans les paramètres et fixé par défaut à 1 jour. Il faudra certainement créer des tables d'historisation condensées si on veut conserver un historique plus long.
Je vais rapidement générer et installer un paquet Debian 64 bits pour remplacer la version 1.2 précédente sur la machine "pont" vers Internet.
NtopNG : version 2.4
NtopNG : version 2.4 jppCette dernière version apporte un plus intéressant (déjà présent en version 2.2) mais je n'ai pratiquement pas testé la 2.2 car la 2.4 Stable est parue peu après mes tests.
Note 2017 : voir tests de la version 3.1.
Les tests de cette version sont présentés dans plusieurs "chapitres" :
- Installation
- Quelques pistes d'exploitation des données :
NtopNG version 2.4 : Installation
NtopNG version 2.4 : Installation jppTélécharger la version 2.4 Stable par :
https://sourceforge.net/projects/ntop/files/ntopng/ntopng-2.4-stable.tar.gz/dow…
Les pré-requis de la 2.2 (voir article précédent) sont déjà installés, on va essayer de compiler la 2.4 directement :
./autogen.sh
Qui se passe bien et nous invite à lancer "configure".
./configure 2>&1 | tee LOG.CONFIGURE
Qui semble se dérouler sans accroc et nous rappelle de lancer "make geoip" avant d'utiliser le logiciel. On le lance tout de suite pour être sûr de ne pas oublier ! Cela se dépêche de charger les fichiers de maxmind (IPV4 et IPV6), puis on lance le make final :
make 2>&1 | tee LOG.MAKE
Et ... tout se termine correctement.
Donc si vous avez installé les pre-requis de la version 2.2 il n'y aura probablement aucun problème lors de la compilation.
Avant de lancer la nouvelle version on détruit les tables de notre user "NtopNG" de la base Mysql car ce n'est pas la meme structure de tables (1 table par interface en 2.2) et quelques champs supplémentaires.
Comme indiqué en fin de compilation il est aussi possible de générer un paquet (RPM ou DEB) et cette option est même conseillée. A part un petit problème avec la "clef" qui déclenche une petit erreur, le package Debian se génère parfaitement et je l'ai installé sur une autre machine. Je vous conseille cette méthode, tout est expliqué dans le message ... :
cd packages/ubuntu
./configure
make
........
Processing ../ntopng_2.4.161017-1373_amd64.deb...
gpg: error reading key: public key not found
gpg: no default secret key: secret key not available
gpg: /tmp/debsigs-ng.eP5yVK/digests: clearsign failed: secret key not available
E: Signing failed. Error code: 512
Makefile:10: recipe for target 'ntopng' failed
make: *** [ntopng] Error 1
L'erreur ne gêne pas la réalisation du paquet, elle ne concerne que la signature, qui est alors disponible dans le répertoire ".../packages" :
-rw-r--r-- 1 root root 698 oct. 17 22:42 ntopng_2.4.161017-1373_amd64.changes
-rw-r--r-- 1 root root 4903998 oct. 17 22:42 ntopng_2.4.161017-1373_amd64.deb
On peut aussi procéder de manière traditionnelle, un petit "su root" et on lance le non moins traditionnel :
make install 2>&1 | tee LOG.INSTALL
et on relance le service sans changer nos paramètres de la version 2.2 :
service ntopng start
Pour rappel le fichier cd config "/etc/ntopng/ntopng.conf" est minimal :
-G=/var/tmp/ntopng.pid
-F=mysql;localhost;ntopng;flows;userntop;passntop
Le fichier log (/var/log/ntopng/ntopng.log) nous signale que tout va bien et que tous les interfaces sont pris en compte.
Du coté de la base Mysql seules deux tables on été créées :
| show tables; +------------------+ | Tables_in_ntopng | +------------------+ | flowsv4 | | flowsv6 | +------------------+ 2 rows in set (0.00 sec) |
L'analyse sera plus simple qu'en 2.2 car seules deux tables contiennent les données. Changement important dans la structure, les volumes échangés (bytes) sont subdivisés en IN_BYTES et OUT_BYTES.
Les interfaces étant en mode "promiscuous" tous les paquets passant sur le réseau aux alentours de vos interfaces sont enregistrés.
La zone "INFO" contient souvent des infos intéressantes, notamment pour le protocole DNS. Le champ INTERFACE_ID permet de repérer les différents interfaces, le champ NTOPNG_INTERFACE_NAME contient le nom de la machine d'origine, on pourra ainsi utiliser une seule base Mysql pour plusieurs capteurs NtopNG. Le numéro de VLAN est enregistré, ici c'est toujours zéro car je n'utilise pas de VLAN sur mon tout petit réseau.
Pour le champ "PROTOCOL" c'est le standard (TCP = 6, UDP = 17, ICMP = 1) on trouve cela dans tous les bons Wikipedia.
Attention, le volume de données dans la base est assez conséquent, sur un réseau un peu fréquenté on dépassera rapidement les 200 000 rangs prévoir le stockage adéquat !
Il faudra aussi prévoir une petite purge des tables au cas ou celle de Ntop ne soit pas suffisante. Il faut ensuite faire un peu de SQL pour exploiter les données enregistrées.
Après quelques minutes d'activité vous devriez voir quelques rangs dans votre base Mysql, pour commencer essayez le scripts SQL suivant :
| select inet_ntoa(IP_SRC_ADDR) as IP_SRC, inet_ntoa(IP_DST_ADDR) as IP_DST,L4_DST_PORT, sum(IN_BYTES) as IN_BYTES,sum(OUT_BYTES) as OUT_BYTES,PACKETS from flowsv4 where IP_DST_ADDR not in (inet_aton('127.0.0.1'),inet_aton('192.168.1.31') ) group by IP_SRC_ADDR, IP_DST_ADDR,L4_DST_PORT order by IP_SRC |
ou encore celui-ci :
| SELECT INTERFACE_ID,L7_PROTO,inet_ntoa(IP_SRC_ADDR) as IPSRC,L4_SRC_PORT, inet_ntoa(IP_DST_ADDR) as IP_DST,L4_DST_PORT, IN_BYTES,OUT_BYTES,PACKETS, FROM_UNIXTIME(FIRST_SWITCHED),FROM_UNIXTIME(LAST_SWITCHED), INFO,JSON FROM ntopng.flowsv4 order by FIRST_SWITCHED,IP_SRC_ADDR |
qui devraient vous afficher les résultats de manière claire et avec des adresses lisibles !
