Prometheus/Grafana
Prometheus/Grafana jppJ'ai décidé de tester Prometheus qui semble un bon outil de monitoring et surtout est maintenu au goût du jour.
L'installation par défaut est faite dans une machine virtuelle KVM avec :
- RAM : 2048M
- VCPU : 2
- Disk : 32Go
- Debian Bookworm
Afin d'obtenir de "beaux" dashboards Grafana sera installé sur cette même machine, je vais essayer par ailleurs l'installation d'un "exporteur" de données Mysql/MariaDB pour voir comment surveiller des bases de données avec ces outils.
Note : il existe de ces exporteurs pour la plupart des bases de données : Postgresql, MongoDB ... Je me limiterai à Mysql/MariaDB dans un premier temps.
Je vais aussi jeter un oeil sur un exporteur "Apache" sans oublier bien sûr l'exporteur principal : le "node-exporter" qui présente un grand nombre de métriques sur n'importe quel système.
Prometheus installation
Prometheus installation jppLe logiciel est disponible dans les paquets standards de Debian, donc l'installation se passe bien avec le téléchargement d'un certain nombre (grand nombre même) de dépendances.
Avec cette installation "brute" aucune mesure d'une autre machine n'est visible , ici la machine "personnelle" en ajoutant quelques lignes dans le fichier "/etc/prometheus/prometheus.yml" :
- job_name: k2000
# If prometheus-node-exporter is installed, grab stats about the local
# machine by default.
static_configs:
- targets: ['192.168.2.8:9100']Pour que cela fonctionne il faut installer un "prometheus-exporter" sur cette machine ce qui ne pose aucun problème sur cette machine Debian. Quelques minutes plus tard des mesures commencent à être visibles.
Ce qui est très ennuyeux avec Prometheus c'est l'utilisation de ce fichier de paramétrage relativement "monolithique" qui peut (doit) devenir difficile à gérer !
On peut tester rapidement le fonctionnement sur le port 9090, il faudra bien sûr attendre un certain temps que des mesures soient disponibles.
L'interface "standard" n'est pas très "sexy" mais elle permet de voir le grand nombre de données différentes disponibles. Il est possible d'afficher des graphes simplifiés d'une mesure, mais ce n'est pas l'interface à utiliser couramment, par contre c'est un bon moyen de voir l'ensemble des mesures disponibles en standard, il y en a énormément dont un certain nombre qui restent incompréhensibles pour moi ...
La plupart des mesures présentées dans la liste sont en fait "multiples", par exemple la mesure "node_disk_io_now" présente par défaut l'ensemble des disques physiques et des partitions LVM présentes dans la machine.
Cet interface permet aussi de consulter différents aspects :
- Les alertes (je n'en ai pas encore installé une)
- Visualiser quelques mesures (une à la fois)
- Afficher le paramétrage "basique" de Prometheus.
Pour afficher des graphiques plus "jolis", et surtout des "dashboard" synthétiques plus représentatifs de l'activité d'un service, l'installation de Grafana s'impose.
Pour installer Grafana il est suffisant (Debian) d'ajouter un fichier "grafana.list" dans "/etc/apt/sources.list.d" contenant :
deb https://apt.grafana.com stable mainPuis récupérer et installer la clef GPG :
wget -q -O /usr/share/keyrings/grafana.key https://apt.grafana.com/gpg.key
cd /etc/apt/trusted.gpg.d
ln -s /usr/share/keyrings/grafana.key ./grafana.ascOn peut alors lancer l'installation, ensuite Grafana-server démarre sans problème et la "data source" Prometheus est comprise d'office. On peut donc tout de suite passer aux choses sérieuses.
Attention toutefois à bien paramétrer la datasource sur la machine "Prometheus".
Ici j'ai créé une datasource "Prometheus-1" qui pointe vers la machine locale, comme d'habitude avec Grafana cela n'a rien de complexe. Pour Grafana, je ne connaissais pas la dernière version (9.4) mais l'interface a beaucoup changé et, s'il offre plus de possibilités, il est nettement plus complexe.
