Omeganoc : visualiser de l'état de vos systèmes
Omeganoc : visualiser de l'état de vos systèmes jppOmeganoc est un logiciel français, cocorico, qui associé à Shinken et à ses sondes permet :
- de conserver l'historique des données de mesure
- d'afficher des tableaux de bord graphiques du plus bel effet.
Note 2017 : Malheureusement ce logiciel ne semble plus maintenu et la dernière version connue est la 0.93. Il vaut mieux aujourd'hui utiliser Grafana/InfluxDB, à voir ici.
La partie stockage utilise la base de données "whisper", analogue dans son principe au très connu RRD, qui utilise un démon spécifique nommé carbon-cache. Cette base est alimentée directement par l'intermédiaire du module "Livestatus" de Shinken et exploitée par deux outils spécifiques à Omeganoc :
- Hokuto qui gère l'interface graphique :
- Nanto qui gère une partie "prévisions" à partir des données stockées.
L'installation est assez complexe, surtout par le nombre de dépendances "inconnues". Nanto utilise "R" pour établir ses prévisions ... et nécessite, lui aussi, un certain nombre de dépendances, pas toujours évidentes.
Omeganoc : installation
Omeganoc : installation jppLe produit peut s'installer avec un classique "tar.gz" ou bien directement par "Git". Il comporte une partie "Shinken" dont je ne me suis pas servi car Shinken était déjà installé sur la machine virtuelle.
Par précaution j'ai effectué un snapshot du disque de cette MV afin de pouvoir recommencer l'installation proprement sur incident. J'ai bien fait car la liste des pré-requis est très largement insuffisante.
J'ai donc téléchargé l'archive :
http://www.omegacube.fr/downloads/omeganoc.v0.93.tar.gz (# 11Mo).
Je l'ai ensuite décompressée dans un petit répertoire bien tranquille avant d'y lancer la commande fatidique ...
Non,non, j'ai dit qu'il manquait des pré-requis, je vous ferais grâce des plantages que leur absence provoque. Il faut donc installer les paquets suivants (les autres ont déjà été chargés lors de l'installation de Shinken) :
| graphviz graphviz-dev libgraphviz-dev pkg-config python-dev libigraph0 libigraph0-dev |
C'est bon, cette fois on peut lancer le "make install" :
| # Checks that Shinken is installed /usr/bin/python /usr/bin/shinken /usr/bin/pip pip install 'graphite-query==0.11.3' Downloading/unpacking graphite-query==0.11.3 ....... |
Ca télécharge et ça compile sec pendant plusieurs minutes dans ma pauvre VM monoprocesseur, le nombre de dépendances est très important ... et cete fois il manque le paquet "igraph" avec le paquet de développement associé "apt-get install libigraph0 libigraph0-dev" et c'est reparti ... à charger et compiler plein de trucs.
Cette fois-ci cela se termine par :
| Cleaning up... useradd --user-group graphite shinken install --local vendor/livestatus OK livestatus shinken install graphite Grabbing : graphite OK graphite shinken install --local vendor/logstore-sqlite OK logstore-sqlite shinken install --local hokuto OK hokuto shinken install named-pipe Grabbing : named-pipe OK named-pipe shinken install pickle-retention-file-generic Grabbing : pickle-retention-file-generic OK pickle-retention-file-generic Installing cron routine and restarting cron service... Omeganoc have been succefully installed Add 'modules graphite, livestatus, hokuto' to your broker-master.cfg file Add modules named-pipe, PickleRetentionArbiter to your arbiter-master.cfg file Add modules logstore-sqlite to livestatus.cfg. running install running build running build_py creating build creating build/lib.linux-x86_64-2.7 creating build/lib.linux-x86_64-2.7/on_reader copying on_reader/predict.py -> build/lib.linux-x86_64-2.7/on_reader copying on_reader/livestatus.py -> build/lib.linux-x86_64-2.7/on_reader copying on_reader/mk_livestatus.py -> build/lib.linux-x86_64-2.7/on_reader