NtopNG : Myisam à Innodb
NtopNG : Myisam à Innodb jppNote : valable aussi en V2.4 et V3.0.
Les deux tables créées par NtopNG sont d'office en MyISAM, si, comme moi, vous avez d'autres tables en InnoDB dans votre base vous allez vouloir profiter des buffers de InnoDB pour vos traitements.
Par ailleurs, en cas de crash, InnoDB est plus "sûr" que MyISAM.
Mais, car il y a un "mais", si vous faites cette modification "à la main" pour passer les deux tables de MyISAM en InnoDB, ce qui est simple, un simple "alter table truc engine = innodb" ne suffit pas !
Si vous le faites, NtopNG s'empressera lors du prochain démarrage de repasser la table en MyISAM ! Et ce sans rien vous demander.
La seule manière pour réaliser l'exploit de passer en InnoDB est d'aller modifier les sources du paquet.
Le module "MySQLDB.cpp" vous tend les bras dans le répertoire "src". Il suffit de modifier quelques constantes "MyISAM" --> "InnoDB" aux environs de la ligne 310 pour ressembler à ceci :
|
// Modify database engine to MyISAM (that is much faster in non-transactional environments) ntop->getTrace()->traceEvent(TRACE_NORMAL, snprintf(sql, sizeof(sql), |
Après une petite recompilation et la régénération du paquet on ré-installe et au premier démarrage nos tables sont migrées en InnoDB, automatiquement et sans rien demander !
Attention; si vos tables sont un peu volumineuses, cela dure un certain temps ! Et demande de l'espace disque (environ le double de l'espace occupé par la table MyIsam.
NtopNG : début d'analyse des données
NtopNG : début d'analyse des données jppJ'ai installé NtopNG, par le paquet Debian généré lors de la compilation, sur la machine qui me sert de frontal internet et j'ai commencé à analyser un peu les données enregistrées. D'abord, ça crache épais, je suis actuellement seul à la maison et donc le trafic est un peu réduit. Quelques procédures exemples sont téléchargeables en fin de page.
Le petit ordre SQL suivant donne un comptage sans prétentions :
| SELECT DAY(from_unixtime(FIRST_SWITCHED)),count(*) FROM ntopng.flowsv4 group by 1 |
Ramène :
2 22037
3 77469
On est le 3 août vers 20h00 et j'ai démarré le zinzin hier soir, j'ai bossé toute la journée ... et quand même plus de 100000 flux enregistrés !
J'ai aussi extrait les adresses IP et j'ai crée une table IP,PAYS,AS,nom de domaine (voir en fin de page les liens de téléchargement) .... sur ces deux jours j'ai déjà "repéré" plus de 1700 adresses différentes ... provenant de 88 pays. Quand on parle de mondialisation ...
Bien sûr certains pays sont représentés par une seule adresse. Le petit tableau suivant montre les pays pour lesquels j'ai "collecté" plus de 10 adresses ... :.
|
PAYS |
count(*) |
|
US |
535 |
|
CN |
133 |
|
FR |
122 |
|
VN |
94 |
|
BR |
94 |
|
RU |
79 |
|
KR |
64 |
|
TW |
63 |
|
NL |
60 |
|
IN |
36 |
|
EU |
34 |
|
DE |
30 |
|
JP |
28 |
|
RO |
24 |
|
CO |
22 |
|
TR |
21 |
|
MX |
17 |
|
UA |
16 |
|
ES |
13 |
|
PL |
12 |
|
GB |
12 |
|
CA |
12 |
|
ID |
12 |
|
IT |
10 |
C'est déjà pas mal.
Les Chinois, les russes et les vietnamiens sont systématiquement bloqués par le pare-feu, mais NtopNG enregistre toutes les connexions. Attendons 23:59 pour avoir une journée complète.
Il est 23:59, statistique sur une journée complète.
Visiblement il n'y a pas d'heures pour les braves, il y en a toute la journée.
Télécharger les scripts :
La création de la table IPV4_DOMAINE, renommez le en ".sql" pour faire bien !
La création des index complémentaires sur la table "flowsv4", idem pour le ".sql"
Le script bash "MAJ_DOMAINE" à renommer en .sh (nécessite le script DNS_RES)
Le script bash DNS_RES à renommer en .sh, qui cherche les PAYS,noms DNS, FAI à intégrer dans la base.
Ce dernier script nécessite l'installation des outils "geoip".
NtopNG : version 3.1
NtopNG : version 3.1 jppNote Avril 2018 : voir l'article sur la version 3.5.
Note décembre 2017 : cet article reste valable pour les versions 3.2 et 3.3.
Depuis quelques temps chaque connexion à l'interface WEB de NtopNG me rappelle qu'il existe une version 3.x ... que je vais essayer d'installer et de tester.
Pour mémoire paquets de dev installés pour la V2.4 :
apt-get install build-essential git bison flex libglib2.0 libxml2-dev libpcap-dev libtool rrdtool librrd-dev autoconf automake autogen redis-server wget libsqlite3-dev libhiredis-dev libgeoip-dev libcurl4-openssl-dev libpango1.0-dev libcairo2-dev libpng-dev libmysqlclient-dev libnetfilter-queue-dev libmysqlclient-dev zlib1g-dev libzmq3-dev
A priori quelques nouvelles bibliothèques ou include de développement a résoudre par :
apt-get install default-libmysqlclient-dev libmariadbclient-dev libmariadbclient-dev-compat libpng-dev libcap-dev libldap2-dev
En principe mes systèmes sont "à jour" de la dernière version.
Par contre, pas de "tar.gz" à télécharger directement, tout passe par clonage de dépots "git".
Créer un répertoire de compilation, par exemple "ntopng-3.0" dans un endroit tranquille, ici /usr/src/PGM/BUILD.
Attention à l'ordre des opérations !
