Disques : performance
Disques : performance jppLa performance des disques.
Le premier article présente un moyen d'atteindre des débits disques plus importants : le "stripping".
Ces articles étalés sur une période supérieure à 10 ans montrent bien l'augmentation des performances de ces belles petites mécaniques (HDD) ou électroniques pour les SSD.
SSD, avec Linux c'est super
SSD, avec Linux c'est super jppSSD : depuis que l'on en parle j'avais envie de tester ce genre de bête.
J'ai craqué et cassé ma tire-lire pour pouvoir disposer d'un de ces trucs : "OCZ Vertex Turbo series" de 30Go avec un cache de 64Mo.
Par ailleurs mon système XEN étant le résultat de nombreuses migrations :
- Suse SLES 10
- Suse SLES 10 SP1
- Suse SLES 10 SP2
- Suse SLES 11
- OpenSuse 11.1
Son disque système devait commencer à être assez bizarre, j'ai décidé de "repartir à zéro" et d'utiliser mon nouveau disque comme disque système.
Tout ça c'était avant mon retour à Debian, pensez ma première machine Linux était une Debian avec un kernel 1.0.1 sur un Amiga 2000 dopé au 68060.
J'ai sauvegardé sur un disque externe tout ce qui avait de la valeur (par exemple le répertoire "/etc" et d'autres bricoles).
Je démonte les disques de stockage de données par sécurité (2 x 1To en miroir car toutes mes Machines virtuelles sont dessus), je les remettrai en service plus tard, on n'est jamais trop prudent ! Ne doutant de rien j'ai tenté d'installer une OpenSuse 11.2 en rc1 voir site http://www.opensuse.org . Après quelques ennuis de gravure (ISO mal récupérée ?), c'est bizarre comme cela énerve, j'ai enfin réussi à créer le CD miracle. Malheur, lors de l'installation de cette 11.2 il y a un problème de génération du fichier "initrd" et des erreurs diverses qui rendaient le système inutilisable. Je suis repassé sur une OpenSuse 11.1 (stable) dont j'avais le DVD et ... l'installation a foiré sur mon beau SSD tout neuf ...
Après quelque réflexion, j'ai lu des bricoles sur les problèmes d'installation de systèmes sur des SSD, j'ai décidé de frapper un grand coup : j'ai réduit (sniff) fortement la vitesse du CPU (multiplicateur passé de 11x à 7x), en bref j'ai transformé ma belle machine en brouette ... et celà a fonctionné ! L'installation de la 11.1 s'est fort bien passée. J'ai admiré au passage la beauté de l'installeur OpenSuse dont les graphismes sont parfaits, toutes les options de formatage des partitions sont assez bien foutues (si l'on met l'écran à 1024x768 au moins ...) et tout se passe bien. J'ai abandonné la partition spécifique "BOOT" et tout mis dans une seule partition du SSD. Après le paramétrage de l'installation tout est automatique et s'est déroulé en à peu près 30 minutes (malgré le 7x). Note : il vaut mieux "nommer" les partitions pour être dans la course, ma partition root se voit donc nommée "ROOT" (très original). Une seule partition sur l'ensemble du SSD (29,8 GO) nommée "ROOT" et montée par label. Après un arrêt pour remettre le multiplicateur à 11x le boot est super rapide, le chargement des logiciels presque instantané, OpenOffice apparaît très rapidement sur l'écran, en bref c'est super agréable. Vive le SSD ! Comme je disposais toujours de mon DVD 11.2 et que j'avais un peu de temps j'ai décidé de refaire une installation de 11.2 avec le multiplicateur réduit à 7x, on efface tout et on recommence.
C'est parti :
- on redéfinit les partitions (idem à celle définies précedemment),
- on choisit les logiciels à installer (on utilise le bureau KDE car "gdm" ne fonctionne pas/mal avec le kernel XEN.
- on crée les utilisateurs "de base" en faisant attention à ne pas leur configurer un login automatique, c'est ennuyeux par la suite
"Suivant" l'installation démarre ... après environ 15 minutes la machine reboote pour la phase de configuraton. Aucune erreur ... bizarre le système gère mal l'installation sur SSD lorsque l'on est à pleine vitesse ???? La phase de configuration automatique se lance et ne signale aucun problème. 5 minutes après je dispose d'un beau bureau Gnome avec couleurs personnalisées par Suse, avec un logo Suse stylisé en fond, très smart en vert olive et noir. Je vais voir un peu ce que cela donne après un reboot er remise en place du multiplicateur à 11X. Beagle est en train d'indexer je le laisse finir avant de rebooter. Une petite image de l'écran Gnome : 
C'est beau !
On configure le réseau, tiens la configuration est construite directement avec des ponts, il n'y aura peut-être pas d'ennuis avec les machines virtuelles.
Enfin on va rebooter et passer en vitesse normale, fini le ralenti.
Après reboot le système répond très bien, c'est super...
Essayons Xen maintenant, on reboote sur le noyau XEN et horreur l'écran graphique est tout bizarre, ce doit être une oeuvre abstraite. Mais, sans rigoler, l'accès est impossible en mode graphique et bloque le clavier si l'on a le malheur de cliquer.
La machine reste toutefois accessible par ssh ... essayons de lancer une MV par ssh, "xm new MV" puis "xm start MV", tiens cela a l'air de marcher ... la machine virtuelle est accessible de l'extérieur, une petite connexion en X permet un accès graphique normal à la MV, tout est donc normal à part cet écran graphique bloqué !
Je tente alors de passer par kdm au lieu de gdm, plus de GNOME mais du KDE.
En mode non-XEN tout est OK, le fonctionnement est parfait l'écran KDE est lui aussi très esthétique.
En mode XEN ... ce n'est pas mieux qu'avec GNOME l'écran graphique reste dans un état "bizarre" et tant que l'on a pas cliqué sur cet écran de malheur on peut commuter sur les terminaux caractère par Ctrl+Alt+Fn.
Vite un petit rapport de bug pour tenter d'aider à résoudre ce problème :
- Bug non encore répertorié (Release Candidate), tout est normal en 11.1, je l'ouvre
- Rapidement un début de solution : dire à XEN de n'utiliser que 4Go, ... et ça marche, la session X s'ouvre et on peut lancer une machine virtuelle en interactif.
- Une piste pour la solution de ce bug existe, une limite mémoire à 4Go cela me rappelle un système 32bits ! 'ai proposé de tester le patch dès qu'il sera disponible.
- 7 Novembre : le patch est disponible ... il concerne "vmalloc.c" qui semblait ne pas bien s'entendre avec Xen. Le patch passé on recompile le noyau sous un autre nom. Après ajout des lignes "qui vont bien" dans le fichier de configuration de grub (menu.lst) on teste et c'est OK !
