COLLECTD : interface web
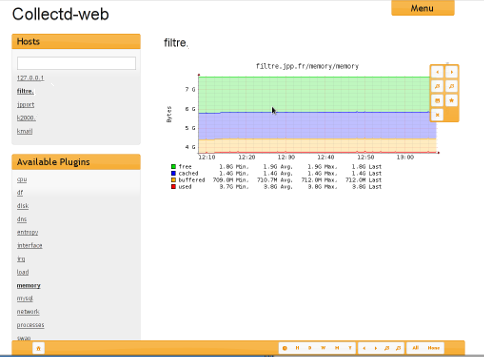
COLLECTD : interface web jppL'interface "collectd-web" permet une consultation aisée des données enregistrées sur votre serveur centralisé. Des gadgets permettent de régler la période de temps affichée, de la décaler dans le temps pour examiner plus précisément une période passée.
Cet interface est simple à installer et assez agréable à utiliser.
Ci dessous un exemple d'affichage :