On récupère les sources de nDPI dans le dépot github :
| cd le_répertoire_de_compilation git clone https://github.com/ntop/nDPI.git |
On les compile :
| cd nDPI ./autogen.sh 2>&1 | tee LOG.AUTOGEN ./configure 2>&1 | tee LOG.CONFIGURE make 2>&1 | tee LOG.MAKE |
La lecture des fichiers résultats permet de repérer les erreurs éventuelles.
Pour moi, tout s'est bien passé ...
Si chacune des deux étapes s'est exécutée sans erreurs on peut passer à la suite.
Récupérer les sources de Ntop :
| cd le_répertoire_de_compilation ( ou cd .. si vous étiez dans nDPI) git clone https://github.com/ntop/ntopng.git cd ntopng Ici corriger éventuellement MyISAM --> InnoDB (détails ici). ./autogen.sh 2>&1 | tee LOG.AUTOGEN ./configure 2>&1 | tee LOG.CONFIGURE make 2>&1 | tee LOG.MAKE |
Un petit message en fin d'exécution vous rappelle qu'il faudra charger les données GeoIP :
Please do not forget to download GeoIP databases doing: "make geoip"
On peut même le faire de suite ...
La compilation se passe bien avec juste quelques "warnings" à la fin :
/usr/bin/ld: warning: libssl.so.1.0.2, needed by /usr/lib/x86_64-linux-gnu/libcurl.so, may conflict with libssl.so.1.1
/usr/bin/ld: warning: libssl.so.1.0.2, needed by /usr/lib/x86_64-linux-gnu/libcurl.so, may conflict with libssl.so.1.1
/usr/bin/ld: warning: libcrypto.so.1.0.2, needed by /usr/lib/x86_64-linux-gnu/libcurl.so, may conflict with libcrypto.so.1.1
Effectivement les systèmes Debian actuels disposent aujourd'hui de trois versions de libssl et libcrypto (1.0.0, 1.0.2 et 1.1), ce qui pourrait poser parfois des problèmes.
Mais peut-être plus grave les warnings suivants :
src/Utils.cpp:1468:67: warning: ‘int readdir_r(DIR*, dirent*, dirent**)’ is deprecated [-Wdeprecated-declarations]
for (ret = readdir_r(d, &entry, &result); result && !ret; ret = readdir_r(d, &entry, &result)) { ^~~~~~~~~
In file included from /usr/include/features.h:364:0,
from /usr/include/stdio.h:27,
from /usr/src/PGM/BUILD/ntopng-3.0/ntopng/include/ntop_includes.h:33,
from src/Utils.cpp:22:
/usr/include/dirent.h:189:12: note: declared here
extern int __REDIRECT (readdir_r,
Il est possible que vous obteniez, comme moi, des messages lors du "make" tels que :
"aclocal-1.11: command not found"
En effet Debian Stretch est construit avec aclocal-1.15, une solution brutale :
sudo ln -s /etc/alternatives/aclocal /usr/bin/aclocal-1.11
Lorsque vous exécuter le fatidique "make install 2>&1 | tee LOG.INSTALL"
- Le binaire "ntopng" est copié dans /usr/local/bin
- On vous rappelle de faire un "make geoip"
- On vous donne au passage la méthode pour réaliser un RPM ou un DEB :
rpm - do 'make build-rpm'
deb - do 'cd packages/ubuntu;./configure;make
Si vous voulez créer un paquet Debian il faudra installer le paquet "dpkg-sig" ou modifier le Makefile.in en commentant les lignes "dpkg-sig .....".
J'ai ensuite généré le package Debian, et obtenu deux paquets :
ntopng_3.1.171028-3630_amd64.deb
ntopng-data_3.1.171028_all.deb
Que je me suis empressé d'installer, sans succès car il me manque "PF_RING" !
Remarque : les fichiers "GeoIP" sont chargés et installés dans le paquet "data". Il faudra néanmoins penser à les rafraîchir de temps en temps.
Note : après usage NtopNG recharge régulièrement les données pour les "blacklisted hosts", je n'ai pas vu de rechargement des données GeoIP --> les rafraîchir ne peut pas faire de mal !
J'ai téléchargé un stock de ".deb" depuis :
http://packages.ntop.org/debian/stretch/x64/PF_RING
J'ai téléchargé le paquet le plus récent : pfring_7.1.0-1515_amd64.deb
qui dépends de pfring-dkms-7.1.0 que l'on peut charger avec :
http://packages.ntop.org/ubuntu/16.04/all/PF_RING-dkms
et prendre la version 7.1.0 compatible avec la précédente. Son installation génère un module de kernel qui est installé dans la foulée, on peut alors installer "pfring_7.1.0-1515_amd64.deb" puis les deux paquets "ntopng".
Le lancement semble OK et le port HTTP (3002 pour moi) est activé.
Vite quelques essais !
Ntopng 3.1 tests
Ntopng 3.1 tests jppAvant le premier lancement il est conseillé de lire la doc .... surtout s'il s'agit d'une nouvelle version majeure comme ici.
Après vérification du format des paramètres (il ne semble pas avoir changé) dans la doc PDF fournie parmi les sources (doc/UserGuide.pdf) je m'aperçois que pas grand chose n'est changé. A part une possibilité de permettre une connection sans user/password pour tout le monde ou pour "localhost" seulement, je mets donc "--disable-login=1" dans le fichier paramètres puisque l'interface n'est accessible que sur le réseau interne.
Je lance donc NtopNG et me connecte sur http://localhost:3002 avec Firefox et j'obtiens un beau message :
Database schema migration in progress, waiting for database ntopng to become operational. You will be redirected as soon as the database is ready. Depending on the size of the existing database, this operation can take a long time. Migrations are performed only once and only during major version upgrades. If in doubt, please contact the developers at info@ntop.org.
J'attends quelque peu en examinant le log dans /var/tmp/ntopng/ntopng.log et j'y trouve, entre autres,
MySQL schema update. Altering table flowsv4: changing OUT_BYTES data type to unsigned int.
Après quelques instants je relance la connexion et miracle ... j'accède à l'interface.
Il est recommandé d'aller faire un tour dans les préférences pour régler l'application, notamment la durée de conservation des données et un certain nombre d'options.