Toute la mémoire est reconnue sous Xen, le serveur X se lance correctement, tout est pour le mieux dans le (presque) meilleur des mondes. J'espère que ce patch va être intégré dans la version définitive.
Evidemment ce n'est pas terrible de limiter à 4Go, je le vois mal sur un serveur de production (j'en connais à 64 Go) avec 2 douzaines de MV). Enfin je peux tester cette version 11.2 avec un XEN 3.4.1 dernier cri. Et cela marche assez bien.
Pour montrer que cela marche je ne résiste pas à montrer l'écran avec la MV sur laquelle je suis en train de travailler (KDE + Windows) : 
Cela prouve que tout marche !
En bref SSD c'est OK, à part lors de l'initialisation du système où quelque chose ne "suit" pas.
Tests de vitesse :
- Sur un RAID (miroir) SATA :
hdparm -t /dev/md1
/dev/md1:
Timing buffered disk reads: 232 MB in 3.00 seconds = 77.25 MB/sec - Sur le SSD :
hdparm -t /dev/sdc1
/dev/sdc1:
Timing buffered disk reads: 508 MB in 3.00 seconds = 169.26 MB/sec
Ces différences expliquent la réduction du temps de boot, le confort ressenti au chargement d'applications.
Temps de boot du système depuis le choix du noyau (GRUB) < 16 secondes pour l'invite de X, le système contient 4 disques de données (miroir et LVM) en plus du SSD et deux interfaces réseau ce qui rallonge le temps de boot.
En bref : SSD c'est presque OK ! Pour terminer, économisez votre SSD en lui évitant des ordres d'écriture dont il peut se passer, utiliser les options "nodiratime" et "relatime / noatime" dans le fichier /etc/fstab, voici la ligne correspondante dans mon propre fichier fstab :
UUID=e5a02c97-cba2-4198-9b7a-1b1d354143ba / ext3 relatime,nodiratime,errors=remount-ro 0 1
cela pourrait être aussi :
/dev/sda1 / ext3 relatime,nodiratime,errors=remount-ro 0 1
SSD : mesures
SSD : mesures jppLes disques SSD sont très performants, c'est communément admis, mais qu'en est-il en réalité. Les systèmes Linux présentent plusieurs schedulers d'entrées/sorties, lequel est le plus adapté aux disques SSD ?
Pour le savoir j'ai fait un certain nombre de mesures sur deux machines et avec plusieurs noyaux différents qui ont tous été compilés "à la maison".
Le scheduler IO peut facilement être modifié dynamiquement disque par disque en intervenant dans le répertoire "/sys/block", dans ce répertoire on trouve un répertoire par disque physique contenant tout ce qu'il faut, entre autres un répertoire "queue" :
ls -al /sys/block/sda/queue
total 0
drwxr-xr-x 3 root root 0 2010-01-27 15:00 .
drwxr-xr-x 8 root root 0 2010-01-27 14:59 ..
-r--r--r-- 1 root root 4096 2010-01-27 15:00 hw_sector_size
drwxr-xr-x 2 root root 0 2010-01-27 15:10 iosched
-rw-r--r-- 1 root root 4096 2010-01-27 15:10 iostats
-r--r--r-- 1 root root 4096 2010-01-27 15:10 logical_block_size
-r--r--r-- 1 root root 4096 2010-01-27 15:10 max_hw_sectors_kb
-rw-r--r-- 1 root root 4096 2010-01-27 15:10 max_sectors_kb
-r--r--r-- 1 root root 4096 2010-01-27 15:10 minimum_io_size
-rw-r--r-- 1 root root 4096 2010-01-27 15:10 nomerges
-rw-r--r-- 1 root root 4096 2010-01-27 15:10 nr_requests
-r--r--r-- 1 root root 4096 2010-01-27 15:10 optimal_io_size
-r--r--r-- 1 root root 4096 2010-01-27 15:10 physical_block_size
-rw-r--r-- 1 root root 4096 2010-01-27 15:10 read_ahead_kb
-rw-r--r-- 1 root root 4096 2010-01-27 15:00 rotational
-rw-r--r-- 1 root root 4096 2010-01-27 15:10 rq_affinity
-rw-r--r-- 1 root root 4096 2010-01-27 15:10 scheduler
Le fichier "scheduler" contient la liste des schedulers (elevator) disponibles dans votre noyau :
cat scheduler
[noop] anticipatory cfq deadline
Le scheduler actif est entouré de "[ ]" (brackets dans le texte).
Note : "anticipatory" a disparu dans le noyau 2.6.33.
Je vais tenter d'autres test plus représentatifs le la vie réelle (???) pour mieux mesurer l'influence (éventuelle ? ) du scheduler d'IO.Les tests réalisés sur plusieurs noyaux sont extrêmement longs et obligent à des "reboot" fréquents.
Commentaires sur les résultats.
- La dépendance des résultats au noyau est très forte (rappel : les noyaux sont compilés avec les mêmes options)
- Dans les tests "vraie vie" la différence SSD/SATA est soit invisible soit pas dans le sens prévu (tests GZIP)
- La dépendance par apport au scheduler d'IO est extrêmement faible et ne dépasse pas quelques pourcents.
- En lecture pure (test hdparm) les SSD sont nettement plus performants (jusqu'au noyau 2.6.32 ?)
Quelques tests réalisés sur le noyau 2.6.32 on donné des résultats catastrophiques pour le SSD, 20% moins bien que le disque classique aux tests hdparm.
J'ai récupéré et compilé un 2.6.33 (rc5) pour compléter les tableaux. Au niveau du test "hdparm" le résultat est très dégradé pour le SSD, par contre au niveau du test de compilation de 2.6.33 a fait des miracles.
Les mesures obtenues avec "hdparm" étant un peu "bizarres" avec les disques SSD à partir du noyau 2.6.32 je pense qu'une modification importante des schedulers IO est en cours, c'est confirmé par la disparition du scheduler "anticipatory" dans le 2.6.33. Ces modifications rendent les résultats de "hdparm" tellement bizarres (anormaux et irréguliers pour les SSD) que ces résultats sont à prendre avec des pincettes.
Dernières nouvelles les tests "hdparm" sont en cours de réfection avec un paramètre supplémentaire permettant un accès plus "direct" au hardware ( option --direct). Une nouvelle page est en préparation.
Tester BTFRS
Tester BTFRS jppLe nouveau/futur système de fichiers pour Linux semble être BTRFS car celui-ci est censé apporter un certain nombre de nouveautés et de facilités que d'autres systèmes (Solaris 10?) possèdent et qui simplifient la vie des administrateurs.
La possibilité d'agrandir, de réduire des FS, de jouer avec les modes RAID et d'effectuer des "snapshots" de manière simple et au sein du même outil devrait apporter beaucoup plus de souplesse au niveau de l'administration.
