THRUK
THRUK jppTHRUK : visualisation de l'état des systèmes supervisés par Shinken ou Nagios.
![]()
Suite à l'installation de Stretch la version précédemment installée a été rendue inopérante .
J'ai donc installé la nouvelle version 2.14 dont les détails sont visibles ici.
Note : à la suite de la migration de Shinken/Omeganoc (changement de MV vers Debian 9) vers Shinken/Influxdb/Grafana j'ai réinstallé THRUK en version 2.18 (15/12/2017) en me servant de mon propre tuto.
Actuellement Thruk est en version 2.26-2 bien au chaud dans sa machine KVM.
THRUK : V2.14 sur Stretch
THRUK : V2.14 sur Stretch jppInstallation de ![]() sur Debian Stretch.
sur Debian Stretch.
Le passage à "Stretch" a "cassé" mon installation de Thruk, j'ai du la supprimer et la recharger.
J'en ai profité pour installer la dernière version : 2.4.12 du 5 mai 2017, 2.16.2 à ce jour (2017/10) automatiquement grâce à l'utilisation du repository de consol.labs.de.
Note juillet 2018 : aujourd'hui automatiquement en version 2.20.2, voir ici un article sur la version 2.20.
Pour les détails voir http://www.thruk.org.
D'abord récupérer les paquets "deb" sur le site https://download.thruk.org/download.html la plupart des distributions en 32 et 64 bits. Bref il y en a pour tous. Je me dirige vers Debian 9 64 bits et je tombe sur 4 paquets :
libthruk_2.14_debian9_amd64.deb 3.6M
thruk-base_2.14-2_debian9_amd64.deb 4.5M
thruk-plugin-reporting_2.14-2_debian9_amd64.deb 17.0M
thruk_2.14-2_debian9_amd64.deb 25K
Avant de les charger et de lire la doc je remarque qu'il existe des repository pour les principales distributions, pour Debian/Ubuntu une ligne à rajouter dans /etc/apt/source_list.d contenant :
"deb http://labs.consol.de/repo/stable/debian stretch main" suffit.
Puisque le créateur a pris la peine de faire des paquets Debian, autant s'en servir ...
Et en plus les mises à jour sont effectuées lors de la mise à jour standard du système, aujourd'hui (25/09/2017) passage sans douleur en 2.16.
Note décembre 2017 : après une ré-installation de Shinken pour ajouter InfluxDB/Grafana (voir ici) j'ai réainstallé Thruk directement depuis le repository de "Consol.de" sans aucune difficulté. Rappel : le port standard du "livestatus" de Shinken est le 50000.
La ligne est ajoutée dans /etc/apt/sources.list
apt-get update
Evidemment la signature des paquets n'est pas reconnue, je l'intègre avec le petit script suivant :
| #!/bin/bash CLE=$1 export CLE echo 'Cle='$CLE echo 'O/N ? ' read CHX case $CHX in o|O) ;; *) exit ;; esac echo 'Extraction clef' gpg --keyserver pgpkeys.mit.edu --recv-key $CLE ret=$? echo 'Ret='$ret gpg -a --export $CLE | apt-key add - ret=$? echo 'Ret='$ret |
La clef ne résiste pas à ce traitement et, pour vérifier, un nouvel apt-get update ne signale aucun message.
Et on charge les paquets :
apt-get install libthruk thruk-base thruk thruk-plugin-reporting
Après 26,4Mo de téléchargement l'installation se lance et s'installe sans aucune question, la fin de la trace suit :
| Setting up libthruk (2.14) ... Processing triggers for systemd (232-25) ... Processing triggers for man-db (2.7.6.1-2) ... Setting up thruk-base (2.14-2) ... thruk plugins enabled: business_process conf minemap mobile panorama statusmap Configuring apache2 vhost ... Module alias already enabled Enabling module fcgid. To activate the new configuration, you need to run: systemctl restart apache2 Considering dependency authn_core for auth_basic: Module authn_core already enabled Module auth_basic already enabled Module rewrite already enabled Enabling conf thruk_cookie_auth_vhost. To activate the new configuration, you need to run: systemctl reload apache2 Thruk have been configured for http://your-server/thruk/. The default user is 'thrukadmin' with password 'thrukadmin'. You can usually change that by 'htpasswd /etc/thruk/htpasswd thrukadmin' Setting up thruk (2.14-2) ... Setting up thruk-plugin-reporting (2.14-2) ... Processing triggers for systemd (232-25) ... |
On lance immédiatement "systemctl reload apache2" puis le browser de son choix et ... on arrive sur l'écran de connexion, thrukadmin/thrukadmin (on le changera plus tard) car on est pressé de voir la nouvelle version à l'oeuvre.
En haut à droite un menu fort sympa nous invite à modifier le mot de passe et à choisir un thème (il y en a 8) et tous ont un aspect agréable.
La première demande envoie sur la configuration de l'accès au "livestatus" :
 |
Une fois rempli, ici le livestatus de Shinken est accessible par le port 50000, un bouton "test" nous tend les bras et se marque en vert dès le clic, puis on valide les changements.
J'aime bien le thème 'classic" mais le "wakizashi" est agréable et très lisible.
Dans les "Current Status" :
"--> Tactical overview" ressemble fort à celle des versions précédentes mais ce n'est pas une critique !
"--> Map", donne toujours un beau dessin et en déplaçant la souris un petit panneau explicatif est affiché.
"--> Hosts", semblable aux derbières versions mais ce n'est pas non plus une critique, ce qui est utile n'a pas forcément besoin d'être modifié profondément.
"--> Host Groups et Service Groups" suscitent la même remarque, la nouveauté est le sous-menu "Mine Map" dans "Service Groups".
 |
"--> Problems" présente peu de modifications par rapport aux versions précédentes.