A première vue cela ressemble beaucoup à l'ancien interface, mais en regardant d'un peu plus près il y a beaucoup de nouveautés. Par exemple dans les "flows" les connexions provenant de certaines IP sont signalées d'une petite étiquette rouge "blacklisted host" et on retrouve cette indication dans les alertes. Ces "blacks IP" sont reconnues d'après les données du site EmergingThreats (http://rules.emergingthreats.net).
Le "traffic dashboard" est plein d'options intéressantes :
- "Hosts" : camembert des "top hosts"
- "Ports" : deux camemberts sur les ports utilisés (client et serveur).
- "Applications" : camembert sur les protocoles utilisés.
Le menu "Hosts" offre (les adresses sont suivies du drapeau de chaque pays) :
- "Hosts", avec option de tri par clic sur les en têtes de colonnes, ici aussi les "blacklisted hosts" sont signalés.
- "Networks" : liste condensée des réseaux, cliquer sur "Remore Networks" pour obtenir le détail.
- "host pools" : lié à la possibilité d'attribuer chaque adresse à un "pool", attention le nombre de pools et d'adresses par pool sont limités (au moins dans la version "open".
- "Autonomous Systems" : tri par AS avec possibilité d'obtenir un graphe du débit sur chaque AS, les graphes sont "cliquables" pour zoomer ! La granularité du graphe va de 5minutes à 1 an ! On peut ici obtenir les flows correspondant à cet AS.
- "Countries" : comme son nom l'indique.
- "Operating system" : le seul repéré est mon téléphone ??? A suivre.
- "Geomap" : nécessite d'avoir été compilé avec une option spéciale ... et éventuellement une clé API Google.
- "Local flow matrix" : comme son nom l'indique une matrice des flux locaux.
Dans les "outils" l'option "Export Data" permet de récupérer les données au format JSON qui contient énormément d'informations dont je n'ai pas fait l'inventaire car le format a l'air assez complexe.
Autres possibilités :
- Déclencher des alertes sur certaines conditions.
- Propager des alertes sur "Slack".
- Dump paramétrable de flux.
En bref, énormément de possibilités de visualisation de ce qui passe dans les tuyaux.
Notes :
- Attention à l'espace disque (RRDs dans /var/tmp/ntopng et Mysql) et à la charge de la base Mysql/MariaDB, bien ajuster la durée de conservation à vos besoins. Si vous souhaitez garder un historique long (des mois ...) de la base Mysql faites le sur une autre machine avec report périodique automatisé.
- J'ai du désactiver "Network Discovery" car j'ai utilisé la possibilité de lancer NtopNG en non-root sur un user "ntopng" disposant de peu de droits. Network Discovery me générait des erreurs dans les logs '" :
[NetworkDiscovery.cpp:48] ERROR: Unable to create pcap socket [1/Operation not permitted]
ou encore :
ntopng: [Lua.cpp:2147] ERROR: Unable to enable capabilities
Je dois investiguer l'origine de ce message.
NtopNG : utilisateur non root
NtopNG : utilisateur non root jppSi vous voulez que NtopNG soit lancé en utilisateur non privilégié il faut utiliser l'option :
"--user=....".
J'ai donc créé un user "ntopng" du même groupe sans droits particuliers. Il ne faut dans ce cas pas oublier d'adapter les droits sur le répertoire de travail de NtopNG :
cd /var/tmp chown -R ntopng:ntopng ntopng chmod -R 755 ntopng
Toutefois cette possibilité déclenche des erreurs telles que :
[Lua.cpp:2147] ERROR: Unable to enable capabilities
[NetworkDiscovery.cpp:48] ERROR: Unable to create pcap socket [1/Operation not permitted]
[NetworkDiscovery.cpp:231] ERROR: MDNS Send error [1/Operation not permitted
[NetworkDiscovery.cpp:261] ERROR: Send error [1/Operation not permitted]
J'ai du désactiver l'option "Network Discovery" en attendant de trouver une solution car OSSEC me signalait chacune de ces erreurs ... toutes le 15 minutes et OSSEC envoyait un message d'alerte à ce sujet.
Recherche en cours (problème de "capabilities" ? Lié à libcap ?).
Finalement le problème s'est réglé tout seul ?
NtopNG : version 3.5
NtopNG : version 3.5 jppCompilation de NTOPNG 3.5, dernière version issue du git du projet (2018/03).
Mon installation est toujours en version 3.3, mais à chaque connexion sur l'interface je reçois un message m'invitant à installer la version 3.4 stable. J'ai donc décidé d'installer la dernière version, je décris ci-après les opérations exécutées.
Créer un répertoire "ntopng-3.5".
cd ntopng-3.5
Exécuter le script en annexe (ici), d'abord en mode "LOAD", effectuer les modifications nécessaires (Makefile).
Dans ntopng-3.5/ntopng/packages/ubuntu je modifie le fichier "Makefile" en commentant les appels à "dpkg-sig" pour éviter les problèmes de signature d'un package "officiel".
On peut ensuite lancer le script en mode "COMPILE".
En fin de compilation un warning sur les librairies "ssl" et "crypto" car NtopNG utilise encore des version "anciennes" :
| /usr/bin/ld: warning: libssl.so.1.0.2, needed by /usr/lib/x86_64-linux-gnu/libcurl.so, may conflict with libssl.so.1.1 /usr/bin/ld: warning: libssl.so.1.0.2, needed by /usr/lib/x86_64-linux-gnu/libcurl.so, may conflict with libssl.so.1.1 /usr/bin/ld: warning: libcrypto.so.1.0.2, needed by /usr/lib/x86_64-linux-gnu/libcurl.so, may conflict with libcrypto.so.1.1 |
Vérifier que les versions 1.0.2 et 1.1 sont bien présentes sur mon système :
| cd /usr/lib/x86-64 find ./ -name 'libssl*so*1.0.2' ./libssl.so.1.0.2 find ./ -name 'libcrypto*so*1.0.2' ./libcrypto.so.1.0.2 |
Ne pas oublier de faire un :
| cd ntopng-3.5/ntopng make geoip |
avant de lancer la création du package.