copying on_reader/__init__.py -> build/lib.linux-x86_64-2.7/on_reader running install_lib creating /usr/local/lib/python2.7/dist-packages/on_reader copying build/lib.linux-x86_64-2.7/on_reader/predict.py -> /usr/local/lib/python2.7/dist-packages/on_reader copying build/lib.linux-x86_64-2.7/on_reader/livestatus.py -> /usr/local/lib/python2.7/dist-packages/on_reader copying build/lib.linux-x86_64-2.7/on_reader/mk_livestatus.py -> /usr/local/lib/python2.7/dist-packages/on_reader copying build/lib.linux-x86_64-2.7/on_reader/__init__.py -> /usr/local/lib/python2.7/dist-packages/on_reader byte-compiling /usr/local/lib/python2.7/dist-packages/on_reader/predict.py to predict.pyc byte-compiling /usr/local/lib/python2.7/dist-packages/on_reader/livestatus.py to livestatus.pyc byte-compiling /usr/local/lib/python2.7/dist-packages/on_reader/mk_livestatus.py to mk_livestatus.pyc byte-compiling /usr/local/lib/python2.7/dist-packages/on_reader/__init__.py to __init__.pyc running install_egg_info Writing /usr/local/lib/python2.7/dist-packages/datareader-0.5.egg-info Installing Hokuto cp -r hokuto/standalone/* /usr/local/hokuto cp hokuto/etc/hokuto.cfg /etc/hokuto.cfg running clean |
Cela à un petit air de fin normale, on va pouvoir essayer de lancer le logiciel ... après avoir inspecté les paramètres de "hokuto" (/etc/hokuto.cfg) et modifié la clef "secrète".
Le "Live-status" de Shinken est bien en écoute sur le port TCP 50000, cela devrait fonctionner avec les paramètres standard de "hokuto".
Le script de lancement de "hokuto" a été installé dans /etc/shinken/init.d ? Il faudra le mettre à sa place (ou mettre un lien) suivi d'un "update-rc.d .... enable".
Ma petite VM se met à swapper, je la stoppe et la redémarre avec carrément 1536Mo de mémoire et deux processeurs pour évaluer la taille optimale nécessaire.
Omeganoc : ajustements
Omeganoc : ajustements jppLa documentation est assez spartiate et comme le stockage des données est réalisé par "Graphite" et la base de données "Whisper" (semblable dans son principe à RRD), il faut configurer convenablement la rétention par défaut.
Le fichier /opt/graphite/conf/storage-schémas.conf doit impérativement être modifié car avec ces paramètres les données ne sont conservées qu'un jour. Comme je m'intéresse aux pointes de consommation j'ai forcé la méthode d'aggrégation à "max", et mis une conservation par défaut à 60 secondes pendant 30 jours, puis 180s pendant 90j et 540s pendant 365j. Cela donne :
| [default_1min_for_1day] pattern = .* retentions = 60s:30d,180s:90d,540s:365d aggregationMethod = max |
Cela donne une bonne base et il est toujours possible par la suite de modifier ces paramètres fichiers par fichiers. Il est en effet inutile de conserver minute par minute le volume disque utilisé, l'utilitaire "whisper-resize.py" permet de modifier les paramètres fichier par fichier :
FILE=mon_fichier.wsp
whisper-resize.py --aggregationMethod=max $FILE 60s:15d 180s:90d 540s:365d
Les fichiers de données sont placés dans des répertoires par "machine" dans l'arborescence "/opt/graphite/storage/whisper". Chaque plugin donne lieu à un répertoire contenant les fichiers de données, par exemple :
drwxr-xr-x 2 root root 4096 janv. 29 20:29 Cpu
drwxr-xr-x 2 root root 4096 févr. 23 23:03 D_
drwxr-xr-x 2 root root 4096 févr. 23 23:04 D_boot
drwxr-xr-x 2 root root 4096 janv. 29 20:29 __HOST__
drwxr-xr-x 2 root root 4096 janv. 29 20:29 Load
drwxr-xr-x 2 root root 4096 févr. 20 11:49 Memory
drwxr-xr-x 2 root root 4096 janv. 29 20:29 Niceth0
drwxr-xr-x 2 root root 4096 janv. 29 20:29 Smtp
drwxr-xr-x 2 root root 4096 janv. 29 20:29 TimeSync
Le répertoire "D_" (partition "/") contient ici deux fichiers :
_Pctused.wsp
Sizeused.wsp
qui contiennent le % utilisé de la partition et la taille utilisée.