Mais BTRFS n'est pas encore prêt pour passer en production et les outils en version 0.19 rappellent bien que ce système est encore en période de rodage !
Note 2016 : BTRFS est maintenant "adulte" et suffisamment stable pour la production.
Je vous propose toutefois quelques tests "pour voir".
Première approche de BTRFS
Première approche de BTRFS jppLe premier test est juste destiné à apprendre le fonctionnement basique des outils liés à BTRFS. il a été exécuté sur des volumes LVM créés pour l'occasion avant de passer au travail sur des partitions physiques.
Mais, ATTENTION, la version des outils n'est (sur Debian unstable) encore que "0.19+20120328-1". Cela bouge mais la version "stable" 1.0 est peut-être encore assez loin.
Pour tester BTRFS il faut un noyau dont le support BTRFS est activé ! Si, comme c'est probable le support BTRFS est compilé en module un simple :
modprobe btrfs
devrait vous renseigner :
FATAL: Module btrfs.ko not found.
ou bien meilleur aucun message et un code retour 0.
Ce support devrait être actif pour les noyaux récents de la plupart des distributions, sinon compilez le vous même et installez le. Les tests sont réalisés avec un noyau très récent (3.4.4) afin de bénéficier des dernières corrections.
Ensuite il faut charger les outils BTRFS pour disposer, entre autres, de mkfs.btrfs. Sur Debian le paquet se nomme "btrfs-tools" sans autre complication et s'installe rapidement.
Pour ce premier test j'ai créé deux "disques" LVM de 20G nommés :
VOL_EXT4 et VOL_BTRFS. Le premier sera formaté classiquement en EXT4, le secon en BTRFS.
La commande "mkfs.btrfs" assure le formatage et la labellisation, ici :
date ; mkfs -t btrfs -L DISK_BTRFS /dev/mapper/TALE-VOL_BTRFS ; date
vendredi 4 mai 2012, 19:55:30 (UTC+0200)
WARNING! - Btrfs Btrfs v0.19 IS EXPERIMENTAL
WARNING! - see http://btrfs.wiki.kernel.org before using
fs created label DISK_BTRFS on /dev/mapper/TALE-VOL_BTRFS
nodesize 4096 leafsize 4096 sectorsize 4096 size 20.00GB
Btrfs Btrfs v0.19
vendredi 4 mai 2012, 19:55:30 (UTC+0200)
Le résultat est quasi instantané !
En EXT4 :
date; mkfs -t ext4 /dev/mapper/TALE-VOL_EXT4 ; date
vendredi 4 mai 2012, 19:56:52 (UTC+0200)
mke2fs 1.42.2 (9-Apr-2012)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
1310720 inodes, 5242880 blocks
262144 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=4294967296
160 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
vendredi 4 mai 2012, 19:56:54 (UTC+0200)
Deux secondes pour 20G, donc plus de trois minutes pour un disque de 2To. On monte ensuite les deux partitions et on vérifie :
df | grep mnt
/dev/mapper/TALE-VOL_EXT4 20907056 440692 19417788 3% /mnt/VOL_EXT4
/dev/mapper/TALE-VOL_BTRFS 20971520 120 18845632 1% /mnt/VOL_BTRFS
Tiens ETX4 consomme 3% ?
Tests "dd" en écriture, fichier de 8Go :
Pour EXT4 wait 37 .. 75% BO # 65000 .. 136000 (chiffres de "vmstat")
256000+0 records in
256000+0 records out
8388608000 bytes (8,4 GB) copied, 63,0721 s, 133 MB/s
Pour BTRFS wait 29.. 55% BO # 68000 .. 180000
256000+0 records in
256000+0 records out
8388608000 bytes (8,4 GB) copied, 60,2699 s, 139 MB/s
Tests "dd" en écriture, fichier de 16Go :
Pour EXT4 wait 37 .. 75% output # 65000 .. 136000
512000+0 records in
512000+0 records out
16777216000 bytes (17 GB) copied, 136,869 s, 123 MB/s
Pour BTRFS wait 29.. 55% output # 68000 .. 190000
512000+0 records in
512000+0 records out
16777216000 bytes (17 GB) copied, 123,338 s, 136 MB/s
La vitesse du BTRFS n'est que très peu supérieure mais les "wait_states" sont inférieurs (mesuré avec vmstat) mais reste plus constante pour les fichiers de 8G et 16G.
Tests "dd" en lecture, fichier de 16Go :
EXT4 :
512000+0 records in
512000+0 records out
16777216000 bytes (17 GB) copied, 125,661 s, 134 MB/s
BTRFS :
512000+0 records in
512000+0 records out
16777216000 bytes (17 GB) copied, 119,848 s, 140 MB/s
Léger avantage à BTRFS.
Aucune commande complexe n'a été utilisée ici, la seule différence est la pose du label de FS par "mkfs.btrf" qui simplifie un peu les commandes.
Les tests précédents ont étés réalisés avec un noyau "xenifié", ci-dessous le même test sur la même version de noyau (3.3.4) en mode "normal" :
Test "dd" en lecture fichier 16Go :
EXT4 :
512000+0 records in
512000+0 records out
16777216000 bytes (17 GB) copied, 108,485 s, 155 MB/s
BTRFS :
512000+0 records in
512000+0 records out
16777216000 bytes (17 GB) copied, 99,3723 s, 169 MB/s
Les résultats sont meilleurs laissant toujours un léger avantage à BTRFS.
J'ai prévu de présenter plus loin quelques possibilités attrayantes et les outils qui permettent d'y arriver. C'est tout pour aujourd'hui ... à la prochaine.
BTRFS : après quelques mois
BTRFS : après quelques mois jppAprès plusieurs mois d'usage BTRFS se comporte très bien.
J'ai eu un plantage (corruption) tout à fait au début mais les outils de réparation du FS ont fonctionné correctement bien que m'ayant rappelé avant lancement qu'ils n'etaient que des versions "beta" encore incomplètes.
Depuis je suis passé à des versions de noyau très récentes (3.5 et 3.6 maintenant) et je n'ai plus souffert d'un seul ennui. Je pense que le support BTRFS a été amené à maturité dans les dernières versions de noyau et qu'il est parfaitement envisageable de l'utiliser. J'ai d'ailleurs transféré tous mes répertoires personnels sur une partition RAID (/dev/mdx) formatée en BTRFS.
Au vu des sauvegardes que j'effectue régulièrement je n'ai pas vraiment testé les "snapshots" de BTRFS.
Note 2016 : pas d'ennuis avec les noyaux de la série 4.x.
Note 2024 : BTRFS est toujours là et fonctionne normalement avec un noyau 6.9.