Ah, j'oubliais, corriger le fichier 'ntopng.service' du répertoire "ntopng-3.5/ntopng/packages/ubuntu/debian.ntopng/ntopng/etc/systemd/system" (car le standard "traîne" à l'arrêt durant au moins 1 minute 30) :
Avant :
| [Service] Type=simple ExecStartPre=/bin/sh -c '/bin/sed "/-e.*$\\|-G.*\\|--daemon.*\\|--pid.*/s/^/#/" /etc/ntopng/ntopng.conf > /run/ntopng.conf' ExecStart=/usr/local/bin/ntopng /run/ntopng.conf ExecStopPost=-/bin/rm -rf /run/ntopng.conf Restart=on-abnormal RestartSec=5 |
Après :
| [Service] Type=simple ExecStartPre=/bin/sh -c '/bin/sed "/-e.*$\\|-G.*\\|--daemon.*\\|--pid.*/s/^/#/" /etc/ntopng/ntopng.conf > /run/ntopng.conf' ExecStart=/usr/local/bin/ntopng /run/ntopng.conf ExecStopPost=-/bin/rm -rf /run/ntopng.conf Restart=always RestartSec=5 TimeoutStartSec=10 TimeoutStopSec=10 |
On peut maintenant générer les paquets Debian, il doit en être de même pour d'autres distributions mais le fichier "ntopng.service" n'est pas placé dans le même répertoire. Il faut aussi commenter les appels à "dpkg-sig" dans le fichier "ntopng-3.5/ntopng/packages/debian/Makefile.in" car nous ne disposons pas de clefs Debian/Ubuntu.
| cd package/debian ./configure make 2>&1 | tee MAKE.LOG |
Après quelques instants deux paquets sont disponibles dans "ntopng-3.5/ntopng/packages/debian" :
| ls -al ntop* -rw-r--r-- 1 jppRR jppRR 4937636 avril 24 11:29 ntopng_3.5.180424-4347_amd64.deb -rw-r--r-- 1 jppRR jppRR 23997248 avril 24 11:29 ntopng-data_3.5.180424_all.deb |
Il ne resta plus qu'à les installer ... avec sudo bien sûr :
|
sudo dpkg -i ntopng*deb Configuration file '/etc/ntopng/ntopng.conf' |
Et maintenant le moment de vérité ! Je lance un browser sur "localhost:3002" (3002 chez moi, voir paramétrage du fichier /etc/ntopng/ntopng.conf) et magnifique ... tout apparaît normal, même les alertes générées par la version précédente sont présentes et un petit tour dans le panneau hosts/hosts montre une liste complète.
Du coté de la base de données les nouvelles connexions sont bien enregistrées.
Tout ceci a été réalisé sur une machine de test, il ne reste plus qu'à installer les deux paquets sur une "vraie" machine ... et cela fonctionne aussi bien.
Autre vérification : le plugin NtopNG de Grafana fonctionne normalement.
Version parfaitement compatible, au niveau des données, avec les précédentes de la série 3.x.
Télécharger mon script de compilation.
Scripts SQL simples
Scripts SQL simples jppQuelques scripts permettant de répondre à quelques questions simples sur ce qui "passe" sur votre réseau.
Qu'a fait l'adresse XXX.XXX.XXX.XXX ?
Avec appoint de la table personnelle IPV4_DOMAINE, cf en fin de page pour le téléchargement des scripts).
| SELECT FW.INTERFACE_ID NIC,inet_ntoa(FW.IP_SRC_ADDR) SRCIP ,FW.L4_SRC_PORT SPORT, inet_ntoa(FW.IP_DST_ADDR) DSTIP,FW.L4_DST_PORT DPORT, FW.PROTOCOL TCPIP, FW.IN_BYTES, FW.OUT_BYTES,FW.PACKETS, DATE_FORMAT(FROM_UNIXTIME(FW.FIRST_SWITCHED), '%H:%i:%s %d-%m-%Y') DEBUT, DATE_FORMAT(FROM_UNIXTIME(FW.FIRST_SWITCHED), '%H:%i:%s %d-%m-%Y') FIN, FW.INFO,DO.CODPAYS,DO.SRV,DO.DOM,DO.COMPAGNIE FROM ntopng.flowsv4 FW left join ntopng.IPV4_DOMAINE DO on ( FW.IP_SRC_ADDR = DO.IP_V4 or FW.IP_DST_ADDR = DO.IP_V4= where ( FW.IP_SRC_ADDR = inet_aton('XXX.XXX.XXX.XXX') or FW.IP_DST_ADDR = inet_aton('XXX.XXX.XXX.XXX') ) and FW.L4_DST_PORT != 123 order by 10 limit 32 |
Bien sûr la clause "limit 32" peut être modifiée ! Pour voir plus de 32 heureux sélectionnés.