La configuration de Prometheus est contenue dans un fichier "YAML" unique qui risque de devenir très vite complètement indigeste et donc une source d'erreur.
A éviter donc ... Et en cherchant un peu on peut trouver sur Github une application dédiée à cette activité : Promgen (peut-être complexe) ou une autre solution à trouver que je vais essayer de mettre en action dans un prochain chapitre.
Prometheus/grafana premiers pas
Prometheus/grafana premiers pas jppDans un premier temps on est un peu effrayé par la complexité et le nombre des métriques disponibles, et, en plus une métrique en cache plusieurs ... par exemple la métrique "node_disk_io_now" "cache" des valeurs pour chaque disque, ci dessous la liste obtenue pour une machine de mon réseau/
node_disk_io_now{device="sda",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="sdb",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="sdc",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="sdd",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="sde",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="sr0",instance="192.168.2.8:9100",job="k2000"}
.......La machine ayant plusieurs grappes "Raid" elles apparaissent aussi dans la liste :
node_disk_io_now{device="md0",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="md1",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="md2",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="md4",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="md5",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="md6",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="md6p1",instance="192.168.2.8:9100",job="k2000"}
node_disk_io_now{device="md7",instance="192.168.2.8:9100",job="k2000"}
......Une demande simple dans Grafana de "node_disk_io_now" ramènera un grand nombre de valeurs, et donc de courbes sur le graphe, heureusement "now" renvoie une valeur instantanée, donc pas besoin de fonction pour obtenir une bonne vision de l'activité au cours du temps.
Les données présentées ci-dessus sont limitées à une instance particulière, ici "k2000". Il est bien sûr possible de "filtrer" les données sur une "instance", un "job" et ici un "device". Il est aussi possible d'utiliser la fonction "sum" pour n'obtenir qu'une seule courbe, intéressant par exemple pour le consommation CPU d'une machine multiprocesseurs.
Par ailleurs beaucoup de séries sont en fait des compteurs qui s'incrémentent au fil du temps, la représentation graphique est donc moins "parlante" et se manifeste par une courbe qui "monte" indéfiniment, heureusement les fonctions "rate" (ou "irate") et "delta" (ou "idelta") permettent de mieux représenter la variation des valeurs dans le temps . Les deux fonctions commençant par "i" ne traitent que les deux dernières valeurs de l'intervalle de temps spécifié, les deux autres donnent la différence entre la première et la dernière valeur de l'intervalle de temps spécifié.. Leur forme générique est :
fonction(valeur[intervalle de temps])Il est possible d'imbriquer les fonctions et d'utiliser une fonction "sum(delta(....))".
Une documentation générale sur les fonctions est accessible ICI.
Avant de pouvoir présenter un graphe sur Grafana il faut donc bien réfléchir pour trouver :
- La mesure à utiliser
- Les filtres à appliquer
- La/les fonctions à appliquer aux données pour obtenir un affichage "utile"
L'interface de Grafana (9.5.2 maintenant) est devenu nettement plus complexe que les versions 7 que j'utilisais auparavant pour permettre d'utiliser au mieux les données de Prometheus.
La création d'un dashboard utile est une oeuvre de longue haleine qui nécessite un temps d'apprentissage assez important ne serait-ce que pour trouver la bonne formulation pour obtenir l'information souhaitée ... Nous verrons dans un autre article quelques exemples.
Prometheus après quelques semaines
Prometheus après quelques semaines jppNotions générales.
Les données recueillies par les différents "exporters" sont des données brutes et très basiques, mais très nombreuses et détaillées. Il n'est, en général, pas évident de relier cette information à des notions "connues" telles que le pourcentage de CPU utilisé ou le nombre d'IO par seconde.
De même pour suivre l'activité d'une base de données la recherche des "bons" indicateurs est assez complexe.
Il est intéressant de rechercher des "dashboards" existants pour s'inspirer de leur contenu ou, au moins, mieux comprendre les données disponibles.
Exemple 1.