RAID1 BTRFS et EXT4
RAID1 BTRFS et EXT4 jpp| Écriture | Lecture | |||
| P. 1 | P. 2 | P.1 | P.2 | |
| EXT4 | 53,6 | 49,1 | 120,0 | 111,0 |
| BTRFS | 67,1 | 66,1 | 103,0 | 102,0 |
| % BTRFS / EXT4 | +20,12% | +25,72% | -16,50% | -8,82% |
RAID1 BTRFS et dev/md
RAID1 BTRFS et dev/md jppCe dernier test doit permettre de mesurer toute la puissance et la souplesse de BTRFS car il va ici jouer deux rôles :
- gestion du RAID
- gestion du File system
permettant ainsi de n'utiliser qu'un outil au lieu des deux habituels (Device Mapper ou LVM pour le RAID, Gestionnaire de FS tel EXT3, EXT4 ...).
Pour améliorer la fiabilité (et la rapidité ?) les deux disques sont sur deux contrôleurs différents. On utilisera le paramètre "odirect" de "dd" pour limiter l'influence de la mémoire.
D'abord "casser" le RAID actuel, c'est super simple ...
mdadm -S /dev/md0 # stopper le device
mdadm --zero-superblock /dev/sde1 # effacer les traces
mdadm --zero-superblock /dev/sdd1 # sur les deux disques
Après cette petite opération il est de bon ton de redémarrer le système pour assurer une bonne reconnaissance des changements. effectués.
Sitôt dit, sitôt fait et on enchaîne sur la création de notre RAID1 BTRFS :
mkfs.btrfs -m raid1 -d raid1 -L BTRFS /dev/sdc1 /dev/sdd1
WARNING! - Btrfs Btrfs v0.19 IS EXPERIMENTAL
WARNING! - see http://btrfs.wiki.kernel.org before using
adding device /dev/sdd1 id 2
fs created label BTRFS on /dev/sdc1
nodesize 4096 leafsize 4096 sectorsize 4096 size 800.00GB
Btrfs Btrfs v0.19
On monte ce nouveau FS :
mount LABEL=BTRFS /mnt/DISK1omount LABEL=BTRFS /mnt/DISK1
et on vérifie :
df -k | grep mnt
/dev/sdc1 838860800 312 803151616 1% /mnt/DISK1
Seul le premier disque est visible et le FS est bien noté 800GB.
Un petit test "dd" en écriture :
dd if=/dev/zero of=/mnt/DISK1/test bs=32K count=1536000 conv=fsync oflag=direct
1536000+0 records in
1536000+0 records out
50331648000 bytes (50 GB) copied, 1001,96 s, 50,2 MB/s
Pendant ce temps les deux disques sont actifs, chacun sur leur contrôleur :
21:06:33 sdd 1577,00 0,00 100928,00 64,00 0,44 0,28 0,28 43,60
21:06:33 sde 1578,00 0,00 100992,00 64,00 0,75 0,48 0,47 74,80
Average: sdd 1577,00 0,00 100928,00 64,00 0,44 0,28 0,28 43,60
Average: sde 1578,00 0,00 100992,00 64,00 0,75 0,48 0,47 74,80
Pour corser un peu la comparaison je vais profiter de la partition "2" toujours en RAID-1 (Device Manager) pour la formater en BTRFS et comparer ainsi le RAID-1 BTRFS "pur" et le RAID-1 "DM" + BTRFS. La partition 2 étant un peu moins rapide du fait de sa position DM + BTRFS part avec un petit handicap (#5%).
Les résultats bruts :
RAID-1 BTRFS :
1536000+0 records in
1536000+0 records out
50331648000 bytes (50 GB) copied, 966,6 s, 52,1 MB/s
DM + BTRFS :
1536000+0 records in
1536000+0 records out
50331648000 bytes (50 GB) copied, 993,912 s, 50,6 MB/s
Au vu des chiffres on peut considérer qu'il y a égalité.
Passons à la lecture et afin de vérifier si les deux disques sont bien utilisés on va tester deux configurations :
DD avec l'option "idirect"
DD sans l'option "idirect"
RAID-1 BTRFS avec "idirect" :
dd if=/mnt/DISK1/test of=/dev/null bs=32K conv=fsync iflag=direct
1536000+0 enregistrements lus
1536000+0 enregistrements écrits
50331648000 octets (50 GB) copiés, 489,408 s, 103 MB/s
Sans "idirect" :
dd if=/mnt/DISK1/test of=/dev/null bs=32K conv=fsync
dd: fsync a échoué pour « /dev/null »: Argument invalide
1536000+0 enregistrements lus
1536000+0 enregistrements écrits
50331648000 octets (50 GB) copiés, 430,43 s, 117 MB/s
DM + BTRFS avec "idirect" :
dd if=/mnt/DISK2/test of=/dev/null bs=32K conv=fsync iflag=direct
1536000+0 enregistrements lus
1536000+0 enregistrements écrits
50331648000 octets (50 GB) copiés, 508,961 s, 98,9 MB/s
Sans idirect :
dd if=/mnt/DISK2/test of=/dev/null bs=32K conv=fsync
1536000+0 enregistrements lus
1536000+0 enregistrements écrits
50331648000 octets (50 GB) copiés, 380,004 s, 132 MB/s
Avec l'utilisation de "idirect" les deux possibilités sont à peu près à égalité. Par contre sans ce flag le couple "DM" + BTRFS est très loin devant ...
On refait le test en notant l'activité des différents disques sur une vingtaine de secondes :
RAID1 BTRFS
sar -pd 2 10 | egrep 'sdd|sde' | grep 'Average'
Average: sde 309,50 213753,60 0,00 690,64 9,64 31,16 3,12 96,68
Average: sdd 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00
DM + BTRFS
Average: sde 187,60 140957,60 0,00 751,37 5,77 30,60 3,80 71,28
Average: sdd 163,10 109883,20 0,00 673,72 4,26 26,19 3,96 64,56
On remarque tout de suite que BTRFS n'utilise qu'un disque au cours de ce test alors que DM en utilise deux ce qui explique probablement la meilleure vitesse obtenue.
Remarque : lors d'un deuxième test BTRFS a utilisé l'autre disque il est donc probable que sur plusieurs IO simultanées il est capable de se servir des deux disques.
On vérifie avec deux "dd" en parallèle :
Average: sde 937,40 207295,20 0,00 221,14 28,18 29,98 1,06 99,60
Average: sdd 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00
Et bien non il se sert d'un seul disque ? Et avec deux fichiers différents que va-t-il se passer ?
On copie d'abord une partie de notre fichier de 50G :
RAID1 BTRFS
dd if=test_UN of=test_DX bs=32K count=512000
512000+0 records in
512000+0 records out
16777216000 bytes (17 GB) copied, 376,779 s, 44,5 MB/s
Pendant la copie un seul disque est utilisé en lecture et bien sûr les deux en écriture.