Autre sujet "qui fâche", mais on s'y fait, il faut éviter comme la peste les séparateurs style "-" (tiret) dans les noms de machines ou de services ... car l'interface graphique ne les montre pas (absence de ces machines/services dans les boites de choix) ... cela devrait être corrigé dans une prochaine version.
Omeganoc : ajustements (2)
Omeganoc : ajustements (2) jppL'affichage réalisé "en direct" par Hokuto ne montre pas une chose très intéressante/amusante : il est possible de faire calculer des prévisions par le module "Nanto" qui s'affichent comme les données de mesure, presque, elles sont grisées et font de petits panaches du plus bel effet.
Nanto est réalisé en "R", ce qui m'a donné l'occasion de rentrer un peu dans ce système de calcul pour réussir à la faire tourner. Cette fonctionnalité est plus ou moins expérimentale, mais un peu "coton" à installer.
Au premier essai "Nanto" refuse de se lancer :
| File "/usr/local/nanto/service.py", line 34, in <module> from lockfile.pidlockfile import PIDLockFile ImportError: No module named pidlockfile |
Simple probleme de version entre les modules "lockfile" et "python-daemon"
Je désinstalle et réinstalle les deux dans les versions suivantes :
python-daemon 2.1.0
lockfile-0.12.2
Ensuite copier ...../omeganoc/nanto/etc/nanto.cfg dans /etc/nanto.cfg
Après cette petite cure le process "nanto" démarre, mais il lui manque des tas de choses :
ImportError: No module named rpy2.rinterface
Pas de "R" non plus !
Cela se résout par "apt-get install python-rpy2" qui charge tout ce qui semble nécessaire (entre autres les packages "R") :
| bzip2-doc cdbs gfortran gfortran-4.9 libblas-dev libbz2-dev libgfortran-4.9-dev libjpeg-dev libjpeg62-turbo-dev liblapack-dev liblzma-dev libncurses5-dev libpcre3-dev libpng12-dev libreadline-dev libreadline6-dev libtcl8.5 libtinfo-dev libtk8.5 r-base-core r-base-dev r-cran-boot r-cran-class r-cran-cluster r-cran-codetools r-cran-foreign r-cran-kernsmooth r-cran-lattice r-cran-mass r-cran-matrix r-cran-mgcv r-cran-nlme |
soit 47Mo d'archives.
Auxquels il faut ajouter "r-cran-segmented" ? et "r-cran-fimport" ? ainsi que r-cran-nnet r-cran-rpart r-cran-spatial r-cran-survival r-doc-html r-recommended ...
En modifiant le fichier de config "/etc/nanto/cfg" et en décommentant le "debug_worker" on peut déclencher un calcul immédiat et non en attendant l'horaire planifié.
J'obtient une nouvelle erreur :
| ERROR - An error occured while executing the R script "/usr/local/nanto/timewindow.r": Error in library("forecast") : there is no package called ‘forecast’ Malgré cette erreur le programme continue et calcule plein de trucs (selon le log) avec toutefois de nouveaux messages d'erreur : An exception occured while computing the timewindow predictions for component gwadsl.__HOST__.pl: global name 'save_error' is not defined |
Dans quel paquet Debian se trouve cette librairie ?
"apt-get install r-cran-fimport"
qui installe en outre :
lynx lynx-cur r-cran-fimport r-cran-timedate r-cran-timeseries
Cette installation ne fournit pas la librairie "forecast" car les messages d'erreur sont toujours présents !