Par exemple pour le CPU on dispose d'un très grand nombre de données, par ailleurs détaillées par CPU. Pour mesurer l'activité CPU on dispose de deux groupes de valeurs "user" et "nice" détaillées par CPU. Ces valeurs, ici "node_cpu_seconds_total", sont en fait des compteurs qui mesurent un temps total d'usage.
Par exemple pour calculer le % CPU utilisé sur les dernières 120 secondes j'ai utilisé la formule :
sum(rate(node_cpu_seconds_total{job="nom_du_job",mode!="idle"}[120s])) * 100
Cette machine exécutant plusieurs Machines Virtuelles on peut utiliser une formule analogue :
sum(irate(node_cpu_guest_seconds_total{job="nom_du_job", mode!="idle"}[120s])) * 100
qui permet de visualiser le CPU consommé par l'ensemble des MV.
Attention on peut dépasser 100% sur une machine multiprocesseurs à moins de ne multiplier le résultat que par (100 / Nombre_de_threads).
En bref tout ceci est assez complexe il est difficile (et long) de trouver les "bonnes" métriques et de les présenter sous une forme digeste ...
Par contre un peu de recherche permet de trouver la métrique qui vous intéresse particulièrement ...
Il est donc intéressant de rechercher des panneaux "tous faits", il en existe énormément, et éventuellement de les modifier (simplifier ou ajouter) pour ne pas passer un temps très important à la gestion de ces tableaux de suivi de performance.
Grafana permet ici d'obtenir tous les "dashboards" voulus éventuellement personnalisés à souhait.
Il existe de nombreux panneaux "en kit" permettant de bien débuter sans être obligé de se coltiner des tâches relativement complexes de recherche et surtout de "bricolage de formules" pour arriver à ce que l'on veut.
J'aurais bien présenté quelques "dashboards" mais hélas la plupart sont très "volumineux" et nécessitent de "défiler" plusieurs écrans, mais j'en ai trouvé un "petit" très synthétique qui présente quelques données sur une base MarioaDB :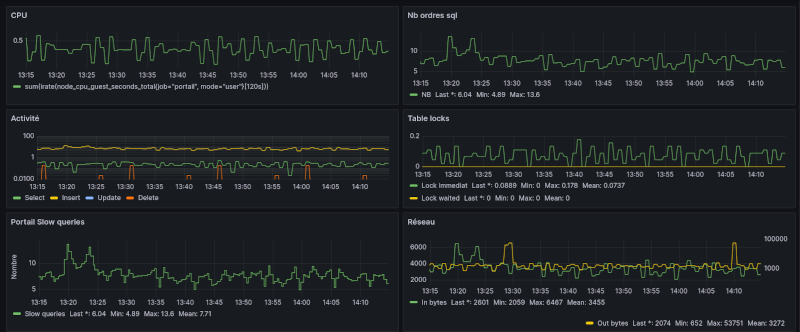
Apache exporter : incident
Apache exporter : incident jppUn petit incident avec prometheus-apache-exporter.
Lors de la migration de la machine supportant ce serveur Web de bullseye à bookworm je n'ai pas vérifié le fonctionnement des modules de prometheus le "node-exporter" et le "mysqld-exporter" se sont lancés normalement et "tournent" correctement, il n'en est pas de même pour "apache-exporter" qui ne se lance plus et on trouve dans les logs un message sibyllin au sujet d'un "flag -t incorrect".
Or la seule ligne de paramètres dans /etc/default/prometheus-apache-exporter est :
ARGS=' -telemetry.address 192.168.2.80:9102 -scrape_uri http://kvm-web.jpp.fr:89/server-status/?auto'
Qui ne montre aucun flag "-t" et qui fonctionnait parfaitement avec la version de l'exporter de bullseye.
Après un peu de réflexion j'ai essayé de doubler les tirets dans le paramétrage :
ARGS=' --telemetry.address 192.168.2.80:9102 --scrape_uri http://kvm-web.jpp.fr:89/server-status/?auto'
et le programme se lance sans erreur.
Effectivement les paramètres "longs" demandent en général un double tiret, mais cela fonctionnait parfaitement avec les versions antérieures ....