La vitesse est sensiblement moindre que lors des tests d'écriture seule 44,5 contre 52,1.
DM + BTRFS
dd if=test_UN of=test_DX bs=32K count=512000
512000+0 records in
512000+0 records out
16777216000 bytes (17 GB) copied, 339,194 s, 49,5 MB/s
Presque la vitesse en écriture seule 49,5 contre 50,6 ! Pendant la copie les deux disques sont utilisés en lecture et en écriture.
Le test avec deux fichiers
RAID1 BTRFS :
Un seul des deux disques est utilisé et le contrôleur est à 100%, le temps de WAIT est élevé (30 à 45%) le CPU utilisé est de l'ordre de 10% :
Average: sde 202,70 204479,60 0,00 1008,78 23,49 116,10 4,93 100,00
Average: sdd 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00
Fichier 1 ;
512000+0 records in
512000+0 records out
16777216000 bytes (17 GB) copied, 319,734 s, 52,5 MB/s
Fichier 2 :
512000+0 records in
512000+0 records out
16777216000 bytes (17 GB) copied, 260,957 s, 64,3 MB/s
Soit un total d'environ 117Mo/seconde parfaitement égal au test précédent.
DM BTFRS
Les deux disques sont utilisés et les deux contrôleurs à 100%, le temps de WAIT est très élevé (40 à 60%), le cpu utilisé varie de 14 à 28% :
Average: sde 227,85 218987,20 0,00 961,10 13,08 57,72 4,39 100,00
Average: sdd 210,60 215552,00 0,00 1023,51 11,94 56,74 4,74 99,92
Fichier 1 :
512000+0 records in
512000+0 records out
16777216000 bytes (17 GB) copied, 99,329 s, 169 MB/s
Fichier 2 :
512000+0 records in
512000+0 records out
16777216000 bytes (17 GB) copied, 155,029 s, 108 MB/s
Soit un maximum de plus de 270 Mo/seconde ! J'ai refait le test en notant les vitesses moyennes de chaque disque (je rappelle que si les disques sont identiques ce n'est pas le cas des contrôleurs) :
Average: sde 214,20 219289,60 0,00 1023,76 11,50 53,70 4,66 99,78
Average: sdd 191,00 165808,40 0,00 868,11 9,27 48,44 5,02 95,92
Un des disques va nettement plus vite ! Lors de ce second essai j'ai obtenu 150 et 112Mo/seconde soit environ 260Mo/seconde, ce qui est en phase avec le premier essai.
En bref DM + BTRFS ça a l'air de déménager. Ce petit problème réglé je vais remettre la partition 1 en mode "DM".
mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/sdd1 /dev/sde1
On reboote par précaution ... et on lance
mkfs -t btrfs -L BTRFS_1 /dev/md0
WARNING! - Btrfs Btrfs v0.19 IS EXPERIMENTAL
WARNING! - see http://btrfs.wiki.kernel.org before using
fs created label BTRFS_1 on /dev/md0
nodesize 4096 leafsize 4096 sectorsize 4096 size 399.87GB
Btrfs Btrfs v0.19
Et la synchronisation du raid commence :
md0 : active raid1 sdd1[0] sde1[1]
419299136 blocks super 1.2 [2/2] [UU]
[>....................] resync = 0.1% (515264/419299136) finish=67.7min speed=103052K/sec
Ces nouveaux disques de 2To semblent nettement plus rapides que les "anciens" disques de 750 Go (2 and déjà) déja présents dans la machine.
Ne pas oublier ensuite de positionner ce nouveau "raid" dans le fichier "/etc/..../mdadm.conf",
mdadm --examine --scan
est votre ami.
Il est toutefois à noter que j'ai eu quelques plantages système, crash complets sans possibilité de reprendre la main ou "ooops" déclenchant une violation de protection mémoire de "dd" et un crash lors de l'utilisation de "cp -dpR" pour recopier une arborescence complète.
Ces plantages ont eu lieu avec des noyaux < 3.3. Avec un noyau 3.3.5 les plantages ont été moins nombreux, j'ai depuis refait quelques tests avec un noyau 3.4-rc7 pendant lesquels je n'ai noté aucun ennui, les "cp -dpR" ont parfaitement fonctionné malgré les plus de 80Go à recopier (#500 000 répertoires et plus de 2 000 000 fichiers).
J'ai mis pour le moment mon répertoire personnel (que je sauvegarde souvent) sur une partition en RAID1 DM+BTRFS. Les résultats sont pour le moment excellents, l'affichage de photos me semble beaucoup plus rapide qu'avant malgré les 15 à 19Mo de chaque photo.
Un autre test fait sur mon répertoire HOME (maintenant en BTRFS) recopié pour sauvegarde dans une baie externe :
Environ 16 Go avec #5700 répertoires et #57000 fichiers (Pas mal de fichiers photo RAW et JPG de 10 à 15Mo chacun) en un peu moins de 4 minutes soit une vitesse moyenne de # 66Mo/seconde comprenant donc lecture sur BTRFS et écriture sur une partition LVM de la baie.
Ainsi la copie de sauvegarde devient (presque) un plaisir.
Passer en RAID 1
Passer en RAID 1 jppNote : le système est un Debian "Jessie" mais la plupart des remarques peuvent s'appliquer à d'autres distributions.
Sur la machine qui me sert de frontal Internet j'ai eu de multiples alertes "Smart" me signalant des dégradations sur des "seek..." et quelques autres anomalies. Ces disques sont assez anciens et très sollicités car la machine fonctionne 24/24 et héberge plusieurs services : mail, DNS, DHCP, serveur Apache, agent centralisateur de collectd, une base Mysql ainsi que Suricata et Snorby. Les deux disques de cette machine (500Go) deviennent par ailleurs un peu petits. Ils sont montés en LVM, chaque volume LVM est mirroré, mais c'est un peu lourd à gérer. Le système est sur un petit SSD que je sauvegarde régulièrement.
J'ai donc décidé de changer les disques et de mettre deux disques en RAID1 sur lesquels je mettrais trois partitions, dont deux avec LVM, plus un swap. Il ne faut pas oublier de charger le paquet "mdadm" pour disposer des outils adéquats.
Comme le contrôleur supporte 4 disques j'ai pu monter un des futurs disques en plus afin de :
- Le partitionner :
- une partition pour le système,
- une pour les disques des machines virtuelles,
- une pour le stockage des données
- une de swap.
Ensuite :
- Créer le Raid1 avec une seule patte.
- Créer les PV pour LVM sur les partitions 2 et 3
- Charger les données, du système et copier les images de machines virtuelles.
Pour ceci il est nécessaire de stopper le maximum de services afin de ne pas se compliquer la tâche.