Une recherche donne la possibilité que ces paquets soient disponibles grâce à l'archive : "http://cran.univ-paris1.fr/" (ou lyon1.fr), ajouter dans votre "sources.list" :
deb http://cran.univ-paris1.fr/bin/linux/debian jessie-cran3/
Le message sur la librairie "forecast" est toujours présent, il faut installer le paquet ? On lance "R" :
| R R version 3.1.1 (2014-07-10) -- "Sock it to Me" Copyright (C) 2014 The R Foundation for Statistical Computing Platform: x86_64-pc-linux-gnu (64-bit) .... Type 'demo()' for some demos, 'help()' for on-line help, or 'help.start()' for an HTML browser interface to help. Type 'q()' to quit R. install.packages("forecasting") Installing package into ‘/usr/local/lib/R/site-library’ (as ‘lib’ is unspecified) --- Please select a CRAN mirror for use in this session --- |
------ cela ouvre une fenêtre pour choisir le serveur CRAN, ici on choisit "France (Lyon 1)"
|
package ‘forecasting’ is not available (for R version 3.1.1) The downloaded source packages are in |
On ne sauvegarde pas le "workspace", On reteste le lancement de "nanto" et cette fois cela a l'air de mieux fonctionner, le service se lance et lance immédiatement le calcul. Le log ne présente plus de message d'erreur et on peut penser que le calcul est réussi !
Toutefois quelques messages d'erreur sont présents sur quelques catégories :
| 016-01-13 17:38:49,496 - root - DEBUG - [nanto:timewindow] Found 0 data points for node filtre.NetworkUsage.br0_in_octet.1452616033 2016-01-13 17:38:49,496 - root - INFO - [nanto:timewindow] Skipped time series on filtre.NetworkUsage.br0_in_octet.1452616033: not enough data (0 points) 2016-01-13 17:38:49,496 - root - WARNING - [nanto:timewindow] An exception occured while computing the timewindow predictions for component filtre.NetworkUsage.br0_in_octet.1452616033: global name 'save_error' is not defined 2016-01-13 17:38:49,496 - root - DEBUG - [nanto:timewindow] Exception details: Traceback (most recent call last): File "/usr/local/nanto/timewindow_worker.py", line 61, in internal_run success = self.__go(c, checkinterval) File "/usr/local/nanto/timewindow_worker.py", line 94, in __go save_error(target, "There is not enough data to have make accurate predictions") NameError: global name 'save_error' is not defined |
Remarque :
Cela consomme pas mal de CPU : 50 à 98% de ma VM (en monoprocesseur).
Le volume de la base de données sqlite "/var/lib/shinken/nanto.db" augmente sérieusement et dépasse 1,5 mégaoctet sur mon petit test ne comportant que 8 machines et environ 30 services.
Dans mon cas le calcul a duré de : 17:37:47 à 17:54:34 soit environ 17 minutes.
La consommation mémoire reste très raisonnable : moins de 450M hors buffers et cache, environ 896M de mémoire devraient suffire largement dans mon cas.
Test avec 1024Mo de mémoire et 2 CPU.
Remarques :
1) Nanto n'utilise qu'un seul processeur !
2) Consommation mémoire < 1024Mo y compris buffers et cache.
3) Durée du traitement :
19:21:07 à 19:37:35, 1050 secondes soit un peu plus de 17 minutes
21:37:41 à 21:53:11, 930 secondes soit un peu plus de 15 minutes.
Charger aussi "apt-get install libopenblas-base " pour augmenter les performances en multithread; cela n'est pas évident, même avec deux processeurs attribués à la MV. En fait avec 1 processeur et 1024Mo de mémoire tout se passe bien et le fichier "nanto.db" s'est stabilisé à moins de 300Ko.
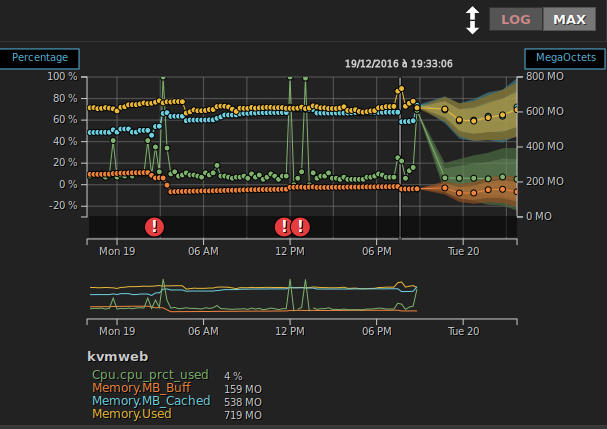
Omeganoc : graphiques
Omeganoc : graphiques jppNote 2022 : ces graphiques sont presque aussi beaux que ceux de Grafana, mais Omeganoc n'est plus, paix à son âme, c'est dommage c'était un produit intéressant et agréable à utiliser.