Dans les "Reports" :
"--> Availability", l'affichage "HTML" me donne une "Internal server error" alors que les autres sorties (xls, csv et json) fournissent des fichiers (xls et csv) ou un affichage (json) qui ont l'air corrects.
"--> Trends" donne le même type de résultats.
"--> Alerts" est impeccable et dispose de belles fonctions "calendrier" pour gérer les intervalles de dates.
"--> Notifications" est OK avec les mêmes possibilités au niveau des calendriers :
 |
"--> Eventlog" permet de rechercher dans les événements (alertes et checks passifs), on peut même exporter le résultat en fichier "xls" que se charge sans problème.
"--> Business Process", dommage , là je n'ai pas de données .
"--> Reporting", je n'ai pas encore inventorié toutes les possibilités de rapport ...
Au niveau "System" tout fonctionne normalement, on peut visualiser la configuration de ses hosts, groupes, services groupes, contacts ... et même les commandes.
La nouveauté dans "Config Tool" est la possibilité d'intégrer des plugins dont le plugin "reports" que je n'ai pas encore vraiment testé.
Télécharger un exemple de rapport "SLA".
Thruk nouveautés version 2.20
Thruk nouveautés version 2.20 jppAujourd'hui lors d'une mise à jour je constate qu'une mise à jour de THRUK est proposée : de 2.18 à 2-20.2.
Les paquets concernés sont : thruk, thruk-base et thruk-reporting.
Après installation il apparaît au moins une nouvelle fonctionnalité :
Création d'un Dashboard personnalisé accessible dans le menu "Panorama" que je n'avais pas encore utilisé.
Cette fonction permet de construire, facilement, une page personnalisée à partir d'éléments préfabriqués par choix dans un menu et positionnement dans la page.
On peut ainsi avoir quelques indicateurs synthétiques ou un "Minemap" détaillé parfait si vous n'avez pas trop de serveurs/services.
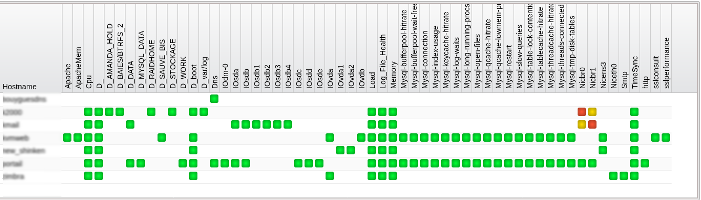
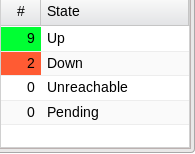
Le tableau "hosts" présente une ligne par machine avec de nombreuses possibilités de filtrage sur le statut des serveurs (UP, Down, Unreachable, Pending) ou sur d'autres caractéristiques : hostgroup, contact, parent, service, servicegroup ....

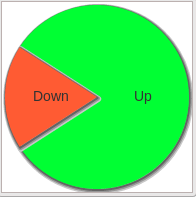
Le tableau "hosts totals" présente une synthèse de l'état des différents serveurs, "hosts graph" présente les mêmes données sous forme de camembert.
| 
|
Il existe le même type de tableau pour les services, ci dessous un exemple du tableau "services" avec un filtrage sur le nom du service, ici "Load".
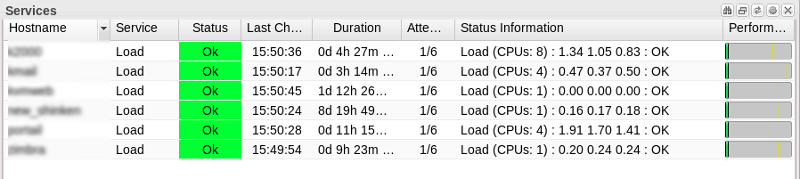
Pour tous les tableaux il est possible de choisir les colonnes affichées, d'utiliser une colonne pour trier le tableau .... la personnalisation est aisée.
J'ai un peu insisté sur cette partie nouvelle et je n'ai aperçu de modifications dans "Reporting", on peut télécharger un exemple de rapport SLA ici.
Pour les autres affichages je n'ai pas noté de différences marquantes mais tout fonctionne à merveille.
Thruk Debian Buster
Thruk Debian Buster jppLors du passage d'une machine utilisant Thruk en Debian 10 "Buster" j'avais complètement oublié d'ajouter le repository de "Consol labs" dans mon nouveau fichier sources-list.
La ligne à rajouter dans le fichier "sources list " standard :
deb http://labs.consol.de/repo/stable/debian/ buster main
Lors de l'installation j'ai eu une erreur :
(Reading database ... 205802 files and directories currently installed.)
Preparing to unpack libthruk_2.30_amd64.deb ...
Unpacking libthruk (2.30) over (2.30) ...
Preparing to unpack thruk-base_2.30-3_amd64.deb ...
cp: cannot stat '/etc/thruk/plugins/plugins-enabled/*': No such file or directory
dpkg: error processing archive thruk-base_2.30-3_amd64.deb (--install):
new thruk-base package pre-installation script subprocess returned error exit status 1
Setting up libthruk (2.30) ...
Errors were encountered while processing:
thruk-base_2.30-3_amd64.deb
J'ai trouvé une solution rapide pour régler le problème :
- Vérifier l'existence du répertoire "/etc/thruk/plugins/plugins-enabled"
- Y créer un fichier "bidon" style "README.txt"
Relancer l'opération (avec --force-install) :
dpkg -i --force-all thruk-base_2.30-3_amd64.deb
Pour moi cela a bien fonctionné et m'a installé une belle version 2.30 ! Que je vais m'empresser de tester dès demain.
PS la 2.30 : fonctionne fort bien ...