Ne pas oublier de mettre les partitions en type "Linux RAID" dans fdisk (type "fd") :
Command (m for help): t
Partition number (1-4, default 4): 1
Partition type (type L to list all types): 21
Changed type of partition 'Linux RAID' to 'Linux RAID'.
... idem pour les autres partitions.
On arrive alors à ceci dans fdisk :
Disk /dev/sdc: 931,5 GiB, 1000204886016 bytes, 1953525168 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: gpt
Disk identifier: 48D952DA-AF21-46D3-BB36-73DFFF32A96A
Device Start End Sectors Size Type
/dev/sdd1 2048 536872959 536870912 256G Linux RAID
/dev/sdd2 536872960 1073743871 536870912 256G Linux RAID
/dev/sdd3 1073743872 1912604671 838860800 400G Linux RAID
/dev/sdd4 1912604672 1953525134 40920463 19,5G Linux RAID
Ensuite il faut créer nos "RAID" en mettant à chacun un disque physique et un disque "missing" :
mdadm --create /dev/md2 --level=1 --raid-disks=2 missing /dev/sdd1
....
Puis enregistrer la config de nos RAID pour qu'ils soient reconnus au boot avec :
mdadm --examine --scan >>/etc/mdadm/mdadm.conf
Vous pouvez ensuite modifier dans ce fichier l'adresse mail de destination des messages.
Il est prudent de redémarrer la machine pour vérifier que nos RAID sont bien accrochés et se retrouvent après redémarrage.
On arrive alors a "voir" l'état de nos RAID en exécutant :
cat /proc/mdstat
Personalities : [raid1]
md3 : active raid1 sdc2[1]
268304384 blocks super 1.2 [2/1] [_U]
bitmap: 1/2 pages [4KB], 65536KB chunk
md4 : active raid1 sdc3[1]
419299328 blocks super 1.2 [2/1] [_U]
bitmap: 1/4 pages [4KB], 65536KB chunk
md5 : active raid1 sdc4[1]
20443840 blocks super 1.2 [2/1] [_U]
md2 : active raid1 sdc1[1]
268304384 blocks super 1.2 [2/1] [_U]
bitmap: 2/2 pages [8KB], 65536KB chunk
unused devices: <none>
-------------------------------------------------------
Le système signale par ailleurs dans les logs lors du démarrage que les RAID ne sont pas en bon état :
Nov 25 13:24:49 xxxxxx systemd-fsck[408]: /dev/md2 : propre, 17129/16769024 fichiers, 10491322/67076096 blocs
Nov 25 13:24:49 xxxxxx systemd-fsck[516]: BOOT : propre, 326/1222992 fichiers, 139566/4882432 blocs
Nov 25 13:24:49 xxxxxx mdadm-raid[196]: Assembling MD array md2...done (degraded [1/2]).
et mdadm-raid vous envoie régulièrement des mails tels que :
This is an automatically generated mail message from mdadm
running on xxxxxx.xxx.xxx
A DegradedArray event had been detected on md device /dev/md/4.
Faithfully yours, etc.
P.S. The /proc/mdstat file currently contains the following:
Personalities : [raid1]
md4 : active raid1 sdc3[1]
419299328 blocks super 1.2 [2/1] [_U]
bitmap: 1/4 pages [4KB], 65536KB chunk
md5 : active raid1 sdc4[1]
20443840 blocks super 1.2 [2/1] [_U]
.......
-------------------------------------------------------
On peut alors :
Formater la première partition en ext4
Recopier les répertoires système du vieux disque, /var, quelques morceaux de /usr ... sur la première partition, "cp -dpRx" est votre ami.
Créer le PV LVM sur la deuxième partition puis créer les volumes logiques destinés à mes machines virtuelles (je ne le fais pas à la main mais avec "kvpm" que j'aime bien).
Stopper les machines virtuelles et copier leurs images disque, bêtement avec :
"dd if=ancien of=nouveau bs=65536" et cela marche très bien.
J'ai ensuite modifié le fichier /etc/fstab" pour monter les "nouvelles" partitions à la place des "anciennes", les anciennes sont toujours là (au cas ou ?).
Modifié les scripts de lancement des MV pour utiliser les nouveaux volumes et redémarré.
Super, tout se passe bien, le système est OK, les MV ont bien démarré et leurs services sont accessibles. Je vais pouvoir démonter les anciens disques.
Je stoppe encore la machine, démonte les anciens disques et je les stocke dans un coin tranquille (encore au cas ou) et monte le nouveau disque encore vierge.
Il fait alors recommencer le partitionnement de ce nouveau disque, sans oublier de mettre le type de partition à "Linux RAID".
Faire gaffe au nom des disques, car le démontage des anciens disques décale tout. On arrive presque à la fin on va, enfin, créer un vrai RAID1 avec deux disques :
mdadm --manage /dev/md2 --add /dev/sdb1
cat /proc/mdstat
Personalities : [raid1]
md3 : active raid1 sdc2[1]
268304384 blocks super 1.2 [2/1] [_U]
bitmap: 1/2 pages [4KB], 65536KB chunk
md4 : active raid1 sdc3[1]
419299328 blocks super 1.2 [2/1] [_U]
bitmap: 1/4 pages [4KB], 65536KB chunk
md5 : active raid1 sdc4[1]
20443840 blocks super 1.2 [2/1] [_U]
md2 : active raid1 sdb1[2] sdc1[1]
268304384 blocks super 1.2 [2/1] [_U]
[>....................] recovery = 0.2% (781056/268304384) finish=28.5min speed=156211K/sec
bitmap: 2/2 pages [8KB], 65536KB chunk
La synchronisation de la première partie du RAID /dev/md2 est commencée et prévue pour un peu moins de 30 minutes, ne pas être pressé et éviter le café car il y a d'autres RAID à compléter.
La vitesse de construction varie un peu mais reste supérieure à 100000K/sec mais la première partition fait 256G, la plus grosse 400G ce qui va durer une éternité.
La première partition contient beaucoup de fichiers "actifs", par exemple tous les logs, la base de données mysql .... cela devrait augmenter le temps de construction. Mais, un peu plus tard : :
md2 : active raid1 sdb1[2] sdc1[1]
268304384 blocks super 1.2 [2/1] [_U]
[================>....] recovery = 84.4% (226534144/268304384) finish=6.7min speed=103609K/sec
bitmap: 2/2 pages [8KB], 65536KB chunk
Ca s'approche de la fin .... toujours à un peu plus de 100MO/seconde. Au passage "iotop" ne voit rien et affiche des chiffres "ridicules".
Nov 25 19:16:52 xxxxxx kernel: [ 939.531841] md: recovery of RAID array md2
Nov 25 19:59:28 xxxxxx kernel: [ 3493.885198] md: md2: recovery done.
43 minutes environ au lieu des #30 annoncées.