Plus simple une statistique par jour.heure :
| select (DATE_FORMAT(FROM_UNIXTIME(FIRST_SWITCHED),'%Y-%m-%d')) jour, (DATE_FORMAT(FROM_UNIXTIME(FIRST_SWITCHED),'%H')) heure,count(*) from ntopng.flowsv4 group by 1,2 |
Plus drôle (??), quels sont les ports des visiteurs classés en décroissant :
| SELECT FW.L4_SRC_PORT, count(*) FROM ntopng.flowsv4 FW where FW.IP_SRC_ADDR <> inet_aton('127.0.0.1') and FW.IP_SRC_ADDR not between inet_aton('192.168.1.0') and inet_aton('192.168.3.255') and FW.IP_DST_ADDR not between inet_aton('224.0.0.1') and inet_aton('224.255.255.255') and FW.IP_DST_ADDR not between inet_aton('239.0.0.1') and inet_aton('239.255.255.255') and FW.IP_DST_ADDR <> inet_aton('255.255.255.255') group by 1 order by 2 desc |
Celui-ci utilise aussi la table "IPV4_DOMAINE" que j'ai créée pour conserver les renseignements sur les IP que l'on retrouve dans les DNS et avec "geoiplookup". (Des liens de téléchargement des procédures en fin de la page suivante) :
| select inet_ntoa(FW.IP_DST_ADDR) DSTIP,FW.L4_DST_PORT DPORT,inet_ntoa(FW.IP_SRC_ADDR) SRCIP,FW.INTERFACE_ID ETH, DATE_FORMAT(FROM_UNIXTIME(FW.FIRST_SWITCHED), '%Y-%m-%d') DEBUT,FW.INFO,DO.CODPAYS, sum(FW.IN_BYTES) INB,sum(FW.OUT_BYTES) OUTB,sum(FW.PACKETS) PAQ, DO.CODPAYS,DO.SRV,DO.DOM,DO.COMPAGNIE from ntopng.flowsv4 FW left join ntopng.IPV4_DOMAINE DO on FW.IP_DST_ADDR = DO.IP_V4 where FW.IP_DST_ADDR not between inet_aton('127.0.0.1') and inet_aton('127.255.255.255') and FW.IP_DST_ADDR not between inet_aton('192.1.0.1') and inet_aton('192.168.3.255') and FW.IP_DST_ADDR not between inet_aton('224.0.0.1') and inet_aton('224.255.255.255') and FW.IP_DST_ADDR not between inet_aton('239.0.0.1') and inet_aton('239.255.255.255') and FW.IP_DST_ADDR <> inet_aton('255.255.255.255') group by 1,2,3,4,5,6 order by IP_DST_ADDR,L4_DST_PORT,3 |
Pour rendre les listes plus lisibles ajoutez une table "PAYS" :
| CREATE TABLE PAYS ( CODPAYS char(2) NOT NULL DEFAULT '', CODPAYS_3 char(3) DEFAULT NULL, ENG_NAME varchar(40) DEFAULT NULL, FR_NOM varchar(40) DEFAULT NULL, PRIMARY KEY (CODPAYS) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; |
Cette table est disponible en téléchargement pour MySQL/MariaDB.
Allez, cela suffit pour aujourd'hui !
NtopNG : plugin Grafana
NtopNG : plugin Grafana jppPlugin NtopNG pour Grafana.
Note 2019 : ce plugin n'est plus maintenu et ne fonctionne plus avec les versions récentes de Grafana. Pour utiliser les données de NtopNG dans Grafana voir ICI.
Ce plugin permet l'accès aux données de NtopNG par Grafana en tant que "datasource".
Installer le plugin.
Dans la machine "supportant" Grafana lancer la commande :
grafana-cli plugins install ntop-ntopng-datasource
installing ntop-ntopng-datasource @ 1.0.0
from url: https://grafana.com/api/plugins/ntop-ntopng-datasource/versions/1.0.0/download
into: /var/lib/grafana/plugins
Failed downloading. Will retry once.
✔ Installed ntop-ntopng-datasource successfully
Pour vérification : ls -al /var/lib/grafana/plugind montre un répertoire ntop-ntopng-datasource.
Puis "systemctl restart grafana-server" et connexion à Grafana.
Menu Datasource --> Add data source.
Dans la boîte de dialogue "Type" on trouve bien "ntopng" que l'on sélectionne, pour le reste voir l'image écran suivante : 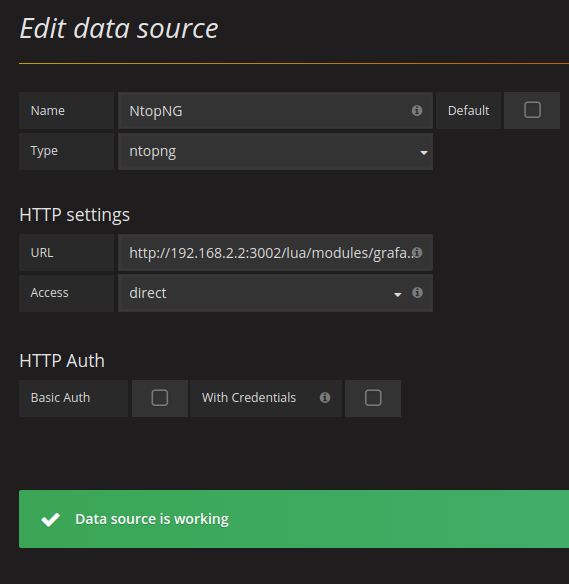
Pour créer un graphique dans Grafana c'est assez standard sauf pour une chose : la boite de sélection des métriques.
NtopNG propose deux types de métrique : "host" et "interface" mais la boite de dialogue ne présente pas l'intégralité des données il faut fournir au moins le début du critère recherché afin de préciser l'affichage. L'affichage original commence par les données "host" et ne les montre même pas toutes et sans tri apparent, il faut frapper "host_" suivi du début de l'adresse IP pour limiter l'affichage et pouvoir choisir ce que l'on désire.
Pour voir les métriques "interface" il faut frapper "i" pour voir apparaître la liste et effectuer son choix.
Certaines métriques donnent un message "Data points outside time range", ceci concerne notamment les métriques "total_packets" et "total_bytes". Les métriques "pps" (paquets) et "bps" (bytes), elles, fonctionnent normalement. Beaucoup de métriques "host" retournent "No data points", c'est le cas de nombreuses adresses n'ayant eu que peu de trafic, par contre pour les machines locales ou connectées souvent les indications semblent fiables.
On peut ainsi présenter des graphes de débit réseau de machines ne possédant pas de "senseur", le débit est celui constaté sur la machine équipée de NtopNG (en général la passerelle Internet).
A noter pour les interfaces une métrique "allprotocols_bps" présente des graphes pour les principaux types de flux : SSL, HTTP, SNMP,Google, SSH ...
Remarque : l'utilisation d'échelles "log" est souvent nécessaire pour garder mieux voir les grandes variations de débit.
Exemple de graphes "réseau" issus des données de NtopNG, au passage ces graphes sont effectués avec la version 5 de Grafana qui s'est installée sans douleur. 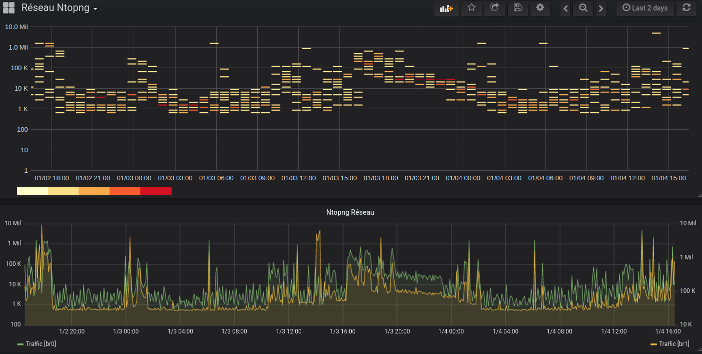
Les graphiques sont presque aussi beaux que ceux obtenus avec Omeganoc.