Pour égayer un peu mes propos quelques graphiques présentés par Omeganoc, la partie "calculée" est sur la droite.
Un graphe simple de l'usage CPU sur 24 heures :
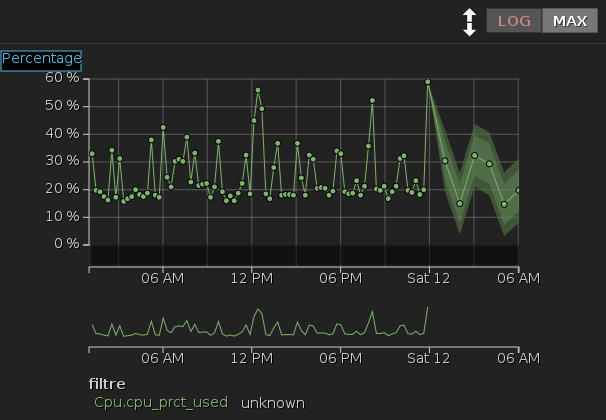 |
A noter les possibilités :
- Modifier les limites de dates affichées, dernières 24 heures, mois en cours, derniers 30 jours ... ou des zones de dates précises avec calendrier cliquable
- Afficher en linéaire ou logarithmique
- Afficher MAX/MIN/AVG
- Zoom sur une zone avec le roulette de souris
La zone hachurée à droite correspond aux prévisions calculées par Nanto.
Un graphe logarithmique d'utilisation réseau :
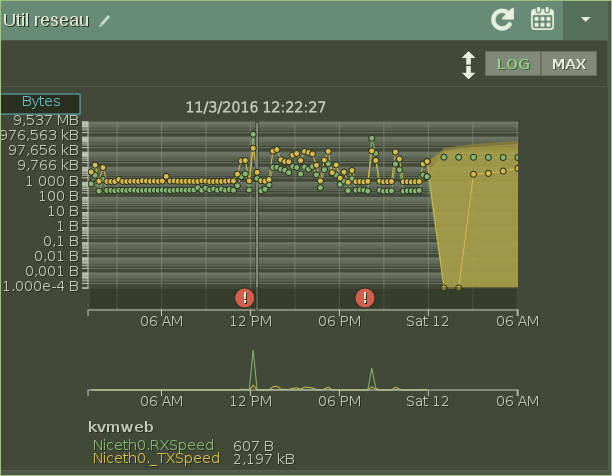 |
Zoom sur l'utilisation CPU/mémoire vers 12h51 :
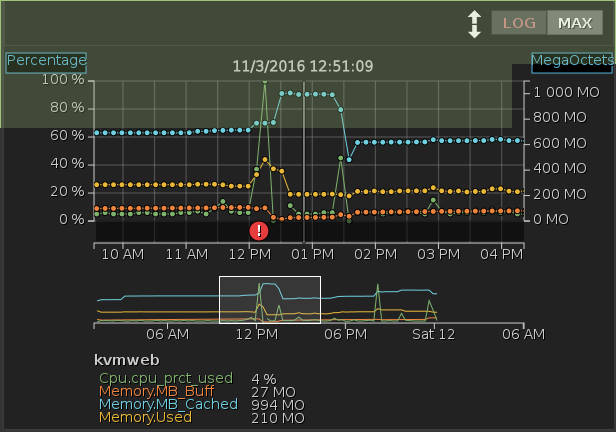 |
On peut remarques l'alerte (rond rouge) pour utilisation du CPU qu'il suffit de cliquer pour avoir plus d'informations : heure, message ...