Pour la partition suivante il y a deux disques de machines virtuelles, je ne vais pas les stopper avant de commencer la construction du RAID pour environ 30 minutes annoncées.
Nov 25 20:34:04 xxxxxx kernel: [ 5569.372170] md: recovery of RAID array md3
Nov 25 21:24:56 xxxxxx kernel: [ 8618.957262] md: md3: recovery done.
Soit environ 50 minutes.
J'aurais mieux fait de stopper les MV car l'une d'elle a eu un problème lors du redémarrage (fsck manuel obligatoire).
Passons à la partition de 400G.
mdadm --manage /dev/md4 --add /dev/sdb3
mdadm: added /dev/sdb3
date
mercredi 25 novembre 2015, 21:28:55 (UTC+0100)
Et quelques instants plus tard :
cat /proc/mdstat
Personalities : [raid1]
md4 : active raid1 sdb3[2] sdc3[1]
419299328 blocks super 1.2 [2/1] [_U]
[=>...................] recovery = 6.5% (27293696/419299328) finish=95.4min speed=68420K/sec
bitmap: 0/4 pages [0KB], 65536KB chunk
La vitesse n'est "que" de 68Mo/seconde ? On doit approcher le milieu du disque ???
Beaucoup plus tard ... :
cat /proc/mdstat
Personalities : [raid1]
md4 : active raid1 sdb3[2] sdc3[1]
419299328 blocks super 1.2 [2/1] [_U]
[=======>.............] recovery = 36.8% (154667968/419299328) finish=70.2min speed=62746K/sec
bitmap: 0/4 pages [0KB], 65536KB chunk
date
mercredi 25 novembre 2015, 22:05:02 (UTC+0100)
En 37 minutes le temps restant n'a que diminué de 25 minutes .... que dire du résidu de 70 minutes ? Ensuite en 20 minutes le temps restant a diminué de 15 minutes.
A 22:40 ( durée 72 minutes) il reste encore 36 minutes ....
cat /proc/mdstat ; date
Personalities : [raid1]
md4 : active raid1 sdb3[2] sdc3[1]
419299328 blocks super 1.2 [2/1] [_U]
[=================>...] recovery = 89.9% (377065408/419299328) finish=13.5min speed=52082K/sec
bitmap: 0/4 pages [0KB], 65536KB chunk
mercredi 25 novembre 2015, 23:09:29 (UTC+0100)
Les 100 minutes sont atteintes il n'en reste plus que 13,5 mais la vitesse est tombée à 52MO/seconde. Pour finir :
Nov 25 21:28:53 xxxxxx kernel: [ 8856.327974] md: recovery of RAID array md4
Nov 25 23:24:41 xxxxxx kernel: [15800.532184] md: md4: recovery done.
1h56 minutes soit 116 minutes, heureusement que je n'ai pas utilisé des disques de 3To !
La dernière partition (futur SWAP) ne fait que 19G, cela devrait aller vite :
md5 : active raid1 sdb4[2] sdc4[1]
20443840 blocks super 1.2 [2/1] [_U]
[>....................] recovery = 1.5% (311040/20443840) finish=9.7min speed=34560K/sec
Par contre même pas 35MO/seconde ! Cette partie du disque est vraiment moins performante, mais après quelques minutes on monte à environ 45Mo/seconde ce qui est déjà un peu mieux.
Enfin, c'est fini !
La machine est sauvée et n'aura peut-être pas d'incident disques avant quelques années ... je croise les doigts.
SSD et machines virtuelles
SSD et machines virtuelles jppAyant eu l'occasion de me procurer deux SSD de 512Go j'ai rapidement décidé de les utiliser pour fournir l'espace disque à quelques machines virtuelles.
Installation précédente :
- Deux disques Hitachi Deskstar de 3To montés en miroir (DMRAID) avec deux Volume Group LVM.
Nouvelle installation :
- Deux disques Samsung SSD 850 PRO 512GB montés en miroir (DMRAID) avec deux VG LVM.
Les deux nouveaux disques sont utilisés comme support d'un Volume Group LVM dans lequel j'ai pu "tailler" l'espace nécessaire à quelques machine virtuelles et d'un autre dédié à une base Mysql de quelques Go utilisées sur le système hôte et il y reste encore un peu de place.
La différence est très sensible sur les temps de réponse de la base Mysql : de gros "select count(*) from ..." sont passés de plus d'environ deux minutes à une trentaine de secondes, soit approximativement une performance quatre fois meilleure, comme mesuré dans l'article indiqué ci-dessous.
Pour les machines virtuelles la différence est également importante, le serveur Web, sur lequel sont installées ces pages assure un temps de réponse bien meilleur et les statistiques apparaissent bien plus rapidement, décidément Mysql aime les SSD et le montre bien. (Voir article Mysql et SSD). Quand à l'interface d'administration de Drupal il est devenu agréable à utiliser, pratiquement plus d'attente entre les pages.
Une des MV est un serveur de mail Zimbra dont l'interface d'administration fournit des statistiques diverses dont une sur l'usage CPU. Une des statistiques m'a particulièrement intéressé, celle des IOWait qui est très significative. 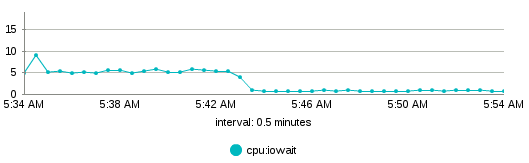
On voit bien la baisse des Cpu_iowait lors du redémarrage de la machine.
Le ressenti de l'interface Webmail est meilleur la réponse plus franche et plus rapide.
En bref : les SSD c'est le pied.
Mysql : SSD / HD
Mysql : SSD / HD jppUn petit graphe des IO pour les deux machines : ![]() SSD
SSD
Encore un test SSD/HDD ? J'ai récemment installé une base volumineuse sur une machine munie de SSD et j'ai constaté que les temps de réponse étaient excellents. Afin de quantifier le phénomène j'ai installé la même base sur deux machines différentes (#90 millions de rangs dans la table principale) :
Machine 1 :
Core I7 6700 à 3.4 Mhz
RAM : 16Go
Base sur une partition dédiée d'un ensemble Raid1 sur HDD classique.
Mysql 5.7.22 Inno_buffers en mémoire classique
Machine 2 :
Core I5 7500 à 3.4 Mhz
Raml : 16Go
Mysql 5.7.22 Inno_buffers en mémoire "huge pages"
Base sur une partition dédiée d'un ensemble Raid1 sur SSD.
Les deux machines sont donc à peu près équivalentes en vitesse au point de vue des CPU puisque Mysql n'utilise qu'un CPU par requête et que le paramétrage de Mysql est identique sur les deux systèmes. Seule différence la machine 2 utilise des "huge pages" pour les buffers InnoDB.