Prometheus/Grafana
Prometheus/Grafana jppJ'ai décidé de tester Prometheus qui semble un bon outil de monitoring et surtout est maintenu au goût du jour.
L'installation par défaut est faite dans une machine virtuelle KVM avec :
- RAM : 2048M
- VCPU : 2
- Disk : 32Go
- Debian Bookworm
Afin d'obtenir de "beaux" dashboards Grafana sera installé sur cette même machine, je vais essayer par ailleurs l'installation d'un "exporteur" de données Mysql/MariaDB pour voir comment surveiller des bases de données avec ces outils.
Note : il existe de ces exporteurs pour la plupart des bases de données : Postgresql, MongoDB ... Je me limiterai à Mysql/MariaDB dans un premier temps.
Je vais aussi jeter un oeil sur un exporteur "Apache" sans oublier bien sûr l'exporteur principal : le "node-exporter" qui présente un grand nombre de métriques sur n'importe quel système.
Prometheus installation
Prometheus installation jppLe logiciel est disponible dans les paquets standards de Debian, donc l'installation se passe bien avec le téléchargement d'un certain nombre (grand nombre même) de dépendances.
Avec cette installation "brute" aucune mesure d'une autre machine n'est visible , ici la machine "personnelle" en ajoutant quelques lignes dans le fichier "/etc/prometheus/prometheus.yml" :
- job_name: k2000
# If prometheus-node-exporter is installed, grab stats about the local
# machine by default.
static_configs:
- targets: ['192.168.2.8:9100']Pour que cela fonctionne il faut installer un "prometheus-exporter" sur cette machine ce qui ne pose aucun problème sur cette machine Debian. Quelques minutes plus tard des mesures commencent à être visibles.
Ce qui est très ennuyeux avec Prometheus c'est l'utilisation de ce fichier de paramétrage relativement "monolithique" qui peut (doit) devenir difficile à gérer !
On peut tester rapidement le fonctionnement sur le port 9090, il faudra bien sûr attendre un certain temps que des mesures soient disponibles.
L'interface "standard" n'est pas très "sexy" mais elle permet de voir le grand nombre de données différentes disponibles. Il est possible d'afficher des graphes simplifiés d'une mesure, mais ce n'est pas l'interface à utiliser couramment, par contre c'est un bon moyen de voir l'ensemble des mesures disponibles en standard, il y en a énormément dont un certain nombre qui restent incompréhensibles pour moi ...
La plupart des mesures présentées dans la liste sont en fait "multiples", par exemple la mesure "node_disk_io_now" présente par défaut l'ensemble des disques physiques et des partitions LVM présentes dans la machine.
Cet interface permet aussi de consulter différents aspects :
- Les alertes (je n'en ai pas encore installé une)
- Visualiser quelques mesures (une à la fois)
- Afficher le paramétrage "basique" de Prometheus.
Pour afficher des graphiques plus "jolis", et surtout des "dashboard" synthétiques plus représentatifs de l'activité d'un service, l'installation de Grafana s'impose.
Pour installer Grafana il est suffisant (Debian) d'ajouter un fichier "grafana.list" dans "/etc/apt/sources.list.d" contenant :
deb https://apt.grafana.com stable mainPuis récupérer et installer la clef GPG :
wget -q -O /usr/share/keyrings/grafana.key https://apt.grafana.com/gpg.key
cd /etc/apt/trusted.gpg.d
ln -s /usr/share/keyrings/grafana.key ./grafana.ascOn peut alors lancer l'installation, ensuite Grafana-server démarre sans problème et la "data source" Prometheus est comprise d'office. On peut donc tout de suite passer aux choses sérieuses.
Attention toutefois à bien paramétrer la datasource sur la machine "Prometheus".
Ici j'ai créé une datasource "Prometheus-1" qui pointe vers la machine locale, comme d'habitude avec Grafana cela n'a rien de complexe. Pour Grafana, je ne connaissais pas la dernière version (9.4) mais l'interface a beaucoup changé et, s'il offre plus de possibilités, il est nettement plus complexe.
La configuration de Prometheus est contenue dans un fichier "YAML" unique qui risque de devenir très vite complètement indigeste et donc une source d'erreur.
A éviter donc ... Et en cherchant un peu on peut trouver sur Github une application dédiée à cette activité : Promgen (peut-être complexe) ou une autre solution à trouver que je vais essayer de mettre en action dans un prochain chapitre.
Prometheus/grafana premiers pas
Prometheus/grafana premiers pas jppDans un premier temps on est un peu effrayé par la complexité et le nombre des métriques disponibles, et, en plus une métrique en cache plusieurs ... par exemple la métrique "node_disk_io_now" "cache" des valeurs pour chaque disque, ci dessous la liste obtenue pour une machine de mon réseau/
node_disk_io_now{device="sda",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="sdb",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="sdc",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="sdd",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="sde",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="sr0",instance="192.168.2.8:9100",job="k2000"}
.......La machine ayant plusieurs grappes "Raid" elles apparaissent aussi dans la liste :
node_disk_io_now{device="md0",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="md1",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="md2",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="md4",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="md5",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="md6",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="md6p1",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="md7",instance="192.168.2.8:9100",job="k2000"}
......Une demande simple dans Grafana de "node_disk_io_now" ramènera un grand nombre de valeurs, et donc de courbes sur le graphe, heureusement "now" renvoie une valeur instantanée, donc pas besoin de fonction pour obtenir une bonne vision de l'activité au cours du temps.
Les données présentées ci-dessus sont limitées à une instance particulière, ici "k2000". Il est bien sûr possible de "filtrer" les données sur une "instance", un "job" et ici un "device". Il est aussi possible d'utiliser la fonction "sum" pour n'obtenir qu'une seule courbe, intéressant par exemple pour le consommation CPU d'une machine multiprocesseurs.