Le premier test consiste à :
- Récupérer dans une table temporaire des rangs présents sur une autre machine par l'intermédiaire d'une table "federated".
- Insérer ces rangs dans une table permanente.
Test 1.
Machine 1 :
Récupérer 206020 rangs 11.48 sec
Insérer dans table "réelle" 69.70 sec
Machine 2 :
Récupérer 212290 rangs 5,42 sec
Insérer dans table "réelle" 11,92 sec
Test 2.
Machine 1 :
Récupérer 2495 rangs 4,76 sec
Insérer dans table "réelle" 1,87 sec
Machine 2 :
Récupérer 2482 rangs 0,32 sec
Insérer dans table "réelle" 0,12 sec
Test 3.
Machine 1 :
Récupérer 2495 rangs 9,66 sec
Insérer dans table "réelle" 57,04 sec
Machine 2 :
Récupérer 2482 rangs 2,22 sec
Insérer dans table "réelle" 7.85 sec
Après quelques autres tests le tableau récapitulatif : ![]()
Au final la base sur SSD effectue les opérations presque 5,7 fois plus rapidement.
Tableau à partir des mêmes données mais en rangs traités par seconde : ![]()
Pour l'insertion le SSD semble moins "bon" mais cette phase comprends la lecture sur la machine origine et le transfert par le réseau qui sont probablement égaux pour les deux machines.
Deuxième test : compter les rangs de la plus grosse table.
Pour ce test :
- On redémarre Mysql pour bien vider les caches
- On exécute deux comptages successifs (# 90 millions de rangs).
Machine 1 :
Premier comptage : 48,36 sec
Comptage suivant : 22,65 sec
Machine 2 :
Premier comptage : 22,07 sec
Comptage suivant : 19,44 sec
Même test le lendemain après ajout de #133000 rangs pour un total de 91176892
Machine 1 :
Premier comptage : 52,24 sec
Comptage suivant : 22,61 sec
Machine 2 :
Premier comptage : 21,91 sec
Comptage suivant : 19,59 sec
La différence est moins importante mais le SSD gagne quand même par plus de 2 à 1 sur le comptage "brut". On constate quand même la bonne efficacité des caches.
iotop montre de la lecture a #30 Mo/sec pour les HDD et > 60Mo/sec pour les SSD.
Le deuxième comptage est visiblement effectué sur les caches (peu ou pas d'IO visibles), la différence d'environ 10% est très probablement due à l'usage des "huge pages" pour le cache InnoDB de la machine 2 (large-pages pour Mysql).
Un petit graphe des IO pour les deux machines : ![]()
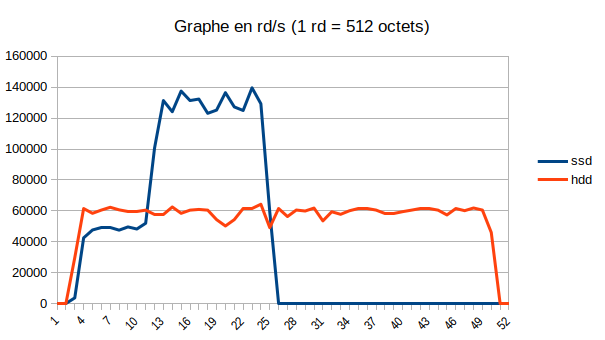
Petite bizarrerie au démarrage pour le SSD qui met #7 secondes pour arriver à son plein régime ?
La même remarque s'applique à plusieurs tests.
On peut voir par ailleurs que les temps de comptage sur la machine SSD sont très peu différents entre le premier comptage (avec accès disque) et le suivant réalisé immédiatement (ne montrant pas d'IO), les disques SSD ne semblent quasiment pas ralentir le traitement (#10% de différence seulement) par rapport au traitement depuis le cache.
Troisième test : créer un nouvel index.
L'index est composé de trois champs.
Machine 1 : 23 min 42,63 sec
Machine 2 : 5 min 29,11 sec
Le rapport de durée est d'environ 4,3.
Pendant l'exécution j'ai vu plus de 240Mo/seconde en lecture sur les SSD contre un peu plus de 60Mo/seconde pour les HDD.
Mysql : SSD or not SSD
Mysql : SSD or not SSD jppAfin de mesurer un peu l'influence des disques sur une base Mysql j'ai effectué quelques petits tests par rapport à une base de référence installée sur des disques « classiques » 7200 tours.
Les test réalisés :
- Sur la machine d'origine (Core I5 à 3.4GHz, disques « classiques »), Mysql 5.6.30
- Sur une autre machine (Corei3 à 3.5GHz, tout SSD) le test est réalisé avec une installation « standard » de Mysql (5.6.30). Donc tout sur le disque système (/var/lib/mysql et /var/log/mysql)
- Toujours sur la machine SSD (5.6.30) avec une installation un peu plus optimisée :
- Logiciel sur le SSD système
- Données sur un SSD « DATA » (/var/lib/mysql)
- Logs sur un autre SSD « LOG » (/var/log/mysql + tmpdir)
- Le dernier test est réalisé sur la configuration « optimisée » avec la version 5.7.16
La base n'est pas énorme et comporte deux tables principales de # 10 millions et #100000 rangs et "tient" dans # 4Go.
Les résultats sont assez parlants, le passage sur SSD apporte une très nette amélioration de performance et pourtant le SSD supportant le système est un "vieux" modèle qui n'est pas au niveau des derniers modèles.
Voir un autre test sur le même sujet.
| N° TEST | 5.6.30 secondes (REF) | 5.6.30 SSD % Gain sur REF | 5.6.30 Opt. % Gain sur REF | 5.7.16 Opt. % Gain sur REF |
| TEST A | 1,00 | 0,00% | 0,00% | 0,00% |
| TEST B | 3,09 | 38,51% | 80,91% | 82,85% |
| TEST C | 1,45 | 61,38% | 74,48% | 74,48% |
| TEST D | 0,93 | 52,69% | 80,65% | 86,02% |
| TEST E | 5,96 | 5,70% | -0,67% | 5,54% |
| TEST F | 41,30 | 21,57% | 57,97% | 65,86% |
| TEST G | 13,68 | 74,12% | 89,40% | 94,88% |
| TEST H | 26,04 | 88,86% | 92,47% | 92,70% |
| TOTAL | 93,45 | 48,26% | 69,06% | 73,93% |
Et en image cela donne :

|
Dernier test : comptage sur une "grosse" table :
Machine SSD :
+-----------+
| count(*) |
+-----------+
| 134071332 |
+-----------+
1 row in set (50,52 sec)
Machine HDD :
+-----------+
| count(*) |
+-----------+
| 134072138 |
+-----------+
1 row in set (4 min 9,46 sec)
Environ 5/1 en faveur du SSD.