Par ailleurs beaucoup de séries sont en fait des compteurs qui s'incrémentent au fil du temps, la représentation graphique est donc moins "parlante" et se manifeste par une courbe qui "monte" indéfiniment, heureusement les fonctions "rate" (ou "irate") et "delta" (ou "idelta") permettent de mieux représenter la variation des valeurs dans le temps . Les deux fonctions commençant par "i" ne traitent que les deux dernières valeurs de l'intervalle de temps spécifié, les deux autres donnent la différence entre la première et la dernière valeur de l'intervalle de temps spécifié.. Leur forme générique est :
fonction(valeur[intervalle de temps])Il est possible d'imbriquer les fonctions et d'utiliser une fonction "sum(delta(....))".
Une documentation générale sur les fonctions est accessible ICI.
Avant de pouvoir présenter un graphe sur Grafana il faut donc bien réfléchir pour trouver :
- La mesure à utiliser
- Les filtres à appliquer
- La/les fonctions à appliquer aux données pour obtenir un affichage "utile"
L'interface de Grafana (9.5.2 maintenant) est devenu nettement plus complexe que les versions 7 que j'utilisais auparavant pour permettre d'utiliser au mieux les données de Prometheus.
La création d'un dashboard utile est une oeuvre de longue haleine qui nécessite un temps d'apprentissage assez important ne serait-ce que pour trouver la bonne formulation pour obtenir l'information souhaitée ... Nous verrons dans un autre article quelques exemples.
Prometheus après quelques semaines
Prometheus après quelques semaines jppNotions générales.
Les données recueillies par les différents "exporters" sont des données brutes et très basiques, mais très nombreuses et détaillées. Il n'est, en général, pas évident de relier cette information à des notions "connues" telles que le pourcentage de CPU utilisé ou le nombre d'IO par seconde.
De même pour suivre l'activité d'une base de données la recherche des "bons" indicateurs est assez complexe.
Il est intéressant de rechercher des "dashboards" existants pour s'inspirer de leur contenu ou, au moins, mieux comprendre les données disponibles.
Exemple 1.
Par exemple pour le CPU on dispose d'un très grand nombre de données, par ailleurs détaillées par CPU. Pour mesurer l'activité CPU on dispose de deux groupes de valeurs "user" et "nice" détaillées par CPU. Ces valeurs, ici "node_cpu_seconds_total", sont en fait des compteurs qui mesurent un temps total d'usage.
Par exemple pour calculer le % CPU utilisé sur les dernières 120 secondes j'ai utilisé la formule :
sum(rate(node_cpu_seconds_total{job="nom_du_job",mode!="idle"}[120s])) * 100
Cette machine exécutant plusieurs Machines Virtuelles on peut utiliser une formule analogue :
sum(irate(node_cpu_guest_seconds_total{job="nom_du_job", mode!="idle"}[120s])) * 100
qui permet de visualiser le CPU consommé par l'ensemble des MV.
Attention on peut dépasser 100% sur une machine multiprocesseurs à moins de ne multiplier le résultat que par (100 / Nombre_de_threads).
En bref tout ceci est assez complexe il est difficile (et long) de trouver les "bonnes" métriques et de les présenter sous une forme digeste ...
Par contre un peu de recherche permet de trouver la métrique qui vous intéresse particulièrement ...
Il est donc intéressant de rechercher des panneaux "tous faits", il en existe énormément, et éventuellement de les modifier (simplifier ou ajouter) pour ne pas passer un temps très important à la gestion de ces tableaux de suivi de performance.
Grafana permet ici d'obtenir tous les "dashboards" voulus éventuellement personnalisés à souhait.
Il existe de nombreux panneaux "en kit" permettant de bien débuter sans être obligé de se coltiner des tâches relativement complexes de recherche et surtout de "bricolage de formules" pour arriver à ce que l'on veut.
J'aurais bien présenté quelques "dashboards" mais hélas la plupart sont très "volumineux" et nécessitent de "défiler" plusieurs écrans, mais j'en ai trouvé un "petit" très synthétique qui présente quelques données sur une base MarioaDB :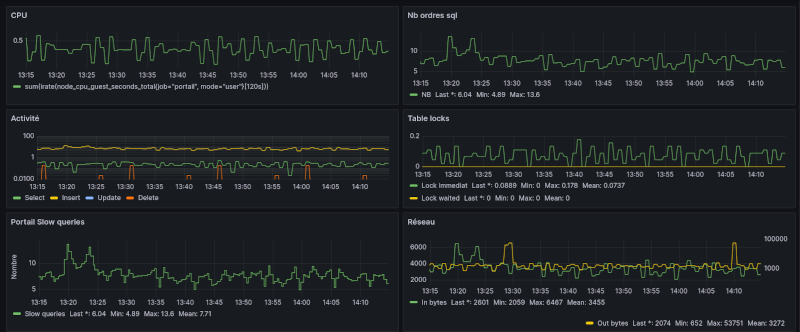
Apache exporter : incident
Apache exporter : incident jppUn petit incident avec prometheus-apache-exporter.
Lors de la migration de la machine supportant ce serveur Web de bullseye à bookworm je n'ai pas vérifié le fonctionnement des modules de prometheus le "node-exporter" et le "mysqld-exporter" se sont lancés normalement et "tournent" correctement, il n'en est pas de même pour "apache-exporter" qui ne se lance plus et on trouve dans les logs un message sibyllin au sujet d'un "flag -t incorrect".
Or la seule ligne de paramètres dans /etc/default/prometheus-apache-exporter est :
ARGS=' -telemetry.address 192.168.2.80:9102 -scrape_uri http://kvm-web.jpp.fr:89/server-status/?auto'
Qui ne montre aucun flag "-t" et qui fonctionnait parfaitement avec la version de l'exporter de bullseye.
Après un peu de réflexion j'ai essayé de doubler les tirets dans le paramétrage :
ARGS=' --telemetry.address 192.168.2.80:9102 --scrape_uri http://kvm-web.jpp.fr:89/server-status/?auto'
et le programme se lance sans erreur.
Effectivement les paramètres "longs" demandent en général un double tiret, mais cela fonctionnait parfaitement avec les versions antérieures ....